
Intel Nehalem (i7) Cache
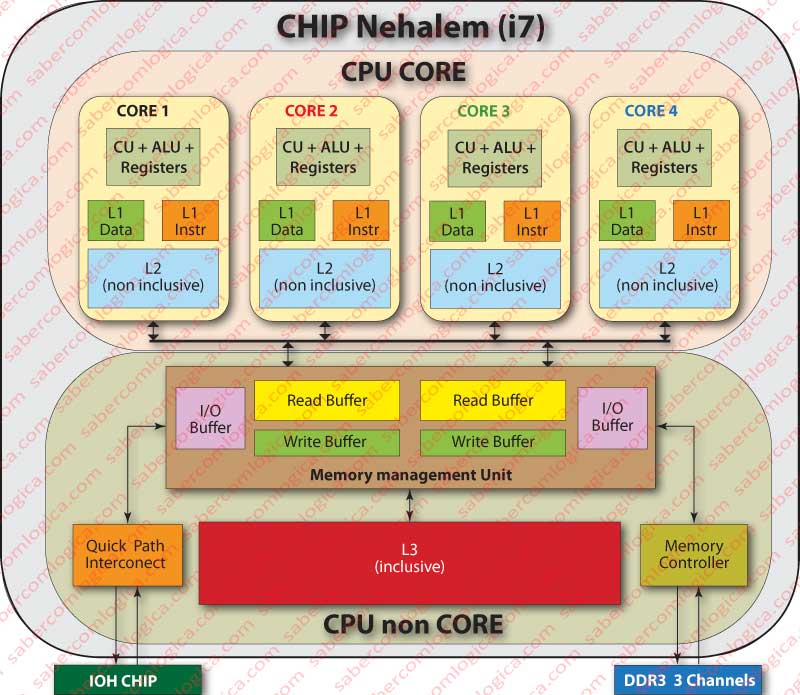
Taking into account all we have been describing, we are now going to analyze the memory organization of the Intel i7 processor, which has the new Nehalem architecture implemented. This is a last generation processor in which, even the smaller details, have been explored on the basis of how the computer science is at this moment, with the purpose of having maximum performance from the processor.
The Intel i7 is a multi-core processor, with 4 or 6 cores inside the same Chip, each with an autonomy equivalent to an isolated processor, while sharing the other resources included on the so called “non-core” area, which is an integral part of the Chip. In our case, we will consider a 4 core Chip.
In this chapter we will touch on the processor memory organization, avoiding the use of more advanced terminology and the approach of complex questions that can only be answered after an analysis of the Operation System.
This processor has 3 levels of cache, designated by L1 (Level 1), L2 and L3. Both L1 and L2 exist individually associated to each processor core. L3 is shared by all the cores, as we can see in the general description graphic of Figure 1.
The cache L1 is divided in two:
- The Instructions L1, a 4 ways associative cache, with 128 blocks per way. The blocks are 64 bytes long each, thus this cache size is 128*4*64=32.768 Bytes or 32 KB. This cache latency is of 3 clock cycles.
- The Data L1, a 8 ways associative cache, with 64 blocks per way. The blocks are 64 bytes long each, thus this cache size is 64*8*64 = 32.768 Bytes or 32 KB. This cache latency is 4 clock cycles.
The cache L2 is a 8 ways instructions and data cache, with 512 blocks per way. he blocks are 64 bytes long, thus this cache size is 512*8*64 = 262.144 Bytes or 256 KB. This is a non-inclusive cache and its latency is 10 clock cycles.
The cache L3 is a 16 ways instructions and data cache shared by all cores, with 8.192 blocks by way. The blocks are 64 bytes long each, thus this cache size is 8.192*16*64 = 8.388.608 Bytes or 8 MB. This is an inclusive cache and its latency is approximately 40 clock cycles. Since it is found on the non-core area of the Chip and because this area has a different clock frequency from the rest of the chip, the clock cycle value has to be an approximation of the real value.
The description we’ve been doing can be followed through Figure 2, where the characteristics of the described elements and links is more detailed.

As cache L3 is inclusive it can respond to block requests from any core having no need to interfere in caches L1 ou L2 of another core containing that block. This a fundamental aspect in a multi-core processor which can not be solved just like this. As this process involves concurrency it will be dealt further on in the Operating Systems Chapter.
But what is an inclusive cache?
A cache is said to be inclusive when all the records of a lower cache level are in it included, i.e. all the records in L2 and L1 have copies kept in L3.
A cache is said to be non-inclusive when the records in an lower cache level are not in the higher level, that is, the records of L1 do not have to be in L2.
The writing policy in any of the cache levels is Write Back.
The Buffers existing between the CPU Control Unit and the L1 cache have the purpose to turn the use of the memory system more efficient by the CPU. With the help of those buffers the i7 can:
- Continue executing instructions (non-conflicting ones) not waiting for data to be written or obtained from the memory or cache.
- The execution of memory operations out of order.
- The predictable fetch for instructions in L1, based in hardware logic.
- Prescribe the logic for the same fetch types in L2, what is done by uploading in L2 data based on the last requests made by L1 to L2.
- Prescribe by prediction (while executing operations out of order) if a certain reading can be done earlier, since it won’t be affected by previous writings.
- And a lot of others.
Between this CPU and the Main Memory (MM), Nehalem introduced several innovations:
- The Memory Controller (MC) is resident within the CPU Chip, thus the communication between CPU and MM is no longer established through the FSB but directly.
- Three communication Channels were established between the MC and the MM.
- Each channel is managed independently by the Nehalem Memory Management Unit (MMU). This means that while in one you can send data, in other you can receive and in other you can update. You can also receive or send in the three channels simultaneously.
Coherence in Cache
Let’s now talk about a very important aspect in the caches, which came up from the present architecture of the multi-core CPU, which allows a distributed multitasking environment in different cores. Multitasking is a programmable execution environment. When a program executes, it divides itself in several non-conflicting but concurrent execution lines. The multitask will be analyzed and better defined when we’ll deal with the Operating Systems. What is important to know is that:
- In this environment, the several tasks execute in parallel, so they do it in different cores of the CPU.
- In this environment can coexist several tasks that share the same resources, i.e. they can access the same information in cache, in different cores.
As we know, the CPU asks the MM for the values it wants. These requests are done to the L1 cache, which represents the memory the CPU wants to access in a transparent way.
Therefore, it can happen that a task changes a value in the L1 cache of the core A, where it is being executed, and then other task reads the same value in the L1 cache of the core B, where this task is being executed. The cache block was already uploaded in both caches before the beginning of these operations.
If this would be possible, the second task would read from the memory a value with which it would do operations, but this value would be different from the one it actually should have.
It can even be worst, because we have a write back policy. When the block is written in memory by each of the cores, a version would overlap the other, making the memory inconsistent, i.e. we could no longer guarantee that the memory data matched the most recent version of that data.
This is cache incoherence. Thus we need to guarantee cache coherence.
For practical reasons, as a result of the way the values are placed and taken from the cache, by blocks (lines), the cache coherence is guaranteed at the Cache data block stage. The block is the Main Memory reading unit.
This conflict in access over the same data and the reduction of the latencies done by their treatment has been under a lot of investigation due to the evolution generated by the increasing presence of multi-core processors. Several protocols were generated to solve the problem and we distinguished one from them to be analyzed.
MESI Protocol
We are now going to analyze how this problem is handled by the MESI (Modified, Exclusive, Shared, Invalid) protocol.
Apart from being one of the most well-known protocols, it is the one used by the Nehalem architecture under which we are now going more in-depth.
For this protocol to be implemented there are more bits in each cache block that allow setting the Block State.
The different possible states for the block are stated in the protocol name with the initials of their names:
- Modified – It is the state of the block that is in cache and has been changed.
- Exclusive – It is the state of the block that is only in one of the CPU cores cache.
- Shared – It is the state of the block that is found in several caches and can be read by any of them.
- Invalid – It is the state of the block whose content does not match the last version in memory.

As we can see in Figure 3, the cache blocks have a set of initial bits, some of those already referred. But we are going to describe them again and say how they contribute to the determination of the blocks state (knowing that we have a write back policy, used in the Nehalem processors):
- Valid bit – it assumes the value of 1 when the block is active, that is, it can be accessed because its values match the current values in the main memory.
- Dirty bit – it assumes the value of 1 when the block is written and therefore changed in any of its Bytes.
- Shared bit – it assumes the value of 1 when the block is in more than one core cache. It can be accessed because its values match the current values in memory.
- LRU bits – they are used by the LRU (Least Recently Used) block substitution protocol. They are 3 in the L1 and L2 (8 ways) and 4 in L3 (16 ways).
- Inclusive bit – in the L3 cache there are extra 4 bits in each block that have, as goal, to identify in which of the core caches the block is included, if it even is. Each bit in each block assumes the value of 1 if it is replicated in the respective core. This can happen because the L3 is inclusive, i.e. all the blocs found in L1 and L2 can also be found in L3.
The LRU bits are placed in the general presentation graphic in Figure 3, but they are not going to be filled up in the cases of coherence analysis, because they have no relation with the cache coherence as well as for their understanding several ways from each cache would have to be presented, what we have no space for.
The remaining bits of the L1 and L2 blocks will represent the several different states in the following way:
- The valid bit low (0) invalidates the block and the meaning of any of the other bits. The block’s state will be Invalid.
- The valid bit high (1) and the remaining bits low (0), represent a block in an Exclusive state.
- The valid bit high (1) and the sharing bit high (1), represent the state of a Shared block. The valid bit high and the modified bit high, represent a block in a Modified state.
Let’s now try to understand how the blocks change states and between what states the changes can be done.
Bus Snooping
Before going forward it’s important to introduce a concept which will be important in order to understand what follows. First it’s important to know that the CPU cores are interconnected by a QPI (Quick Path Interconnect) bus.
As support to the distributed and shared memory situations, which already exist in the big systems that have several processors with individual caches, a technique called Bus Snooping or Bus Sniffing was implemented and now extended to multi-core CPUs.
Bus Snooping is a technology in which all the cache controllers are permanently monitoring the bus (the more correct terminology is sniffing, also used in networks to monitor their traffic).
The snooping use comes from the fact that in these cases, the cache controller besides monitoring it can as well steal, or call to himself, the bus operation. For this reason, each of the core cache controllers can be listening to the bus as well as, depending on what they listen, acquire the bus and send notifications or data through it.
The Nehalem architecture provides its processors with Bus Snooping capabilities.
When the computer starts, all the cache blocks valid bits are placed in an Invalid state, what means that the block doesn’t have the more recent values in memory.
Reading a Block
When an invalid block is read in the L1, we have a cache miss in L1, so L2 is read instead. If the block is found in L2 it’s transferred to L1 with the state indicators it has when this happens. If L2 fetch gives also a cache miss then L3 is fetched and after that the MM.
The Block is Already in L3
In this case, L3 knows if the block is present in someone other core dedicated cache and which one. L3 has this information due to the 4 bits in each of its blocks where it’s registered the presence or not of the block in the several cores caches.
If it doesn’t exist in none of the dedicated caches, he is sent to the L1 of the requesting core in an Exclusive state.
If it exists in any of the other caches, he is sent to the requesting core L1 in a Shared state. If it exists in only one more cache, then it will be in that cache in an Exclusive state and its state in that cache will be changed to Shared.
If it exists in more than one of the caches of the other cores, then its state is already shared, so there is no need to change its state in those caches.
The Block is not in L3 and Must be Read from Memory
We will have a cache line (block) filling, with the registration of a new block in L3 and in L1 or L2 or both. This block is in an Exclusive state, since he will be present in only one of the core caches.
The Block is in the Modified State, in the Dedicated Cache of Another Core
Through Bus Snooping, the core B cache controller, which contains the block requested by the core A in the Modified state, detects that another core is trying to access a memory address contained in that block.
So being it “snoops” the bus for itself, and does an implicit write back of that block, changes its state to Shared and sends it to core A.
The implicit write back happens when the core B immediately transfers the block to the core A, without the update confirmation which is responsibility of the MMU.
The MMU itself is provided with Bus Snooping capability, reason why, when it detects this situation ensures the block update in L3 and MM.
A block in the Shared or Exclusive state can be freely read by any of the cores that have it and no communication is needed, since it has the most recent data.
Writing in a Block Which is in L1 or L2
When a core wants to write data in memory, first it queries the L1. If the block containing the data with that address is in L1 or in L2 then being transferred to L1, two situations can happen:
The Block is in the Exclusive State
In this case the core changes the content of the block and its state to Modified. Nothing else is done since it doesn’t exist in any other dedicated cache and because we are under a write back policy.
The Block is in the Shared State
In this case the core sends a RFO (Request For Ownership) by the bus, assuming the property of the block and changing its state to Modified.
The remaining cache controllers, which are sniffing the bus, listen to the ROF and, if they have the same block in their caches they change its state to Invalid. This way, the next fetch for data within that block gives a cache miss.
This block is now unique in the dedicated caches, reason why any other query done to it by the core that contains it, is done freely.
TheBlock is in the Modified State
If the block is in the dedicated cache of a core in the Modified state, it’s because it only exists in that core. Therefore, the core proceeds to the writing of the intended value and maintains its state.
Writing in a Block Which is not in L1 nor in L2
In this case, the fetch for a write made by Core A in L1 and L2 fails and gives a cache miss.
The Block is, in the Modified State, in the Dedicated Cache of Another Core
Through Bus Snooping, the core B cache controller, which has the block requested by core A in a Modified state, detects that other core is trying to access an area of memory in that block. So being it “snoops” the bus for itself, executes an implicit write back of that block, changes its state to Shared and sends it to core A.
Now the core A will write in that block, change its state to Modified and send that information through the bus. When Core B listens to it, changes the state of that block in its cache to Invalid.
There’s an easy way to do this, with less use of the bus bandwidth.
When the core B detects that the core A wants to write in an area of memory belonging to a block that it has in a Modified state, it sends it to the core A in that state, passing to it the responsibility for the modifications in that block and changing the state of the block in its cache to Invalid.
The core A will then write in a block in a Modified state, situation that we have seen before and that requires no communication.
The Block isn’t in any of the Cores Dedicated Caches
In this case the information of a cache miss is sent through the bus which isn’t snooped isn’t by any other core cache controller, so arriving at the MMU.
We are now dealing with the first access to a block, and that is why the MMU, after gathering it from the L3 or from the MM, sends it to the requesting core L1 in an Exclusive state. Then the requesting core writes the data in the block just received and changes its state to Modified.