
HDD Logical Organization
What we have seen so far about the large persistent computer memory, the HDD (Hard Disk Drive), was its mechanical operation, the physical way how it keeps the information delivered to it for preservation and how it references its location.
We recall the CHS (Cylinder, Head, Sector), precisely the system used by the HDD to refer to the locations where it keeps data, in which the sector is the minimum amount that can be read or written in the HDD.
We’ve also seen how the density of information contained in the HDD increased, how the number of sectors per track was made variable as the tracks move away from the center, how the sequential placement of data is done in HDD interchangeably so that the change of sector does not oblige it to expect a revolution of the plate to continue reading or writing, and so on.
All these developments allow us to have a huge amount of mass storage in a small plate, but organized in such a way that only the HDD controller can handle with it. These controllers are the secret of the success of many manufacturers, with a huge logic complexity, resulting from the continued investigation of thousands of engineers.
How do we deal with that data when we need access to HDD? Do we have to refer to each data CHS and how it’s stowed in order to get access to it? Do we have to refer to all the sectors where a given set of data we need is stored? And how do we know in which sectors the HDD controller kept them?
It’s obvious the answer to all these questions: we don’t know how to deal with a HDD at this level. We can’t imagine a developer telling in his program the places where to get or put the data he needs for his program.
Here is where the OS (Operating Systems) came to help us, creating an abstraction which represents each type of data set that we deal with, which is the File.
File
The File is the abstraction between the humans and the HDD. The File consists of a set of data (bits) which give shape to something that means something for us, such as:
A program, a movie, a song, a photograph, a text, a database, this book, that little program that we did in Assembly CPU, the programs we work with, and so on.
Everything we register into a HDD is under the shape of a File. Thus, the great persistent memory of the computer is composed by Files which can contain the basis of our computer operation or a simple data storage. Files whose size can go from some few bytes to hundreds of Gigabytes.
Therefore, all the information we deal with is contained in Files which the HDD keeps in Sectors spread through it in the way its controller tells it to do. We talk with the HDD in Files, which are what we understand and as logical mean for us. The HDD controller transforms them into data referred by CHS which only it knows.
But for this to happen lots of logic are in the middle and the purpose of this chapter is its analysis
Cluster
The Cluster is one more logical abstraction that we humans created for the HDD in order to deal with it. The Cluster is a block of data composed by a specified number of sectors, from 1 to 64.
But if we already had the sectors, a physical unit grouping lots of bytes, why creating another logic unit grouping sectors?
To understand this it’s important to refer that each Cluster can only contain one File or a part of it. In other words, a File can be spread through many Clusters but a Cluster can only contain one File.
One File, even if it has only 1 byte in size, it takes one all Cluster for it.
Now it’s easier to understand the reason for the cluster. We intend to associate a specific amount of space in the HDD with each file. But that amount of space must be constant for the same HDD, between 1 and 64 sectors. How is it specified?
As a file can have any size, the cluster size as to be set so that for several conditions we can get the best relation between the space really taken by the files and the space taken by the clusters that contain them.
This difference is named Slack, which is the space occupied by the clusters but not used by the files, i.e. the sum of the space inside the clusters not used by the files.
Let’s do it with a concrete example: If in a given HDD the prevalent size of the files is of 1KB and the clusters were set as containing 8 sectors, thus with a size of 4 KB, we’ll have a mean slack of 3KB per cluster, i.e. in a HDD of 40 GB only 10 GB will actually be containing data. For a situation like this the cluster should have been set for 2 sectors. Their size would be of 1KB and the slack would be minimum.
So, the clusters must have the size which causes the less slack in a HDD. According to the type of files which are going to be kept in a given HDD, if we can define a type, we must find to that HDD the best relation for the least slack.
The cluster size for a HDD is fixed and unique, i.e. the same for all the HDD. But we can make different cluster sizes to different HDD which are going to keep different types of files.
For that to be possible we don’t even need to have different physical HDD units as in a same physical HDD we can create several volumes corresponding to as much partitions of the same physical unit, as we’ll see further on.
It’s time to see how an OS organizes the files into a HDD. To that organization we call the File Systems. But before, let’s see how it addresses them.
LBA (Logical Block Addressing)
Now we know that the OS created an abstraction, the file, which represents for us the several shapes of information sets we deal with and need to access in a HDD. But for the HDD that thing whose name is files, are transparent for it. They just don’t exist.
For the HDD controller there’s only Sectors organized in tracks in the plates. The plates are represented by the Heads and the tracks together in the same vertical alignment make a Cylinder. And its in those sectors that the HDD controller is going to put or read the data which composes the files in a way that only it knows and which will certainly be the most efficient for it.
So, we work with files and the HDD works with CHS (Cylinder, Head, Sector) geometry.
To turn things a little more difficult, the OS which created the file abstraction for us, don’t understand CHS.
Initially, when the OS wanted to communicate with the HDD it did it through the BIOS, which established the dialog with the HDD in CHS.
As the size of the HDD went up the BIOS went down in its function of communication between the OS and the HDD. To sustain the compatibility with older machines, extensions were made to the BIOS in order to maintain it as the communicator between the OS and the HDD.
With the arise of the Bit Zoning (differentiation in zones from the center to the border of the plates in what concerns the density of sectors per track), the CHS addressing became a privilege of the HDD controller. The CHS geometry became exclusive and different for each manufacturer, what made impossible for the BIOS to accomplish its task.
To solve this problem another logical abstraction conceived by the HDD manufacturers arose.
It’s the LBA (Logical Block Addressing) which allowed the HDD manufacturers to communicate their addressing places without having to refer their CHS geometry, so surpassing the limitation that the BIOS was imposing to their growth.
The BIOS was yet for some time the communicator between the OS and the HDD. Extensions in the number of bits it used to represent the CHS geometry, the extended BIOS, was created for it. It learned to translate from CHS to LBA and vice-versa. It was with an imaginary CHS geometry which it addressed with the OS and it was in LBA that it addressed the HDD controller, which in turn converted it in its real CHS geometry.
But what really is LBA?
The LBA consists in the translation of the CHS geometry into a sequential sector (Blocks) numbering.
For instance the LBA 0 corresponds to CHS 0.0.1, the LBA 1 to CHS 0.0.2 and the LBA 1,935,520,065 to CHS 121,601.255.63 as it happens with a 1 TB size HDD.
Now the LBA is the dominant way of addressing and is dealt directly by the OS with the HDD controllers, referring the respective number of the Block, having as limit the OS addressing capacity in bits. A 32 bits OS can address 4,294,967,296 blocks. Each block having 512 Bytes the maximum size that is addressable by a 32 bits OS is one with 2,199,023,255,552 bytes, i.e. the 2 TB size of HDD.
This is the addressing limit for a 32 bit OS. But HDD with higher capacity can be built. The successive increase of bit density per square inch and the number of plates a HDD can have allows bigger sizes.
The extension of the sector value to the most current value of the cluster (4KB) is one of the possible solutions to increase the LBA addressing ability of a 32 bit OS.
File Systems
We are not surely going to address the files calling for them at the HDD entrance or addressing them in LBA.
What we know is that we need a file to work with or that we have a set of information that we want to save as a file. And nothing more. When this happens we ask the OS to deal with our wish. And it does.
The File Systems are the way each OS has to organize the files into the HDD. And not only that. Nowadays a file system must organize the files, ensure the security in the access restriction that must be imposed to each file and ensure the file system consistency, even in case of disaster. Some few words for a multitude of work. This is what we’ll try to show how it’s done, within reasonable limits and into a goal that we’ll set.
There are many file systems from which we want to highlight 3:
The FAT (File Allocation Table), which started with the version FAT 8, after that the FAT 12, then FAT 16, then FAT 32 and finally the extFAT (extended FAT). The number following the word FAT symbolizes the amount of bits available for each element of the allocation table. This was the file system adopted by Microsoft for its MS-DOS, the first OS sold separately from the machine and developed specifically for the IBM PC (Personal Computer) or all those who were IBM PC compatibles. Maybe that’s the reason why it is the most well-known for all those nonprofessional curious which from there could start exploring their creative abilities for informatics, some of them becoming true professionals and even investigators.
With the growth of HDD sizes, the FAT file system became extremely heavy and inadequate:
- Or the allocation tables were so big that its efficiency was severely reduced, as we’ll see further on;
- Or the clusters assumed huge dimensions, resulting in the loss of effective space in the HDD due to slack.
This way it was necessary to find another file system adequate to the new reality.
The NTFS (New Technology File System) was developed by Microsoft for its first OS dedicated to servers – the Windows NT – and soon became the file system adopted by the Windows OS for PC, starting with Windows XP. The NTFS was developed thinking in Personal Computers operating in Networks, needing to create different types of restrictions for different types of files. That’s why it has security settings that allow conditional file by file, which was of the utmost importance to the operation of networks in which multiple users could access all stored files. It can keep a lot more information about each file, having a journaling system which allows it to recover from system crashes preserving the file system consistency. Its organizational structure allows it to be not sensible to the growth of the HDD.
It’s when the FAT began its decline by inefficiency that Microsoft extended the NTFS to all the NT family, including the OS to PC, beginning with Windows XP and being at its maximum performance with the current Windows, including the new Windows 10. Its successor, the ReFS (Resilient File System) is not yet ready for the great adventures in the world of OS to PC.
The EXT (Extended File System), it’s the file system developed for Linux OS. The ext version was replaced by the ext2 version and has suffered upgrades till the current version ext4. The ext was inspired and started from the bases of the UFS, the file system for the UNIX OS. It has strong parameters for files access control and it has journaling since the ext3 version.
The NTFS importance is directly proportional to the weight that Microsoft Operating Systems detain in the Personal Computers segment, reason why our analysis will be focused essentially in this file system. We’ll do a little approach to FAT too at the end of the Chapter.
Hexadecimal Editor
Why a new reference to the hexadecimal numeral system now and here?
Each hexadecimal digit represents 4 binary digits, thus 2 hexadecimal digits represent 1 Byte or 8 binary digits (bits). The reason why we introduced the hexadecimal system in a given chapter of our work, had to do with this. When we evolve in informatics concepts all the addresses in memory, positions in HDD, byte reading and so on, this is done in hexadecimal representation.
Why being so?
Because this way we get things a lot clear for us:
- The bytes are always represented by 2 digits.
- The 512 Bytes of each sector can be represented in the shape of a table of 32×16 Bytes. The 16 columns are for all the hexadecimal digits (0 to F), so becoming easy to identify each Byte position. We can see this type of organization in the representation of a HDD sector in figure 1.
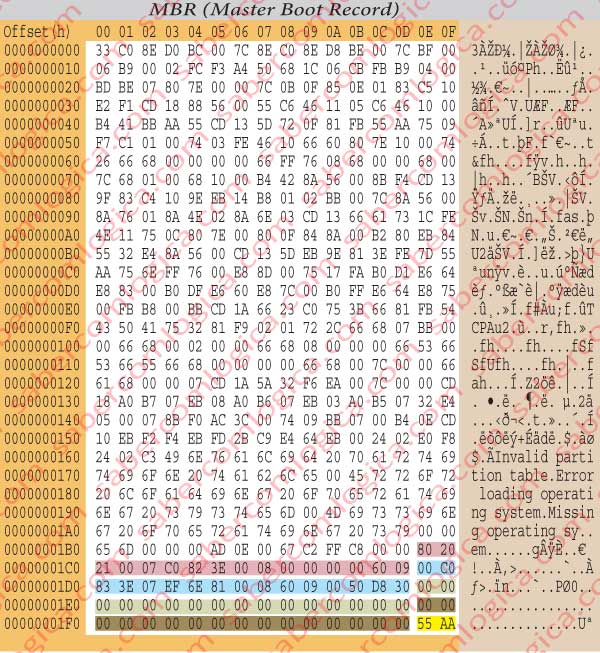
Each one of those columns represents the offset of the Byte position by relation to the position shown in the left column. This way, if in one given row at the beginning we have for instance the value 0010h and the byte we’re interested in is in the column C, thus with the offset Ch, it will be the byte in the position 0010h + Ch = 001Ch.
We can verify how easy it is the conversion of a hexadecimal into a binary. For instance the 2 digits 72h are converted one by one 7h = 0111 and 2h = 0010 resulting 72h = 01110010 = 114 (decimal) or 72h = 7 x 16 + 2 = 112 + 2 = 114 (decimal)
Observation: When we use the letter h in front of any set of digits from 0 to F, it means that that number (if as a number it can be interpreted by a numeral system, as is the previous case) it’s a hexadecimal number.
We’ve referred to offset as the displacement of a Byte inside 16 possible columns (0 to F) in a table of 32 rows.
But Offset can have other meanings when applied globally, referring in this case the displacement of the Byte by reference to the beginning of the HDD, if it’s to an absolute displacement that we are referring to, or by reference to any given position, if it’s to a relative displacement that we are referring to.
The table in figure 2 intends to illustrate these questions about offset and is withdrawn from figure 1.
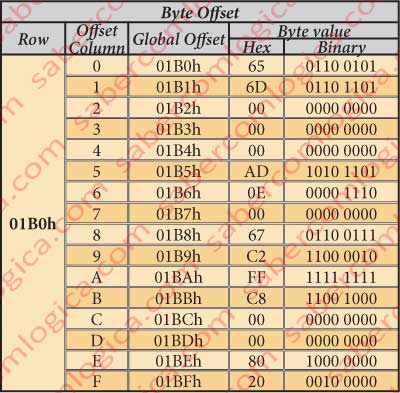
It’s very important that this question of the offset stays clear for us, because the word offset will be our frequent companion for this Chapter.
A deep look into figure 1 will give us a better perspective of how a hexadecimal editor works when representing the content of a HDD.
The HDD is represented in the format of lines with 16 columns each. In the intersection of each row with each column there will be 2 digits. Those 2 digits are the hexadecimal representation of the Byte value in that position.
In the left column is represented the line offset (h) related to the HDD beginning. In the upper line is represented the offset (h) related to the beginning of each row, of the represented Byte. In figure 2 we represent each byte of a given row (the 01B0h) referred by its column offset, the corresponding global position and its value.
In the far right column of the hexadecimal HDD editor we can see the interpretation in ASCII extended code (8 bits) of each one of the Bytes in the row. In some cases it makes sense, as the Bytes value represents text. In the remaining cases it doesn’t make any sense. But it’s good when we search for some kind of message inside a file.
We’ve already referred to Partitions (?) but we don’t yet know its meaning. When we format a HDD… Format? But we don’t yet know what that means too. Well, let’s go slowly, step by step. Let’s start by formatting.
Formatting
Formatting a HDD is, as the name implies, give it inner form, or rather, structure it internally so that the data can be read and written in the allowed locations.
There are two essential formatting levels:
- The lower level formatting, consisting of:
- Teaching the HD geometry to the disk controller, i.e. its bit zoning, the number of sectors per track in each zone, the number of tracks in each zone, the total number of tracks and therefore of cylinders, the total number of sectors and the number of heads.
- Put on disk the necessary information so that at every moment the heads can know where they are, i.e., signal the beginning of each sector and its identification.
- Place guidance elements for the heads in its motion for a requested track search. As the actuator movement is linear, identification bits scattered throughout the tracks with their identification are laid as a way to help the actuator to more easily position itself properly. If we remember that the differences of temperature supported by a HDD causes dilatation and consequent changes in the physical position of the tracks, we understand how required this information is.
The low level formatting, due to its enormous complexity, in the current HDD is already done at the factory.
- The high level formatting consists of placing on disk the information how it is organized.The number of partitions it has, where they begin and where they end, the code elements needed to boot the computer, the chosen file system identification, the location of the elements that each one has to identify the data to save on disk. This is the formatting that we do each time we execute a formatting operation over a HDD in our computer.
Partitions
The partition of a HDD is one of the first tasks we execute during a high level formatting
It consists in dividing the HDD into several pieces or partitions. Each partition will then be called a Volume, what in logical terms represents an independent HDD. And that’s what the user sees. If we create two partitions we will have two Volumes with two different letters, as the C: and the D:.
Even if we don’t want to create any partitions in the HDD, when formatting one unique partition or Volume will always be created, which is shown to the user as being one only HDD, for instance the C:, which in reality is a Volume inside the HDD.
The HDD has a boot sector, the first one, the MBR in our case (there’s others but for now it doesn’t matter), independent of the OS. The partition has another boot sector, the PBS, the first one too, created by the OS installed in that partition.
When we are dealing with one only volume in the HDD, we are not using the HDD but the volume inside it. Each physical unit (HDD) accepts a maximum of 4 primary partitions, for reasins that have to do with the size of the partitions table inside the MBR.
If we want to create more than 4 partitions then one of the referred 4 must be converted from primary to extended partition, inside which we can create as many logical partitions as we want.
The extended partition, as its name suggests, extends the partition table to outside the space which is reserved for it by keeping inside it a pointer to the place where that extended table is.
The main difference between the primary and logical partitions is that only in a primary partition we can create a bootable Volume, i.e. a Volume from which the system can boot.
To a bootable partition we call active partition and we must always remember to define one of the partitions we create as active, otherwise being enable to boot the computer.
Let’s follow with the analysis of the main elements which allow the system boot and the files localization. To better understand it we will use representations of the hexadecimal editor taken from a HDD with 500 Gb and 2 primary partitions, the first one being the active and bootable.
But before we must understand how the bytes can be read inside a word.
Endianness
Endianness, in computing science refers to the order of the individually addressable parts while integrating a bigger unit.
The individual addressable parts are the Bytes and the bigger units are sets of bytes which will only make sense when interpreted together. Endianness as to do with the order of the Bytes in those groups. The difference resides in which is the first byte in the order.
- If the lowest order byte in the set is the first, coming the others sequentially in increasing order until the last, the highest order byte, then we are facing a little endian CPU.
- If the highest order byte in the set is the first, coming the others sequentially in increasing order until the last, the lowest order byte, then we are facing a big endian CPU.
Let’s look into a practical situation in order to better understand this sounding name of “Endianness”. For it we’ll use the meaningful set of bytes going from the offset 01DAh until the offset 01DDh from Figure 1, representing the total number of Sectors of the 2nd partition, i.e. 819.482.624 Sectors, what in binary hexadecimal representation is done with the set of the 4 bytes 30 D8 50 00.
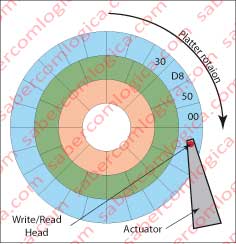
The Intel CPU are little endian, i.e they write the meaningful sets of bytes in the HDD starting with the lowest order one in the set and sequentially in increasing order until the highest order one. So being, looking to Figure 3 we can realize the way they are recorded in the platter after going through the HDD writing head, which is 00 50 D8 30.
The hexadecimal editor shows the bytes by the order they are individually read from the HDD, as it ignores any meaning of any set or even its existence – to it they are simple bytes. Knowing this let’s follow the path of the reading head over the HDD platter, see which is the first one to be read, the reading sequence and the last one to be read. Now tell me if what was read is or is not represented by the set 00 50 D8 30 which we can found from the offset 01DAh until the offset 01DDh of Figure 1?
Yes it is, and its written in reverse order, because:
- the 1st to be read, the 1st being written and the lowest order one (00), will be represented in the highest order (00),
- the 2nd to be read, the 2nd being written and the 2nd order one (50), will be represented in the 3rd order (50),
- the 3rd to be read, the 3rd being written and the 3rd order one (D8), will be represented in the 2nd order (D8),
- the last to be read, the last being written and the highest order one (30), will be represented in the lowest order(30).
Thus, when the meaningful sets of bytes are written by a little endian CPU, when being read they must be interpreted in the reverse order by which the individual bytes are read, i.e. when 00 50 D8 30 is read it must be interpreted as 30 D8 50 00. And here we have the intended value of 819.482.624 sectors.
MBR (Master Boot Record)
MBR (Master Boot Record) it’s the first sector of any HDD. It contains all the necessary information for the system boot.
MBR is created in the HDD, out of any partition and thus independent of the chosen Operating System and its file system. It’s the MBR sector which contains the partitions table.
We’ll analyze the content of the MBR, following with figure 1. From the offset 0000h until the offset 01BDh it’s the MBR boot code. From the offset 01BEh until the offset 01FDh it’s the partitions table, a 64 Bytes space where we can verify the definition for 4 partitions each definition composed by 16 Bytes highlighted with colors, the first, the second, the third and the fourth primary partitions. In the 2 final bytes of this sector highlighted in yellow is the MBR sector boot signature.
Now it’s important to understand how the boot of a computer happens.
The Computer Boot
When we power on a computer its CPU will initiate its cycle of fetch, decode and execute. But, as in PC (program Counter) or instructions pointer there’s yet nothing, the CPU will remain in an infinite cycle pointing to itself.
This is the computer. While we don’t teach it to do something it does nothing.
We have for several times referred to the BIOS. It’s precisely the BIOS the responsible for the computer BOOT, containing the necessary programs to do it.
But, if the CPU does nothing how is it going to find the BIOS?
Well, it’s time to see how it does.
When we turn on the computer, the CPU sets in the PC (program Counter) the address base of the ROM BIOS, accorded between the CPU and the BIOS manufacturers. This way the programs contained into the BIOS are launched. The BIOS executes the POST verifying the conformity of the main peripherals, executes the SETUP and loads into memory the code in the MBR, launching its execution.
This code, when in execution searches for the partitions table, verifies that there is an active and bootable one. Finally it verifies the boot signature in the last 2 bytes of the MBR which must be 55 AA, otherwise the boot process will be canceled. If all is correct with the boot signature, the MBR boot code will load into the memory the bootable partition (the first one in our case) boot sector code and launch it. When running, this code will look for the executable which launches the OS installed in that partition and executes it.
If this process would be running into your computer, at this moment you should be prepared to operate your computer under your Operating System.
Partitions Table
Analyzing the partition table we can verify that there are only 2 partitions in this HDD, as the definition bytes for the other 2 are all set to zero.
But, to better understand the boot process let’s now see what the boot code reads in each partition definition bytes, as described in figure 12-3.
We will analyze the 1st partition, from offset 01BEh to offset 01CDh.
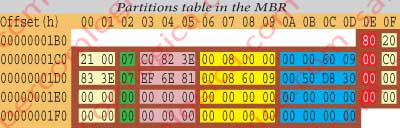
So, for the 1st partition we have:
The byte in 01BEh it’s the Boot designator (80 if it’s bootable). This way we can verify that the 1st partition is bootable and the 2nd one isn’t.
The Bytes from 01BFh to 01C1h refer the CHS [Cylinder (10 bits), Head (8 bits), Sector (6 bits)] where the partition begins. They are ignored due to the HDD size.
The byte 01C2h is the file system identifier. Its value is 07 for primary or logical NTFS partitions and 06 for extended partitions.
The Bytes from 01C3h to 01C5h refer to the partition termination CHS. They are ignored due to the HDD size.
The bytes from 01C6h to 01C9h represent the Relative Sector value described in LBA (Logical Bloc Address). It’s the offset in sectors from each partition 1st sector from the beginning of the HDD. Its value is for our study case – Offset in sectors – 00 00 08 00 = 2.048 / Starting Offset – 2.048 x 512 = 1,048,576 = 100000h.
The bytes from 01CAh to 01CDh represent the partition total number of sectors. We recall that our CPU is a little endian. So, to know its value in decimal we have to invert the bytes hexadecimal representation order, what means: Total sectors – 09 60 00 00 = 157.286.400
Summarizing: The 1st partition has 2.048 sectors before its beginning, contains 157.286.400 sectors and starts at the offset 100000h. It’s in this offset that the system boot will proceed, now under the domain of the Operating System.
Using the same method we can conclude regarding the 2nd partition that: Offset in sectors – 09 60 08 00 – 157,288,448 – Starting Offset – 157,288,448 x 512 = 80,531,685,376 or 12C0100000h – Total sectors – 30 D8 50 00 – 819,482,624. Thus the 2nd partition has 157,288,448 sectors before it starts, its size is of 819,482,624 sectors and starts at the offset 12C0100000h.
From now on the computer is delivered to the Operating System, present in the bootable partition, the Windows. Thus the organization of the HDD is going to be delivered to its File System, the NTFS. And we are going to the offset 12C0100000h, where the 2nd partition starts, to fulfill the purpose that we’ll define there which will take us through the understanding of a Fiule System, namely the NTFS.