
NTFS – File Attributes
This analysis will be supported in the hexadecimal editor images of several Metadata Files of the Volume we are analyzing. We’ll refer those images along the exposition always presenting locally the detail of the part of file in analysis.
Those Metadata Files will be described further on, how we can find them, how we can read them and how they can help us to achieve our purpose.
But before that we’ll have to define the file attributes, their shape and how they can be read. The Metadata Files themselves, besides having a descriptor (as files that they are) analyzed according to what we’ve described, also have their own attributes which define them as files.
Therefore, in order to analyze them we need to know how and that’s the reason why we’ll start with the attributes.
The File Attributes are, as their name suggests, the attributes which characterize each file. It’s through them that we’ll find the path to it, that we’ll define their security, that we’ll ensure its consistency, in short, that the NTFS defines all what matters to a file in what concerns it.
Actually, the organization of this work in this chapter is really complex. We have to start by the analysis of a list of Attributes which we’ll set in the table of figure 12-9 and we have to believe that those are the ones we are interested in.
And how can we get to that conclusion?
Precisely through the analysis of one of the metadata files and through one of its attributes.
For now we have to be blind believers.
When we’ll analyze the $AttrDef file, the one which defines the attributes, we’ll understand it all. Until there we’ll have to be patient.
The attributes are divided into 4 different categories as they are or not resident and as they have or not name.
Resident or not resident designates if the data of the attribute is included into its description in the MFT or somewhere else out of the MFT properly indexed.
Having or not name must not be confused with the name of the attribute, which all they have as we’ve just designate in their list, but if the attribute as a given name, as any normal file does.
The Attributes themselves also are files and so, they will have a header or descriptor and a body.
The Attribute’s headers are different according to the classification we’ve just finished to give them.
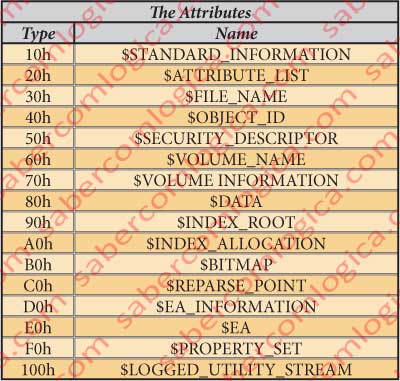
We are going to make the Attributes description according to their order in the hexadecimal editor image for the $AttrDef file, in figure 12-23, beginning by the type header description always a new category is shown.
According to what we can read in the file descriptor the first attribute of the file $AtrDef begins at the offset 4030h. It’s a $STANDARD_INFORMATION attribute (just believe it is), a resident and without name attribute as we’ll see, represented in blue shadowed in the referred figure.
Resident and no Named Attributes
Header Type for Resident Attributes Without Name
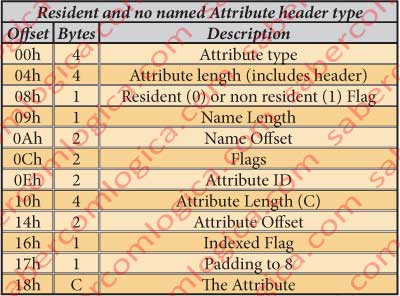
In the table in figure 10 we put the different fields of this header, their size in bytes and their offset. We must read this table in comparison with the same fields in the hexadecimal editor representation for the file in analysis in figure 11.
The 4 bytes from 4030h to 4033h represent the type of the Attribute. In our case 10h, which identifies the attribute $STANDARD_INFORMATION, as we can see in the attributes table.
The 4 bytes from 4034h to 4037h designate the size of this attribute. In our case 48h, what means that the next attribute begins at the offset 4030h + 48h = 4078h.
The byte in 4038h is the Flag which designates if the attribute is or is not resident, i.e. if its data is or is not included into this file, assuming:
- The value 1 when it’s non resident.
- The value 0 when it’s resident.
In our case it’s 0, thus residents.

The byte in 4039h designates the name length. In our case 00, as it has no name.
The 2 bytes from 403Ah to 403Bh designate the name offset. In our case 18h, which means that the name description should begin at the offset 4048h, if it should have one.
The 2 bytes from 403Ch to 403Dh are Flags too, now with the meaning as follows:
- 0001h – Compressed
- 4000h – Encrypted
- 8000h – Sparse
Only the attribute data can be compressed or sparse and only when they are non-resident.
The 2 bytes in 403Eh and 403Fh designate the Attribute ID. This value is exclusive for each attribute. In our case ID = 1.
The 4 bytes from 4040h to 4043h represent the Attribute data length. In our case is 30h, i.e. 48 Bytes.
The 2 bytes in 4044h and 4045h represent the attribute data offset. In our case 18h relative to the attribute beginning. This way we can conclude that the data from this attribute starts at the offset 4030h + 18h = 4048h and that the next attribute starts at the offset 4048h + 30h = 4078h, as we verified before.
The byte in 4046h is the indexed Flag. In our case 00.
The byte in 4047h is the aligning Padding for the designations length to the nearest 8 bytes multiple.
In our case is 1 Byte, precisely the one where it is. One case where the padding is used to align to the middle of the hexadecimal line and its value is always 00h.
We finish here the description of a resident and no name Attribute header .
$STANDARD_INFORMATION Attribute
In figure 13 we have the table with the different fields of this attribute, their size in bytes and their offset. This table must be used in the comparison with the fields of the hexadecimal editor representation for the same file presented in figure 12. The brown shadowed part represents the header we’ve just analyzed. The 48 Bytes corresponding to its size, from which we were informed through the header reading, come next and decomposed in several colors according to the several fields.

This attribute body begins at the offset 4048h, as we’ve been informed by the header reading.
The 8 Bytes from 4048h to 404Fh – Date/time of the file creation.
In our case is 00 E1 7D D5 C4 E4 CA 01h, what means 25-04-2010 at 22:15:38 (forget trying to do this at home alone because it was the hexadecimal editor who translate this for us) .
The 8 Bytes from 4050h ato 4057h – Date/time of the file modification. In our case 25-04-2010 at 22:15:38.
The 8 Bytes from 4058h to 405Fh – Date/time of the MFT modification. In our case 25-04-2010 at 22:15:38.
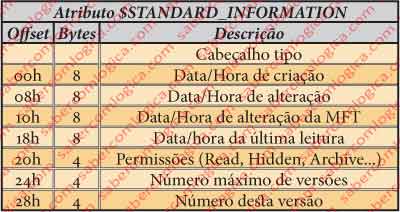
The 8 Bytes from 4060h to 4067h – Date/time of the file reading. In our case 25-04-2010 at 22:15:38.
The 4 Bytes from 4068h to 406Bh – File Permissions. In our case is the flag 6. It doesn’t apply to this type of file created and used by the system.
The 4 Bytes from 406Ch to 406Fh – Maximum number of versions allowed for this file. In our case is 0, which means that version numbering is disabled.
The 8 Bytes from 4070h to 4077h – Version number. This value will be zero if the previous is zero too, what’s our case.
Once finished the analysis of this attribute, we’ll now proceed with the next attribute, the $FILE_NAME.
$FILE_NAME Attribute
This attribute, as it was designated at the header of the previous attribute, initiates at the offset 4078h.
In the figure 32 of the $AttrDef file, this $FILE_NAME attribute is green shadowed. Here we include it in detail in figure 14.
It’s a resident and no named attribute too, reason why its header has the same descriptor used for the previous attribute. For this attribute header analysis we are going to follow the table in figure 10 and the brown shadowed fields in figure 14.
- It has the type 30h, i.e. it’s a $FILE_NAME
- Its length is of 70h (118 bytes), thus the next attribute beginning at the offset 4078h+70h = 40E8h.
- It’s a resident
- The Attribute ID is 2.
- The data length is of 52h (80 bytes).
- The data offset is 18h.
- The indexed flag is 1.
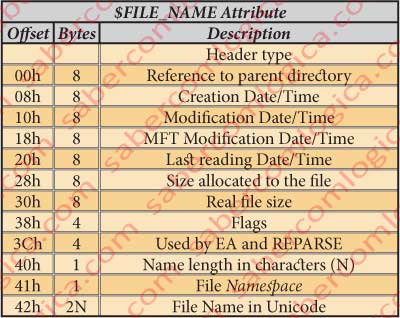
We are now going to analyze the attribute body, starting at the offset 4090h (4078h+18h = 4090h). As usually we’ll use a table with the $FILE_NAME attribute fields description, their size in bytes and their offset relative to the beginning of its body, represented in figure 15.
The hexadecimal editor representation in detail of their attribute is in figure 14 where its header, as in the previous case, is brown shadowed.
The 8 bytes from 4090h to 4097h refers to the entry in the MFT of its parent directory.
The 8 bytes from 4098h to 409Fh refer the Date/time of the file creation. In our case 25-04-2010 at 22:15:38
The 8 bytes from 40A0h to 40A7h refer the Date/time of the file modification. In our case 25-04-2010 at 22:15:38
The 8 bytes from 40A8h to 40AFh designate the Date/time of the MFT modification. In our case 25-04-2010 at 22:15:38

The 8 bytes from 40B0h to 40B7h refer to the Date/time of the file reading. In our case 25-04-2010 at 22:15:38
The 8 bytes from 40B8h to 40BFh designate the space allocated to the file. In our case is 1000h, or 4096 Bytes, or 8 sectors, or 1 cluster.
The 8 bytes from 40C0h to 40C7h designate the real file size. In our case is 0A00h, or 2561 Bytes.
The 4 bytes from 40C8h to 40CBh describe the flags. In our case 0006h. We aren’t describing any kind of normal file but the own metadata file which is hidden and system.
These flags designate the type of file and some of its properties as in the table of figure16 which describes some flags and the corresponding file properties. You’ve certainly seen already some of them in the windows describing the file properties.
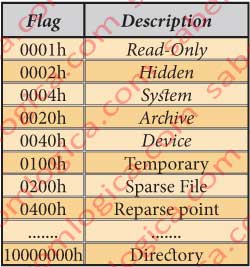
The 4 bytes from 40CCh to 40CFh – Space used by EA and Reparse.
If the file has Extended Attributes (EA), then the EA field will have the size of the necessary buffer. If the file is a Reparse Point then the Reparse field will give its type.
The byte in 40D0h – Designates the name size in characters (N). In our case they will be 8 characters ($AttrDef).
The byte in 40D1h describes the Namespace in which the file is named. In our case is the namespace 3, corresponding to the namespace DOS.
The 2xN following bytes, in our case 2×8=16 characters or 16 bytes de 40D2h a 40E1h represent the file name in Unicode ($.A.t.t.r.D.e.f.). In Unicode each character occupies 2 Bytes. See in figure 12-17.
The 6 bytes from 40D2h to 40D7h – Represents the value for the Padding to 8 Bytes
$SECURITY_DESCRIPTOR Attribute
The attribute that comes next in the $AttrDef file is the $Security_Descriptor which, as defined in the header of the previous attribute, begins at the offset 40E8h.
In the figure 32 of the $AttrDef file, this attribute is red shadowed. Here we are going to present it in detail with the figure 19. It’s a resident and no named attribute too, reason why its header has the same type as the previous.

- Its type is 50h what matches a $SECURITY_DESCRIPTOR attribute
- The attribute length, including the header, is of 80h (128 bytes), therefore the next attribute beginning at the offset 40E8h + 80h = 4168h.
- It’s a resident
- The attribute ID is 3.
- The data length is 68h (104 bytes).
- The attribute body offset is 18h, therefore beginning at the offset 40E8h +18h = 4100h.
And so here we are, at the offset 4100h, where we’ll start reading the attribute. One detailed analysis of this attribute is not useful for our purpose – To show the logic followed by the NTFS when searching for a file – and it would be extremely tough as its analysis is very complex and long. We do not intend to unreasonably thicken the information provided. This is the principle that we already stated at the beginning of our work which we intend to keep as it proceeds. This however does not prevent us to describe the main features and functionality of the same.
Briefly, the data of this attribute has a header with flags that index the various blocks of information in which it is divided such as flags and Access Control Lists. It’s this attribute that defines the values of individual and group permissions, inheritance, propagations and other that define what we can see in interesting graphical shape with the several windows where the files security is set up (properties/security) where are defined the users, the groups and the access permissions for each. What this attribute rules are the access safety conditions to files and/or folders by all the possible system users, both individually and as the group they belong to.
Each individual and/or each group can have different permissions and those permissions do not only concern access to each file individually, as well as the various forms of action in that file. In order to do all the described, this attribute creates multiple blocks which define the type of permissions, creates indexes to users and groups tables and links all this within each file. And still manages the propagation or inheritance between Parent nodes and Children nodes (File → Folder and Folder → Parent Folder).
This said we proceed to the following attribute which, as we’ve already seen begins at the offset 4168h. It’s the $DATA attribute, which is a non-resident and no named attribute, reason why we leave its description to the next article.