
DNS Protocol
Let’s proceed from the point where we were when we made the request.
Once built the HTTP request by the application layer, it will be sent to the layer below, the transport layer.
But there’s yet something missing. The server name www.condominiopartners.pt created for human understanding, it’s not readable by the machine that, as we know, only understands the digits 0 and 1. Imagine that suddenly we have to know each other by the numbers of our identity cards. John was now the 332445626, Antonio the 245617287 and so on. Not readable for us too. So we know each other by our names and we have an identity card number which machines can identify and catalog.
So, what to do now?
Now we have to use the DNS (Domain Name System) protocol to query the name server, which will make the translation of the name written in the hiperlink to an IP address, which will be used later at the network layer, when addressing the message.
The IP address we will use for this chapter shall be the IPv4. The IPv4 is composed by 4 bytes, and is represented by four decimal numbers separated by a dot, being 1 Byte each.
Specifically, to the name www.condominiopartners.pt corresponds the IP address 188.72.202.158 or, 10111100 01001000 11001010 11001010 in binary code, the one the machine understands.
In the present context we only are concerned in knowing how the machine does to discover this relation. In what concerns the IP addresses, the way of addressing and routing, we will analyze in a separate paragraph.
DNS is both a huge Database (DB) spread over a multitude of servers and a protocol that works in the browser and is usually used by HTTP, SMTP and FTP, for example.
Then the browser takes the URL from URN (Uniform Resource Name). So, from the URL
http://www.condominiopartners.pt/index.html takes the URN www.condominiopartners.pt and passes it to the DNS client-side application, which sends a query to DNS server with the URN obtained. The DNS client then receives a reply with the IP address corresponding to the name that was defined by the URN.
Easy, isn’t it?
At least it seems to be. But now comes the question. There are currently about 1.4 billion Internet users.
Where is the machine that has the mapping of all these addresses?
Obviously it would not be possible to have all those addresses focused on a machine.
- The distance for many machines would be enormous.
- The input of that machine would be permanently saturated and waiting times would be enormous.
- Due to the size of the database and the huge traffic over the same query times would also be quite large and its maintenance a huge job.
The solution found was the distribution of the BD in a hierarchical fashion, by a huge number of machines around the world.
So, my local name server begins to contact a root name server, i.e., a server which knows the addresses of the servers who know the Internet Top Level Domains (TLD), such as com, org, edu, gov, net , … , pt, es, fr, de, eu, uk, us, br, etc.
Then we obtain the addresses for TLD (Top Level Domain) name servers for the TLD pt.
And it will be one of those servers, the one which will be contacted, to provide the addresses of authoritative name servers for the name condominiopartners.pt.
Finally, my name server will contact one of those servers, that will give it the IP address of condominiopartners.pt, specifically 188.72.202.158.
The name servers (root, TLD and authoritative), are always many scattered around the world, for reasons of:
- Proximity,
- Load sharing
- Security (replication)
My DNS name server is one local name server and can be very close to where is my browser.
With this multitude of queries between servers, just to get the Ip adress, we will surely have a significant waiting time. Correct?
Correct. But to avoid it, each name server has a DNS cache, where it records the results of queries that it performs for a limited amount of time. This allows an immediate response for identical queries. The local DNS server itself does it, thus replacing the authoritative name servers.
DNS (Domain Name System)
The mapping registrations stored in one name server, the Ressource Records (RR), consist of the following fields described in the table of Figure 1 (above).
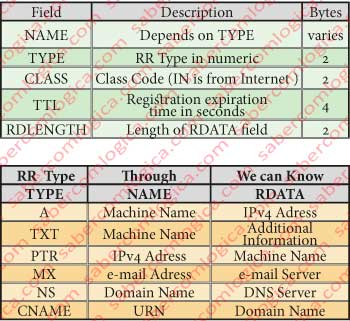
From TYPE value depend the content of NAME and RDATA and consequently what a DNS query to a Ressource Record lets you know, as the table in Figure 1 (below).
- If TYPE = A then NAME is the name of the host and RDATA is the IPv4 address
- If TYPE = NS then the NAME and RDATA is a domain is the name of a server with authority to provide the addresses of hosts in the domain
- If TYPE = MX then NAME is the domain name contained in the e-mail address and RDATA is the name of the mail server for that domain name.
- If TYPE = CNAME then NAME is the name that is looking for and RDATA is the domain name contained in the same
There are other types but we have the main ones.
CLASS for our case is always set to IN means Internet.
TTL is the registration expiration time.
Let’s now see the DNS message rule, which is equal for both the question and the answer, varying some flags and simply filling in some fields (Figure 14-12).

Identification refers to a unique code which allows to correlate the response with the question.
Flags are in the 16 bits that follow identification:
- QR – Query (0) or Response (1)
- OpCode – Operation Code, 4 bits, being e.g. 0 (Standard Query), 1 (Inverse Query) and 2 (Server Status Request).
- AA – authorative answer (response from authoritative server)
- TC – Truncated. It happens when the message is too big and does not fit in intended fields. Is continued by another message.
- RD – Recursion Desired (in question)
- RA – Recursion Available (in response)
- RCODE – Return Code. For example, 0 (no error), 3 (name doesn’t exist)
The query usually uses the hybrid method, i.e., the resulting mixing of theoretical iterative and recursive methods. For here we talk about desired recursion and available recursion, I will make a minimal introduction to these methods.
In the recursive method the client queries name server A, which in turn queries a name server B, and so on until it returns to the name server B, which gives the answer to the name server A, which in turn gives the response to the client.
In the iterative method the client asks the server A, which indicates to the client server B as possibly knowing the name. Then the client queries the server B that indicates to the client server B as possibly knowing the name. And so on until the Client queries the X server that knows the name and gives it the answer.
The hybrid method was the one I described at the beginning of this paragraph.

As an example let’s now see how are the DNS query and response messages that were exchanged in our case study.
Transaction ID: 0x1a53
Flags:
0 = QR: Message is a query
0000 = Opcode: Standard query (0)
0 = AA: No
0 = TC: Message is not truncated
1 = RD: Do query recursively
0 = RA: N/A
000 = Z: reserved (0)
0 = Non-authenticated data OK:
Non-authenticateddata is unacceptable
0 = N/A
0000 = No error
Questions: 1
Answer RRs: 0
Authority RRs: 0
Additional RRs: 0
Queries:
www.condominiopartners.pt: type A, class IN
Name: www.condominiopartners.pt
Type: A (Host address)
Class: IN (0x0001)
and because this case is especially interesting, since it allows seeing in the message how the rules are described and how the name is digitally described, we’ll introduce the binary code for this query in Figure 3(above), under the hexadecimal form, which as we know represents one byte with each two digits and, regarding the name, we can see the meaning of the its binary description in Figure 3(below).
Let’s now see the model of the response message:
Transaction ID: 0x1a53
Flags: 0x8180 (Standard query response, No error)
1 = Response: Message is a response
0000= Opcode: Standard query (0)
0 = Authoritative: Server is not an authority for domain
0 = Truncated: Message is not truncated
1 = Recursion desired: Do query recursively
1 = Recursion available: Server can do recursive queries
0 = Z: reserved (0)
0 = Answer authenticated: Answer/authority portion was not authenticated
0 = N/A
0000 = Reply code: No error (0)
Questions: 1
Answer RRs: 2
Authority RRs: 2
Additional RRs: 0
Queries
www.condominiopartners.pt:type A,class IN
Name: www.condominiopartners.pt
Type: A (Host address)
Class: IN (0x0001)
Answers
www.condominiopartners.pt: type CNAME,class IN cname condominiopartners.pt
Name: www.condominiopartners.pt
Type: CNAME (Canonical name for an alias)
Class: IN (0x0001)
Time to live: 4 hours
Data length: 2
Primary name: condominiopartners.pt
condominiopartners.pt: type A, class IN, addr 188.72.202.158
Name: condominiopartners.pt
Type: A (Host address)
Class: IN (0x0001)
Time to live: 4 hours
Data length: 4
Addr: 188.72.202.158
Authoritative nameservers
condominiopartners.pt: type NS, class IN, ns ns4.ptwebserver.com
Name: condominiopartners.pt
Type: NS (Authoritative name server)
Class: IN (0x0001)
Time to live: 17 hours, 42 minutes, 13 seconds
Data length: 21
Name server: ns4.ptwebserver.com
condominiopartners.pt: type NS, class IN, ns ns3.ptwebserver.com
Name: condominiopartners.pt
Type: NS (Authoritative name server)
Class: IN (0x0001)
Time to live: 17 hours, 42 minutes, 13 seconds
Data length: 6
Name server: ns3.ptwebserver.com
leaving the interpretation of this message with you, by comparison with what we have done till now.
Cookies
Cookies are an element that can be part of the HTTP header, widely used by sites that want to know the history and general habits of their customers on visits to their sites, recognize them as a registered customer and others.
The cookie service has 4 key elements:
- A line in the HTTP response header
- A line in the HTTP request header
- A cookie DB managed by Browser
- A database on the server properly managed.
The cookie service is created when accessing for the first time a site using cookies, such as a electronic sales service, for example. That site response message includes a line like this in HTTP header:
Set-Cookie: 234879
Our browser will then add this code to the cookie DB relating it to the Site.
From here on, each time we access this Site the Browser checks whether exists any cookie in cookies DB related to the query name, before building the HTTP packet. Once confirmed it inserts this line in the header
Cookie: 234879
The Sites of these large companies have a kind of Database, known as Data Wharehouses, which are fed by data collected on any activities on its existing site, such as all the clicks anyone anywhere in the world does in a hiperlink that leads to this Site, as well as the Database records no longer needed for current management (called history), over whom are performed queries carried out by highly elaborated programs that run regularly the archives build with all this information, creating other records organized in a completely different manner, now turned to the management of the company.
This translation process is called DataMining. It is through DataMining that are developed the highly performing programs for management information services, having as purpose the sustainable decision support. Let’s go on.
In the event that subsequently you make your registration on one of these sites, also your personal information is associated.
Didn’t it ever happen to you, upon arriving in one of these Sites, even before logging in, be dealt with by your name. And still it’s not yet witchcraft. It’s cookies doing their job.
It’s also due to cookies that in a site it is possible to go on purchasing and constituting an electronic shopping cart that is only paid at the end. The cookies allow the server to retain the state of the user in a specific archive.
The cookies also have raised many discussions about the intrusion into privacy that they represent. But those are ethical questions that are not the purpose of this work.
The cookies are also used in the transport layer with the name of SYN cookies, preventing computer attacks used to turn inaccessible one site service. Precisely because they are used in the transport layer, we will refer to them only there, so they can be perceived.
Proxy Server
The proxy server is basically a Web Cache, a server that sits between the browser and the outside.
Thus, any request that starts in the browser first passes through the proxy server, being the communication with the outside its responsibility.
For each response received, the proxy server will enrich its cache with the preferences of those who use it, in such a way that briefly, only a far smaller percentage of requests is not satisfied by the proxy server.
The proxy server is typically used in corporate networks, buildings, campuses, etc.
The proxy server also allows, if people so wish, act as a powerful Firewall and even as a selector of the type of content of the pages that are requested.
And how does the proxy know that the information it has cached is not outdated?
From some time in cache (very little), when a request arrives to the proxy, since it is stored with the element that has cached the date of the last site update, sent to him as one of the lines header
Last-Modified: Wed, 22 Jul 2011 10:20:32
the proxy server does a query to that site with a conditional GET, which includes the header line
If-modified-since: Wed, 22 Jul 2011 10:20:32
or gets new information on the Site or simple short message in which the first line says
HTTP/1.1 304 Not Modified
304 being the state and the text its short meaning.
Conclusion
Now we have the IP address for our server, we can send the packet with the HTTP query to the layer below, i.e., the transport layer