
Multi Thread
Let’s make one more visit to Mary and see how she is managing her kitchen.
It seems that in the meantime Mary came to the conclusion that her kitchen still could become more profitable, because she realized that there were parts of her cooking recipes that could be executed separately and in parallel.
In a recipe of stuffed meat and potatoes, for example, the meat preparation, the stew preparation, the preparation of a set of supplies that would be cooked together with meat, and potatoes preparation, could run in parallel, so that they were all ready when it’s time to join them in the pot, which would then be cooked in low heat over a given period of time.
But she could not do everything at once.
So she decided to hire more people, and for each recipe after being split into separate tasks, deliver each task to a different employee.
The mess was generated in the kitchen, as people quickly began walking to clash with each other, having more time lost this way than the gain in profitability.
She decided to divide the kitchen into independent parts for each of these employees and buy more resources for the set of the kitchen’s parts.
There was no doubt. She immediately started to be able to run much faster her cooking receipts and consequently could she could accept more work, which incidentally did not lack.
Things were so that Mary became only the planner and manager of receipts division into parts, assigning them to each employee. And the business was going from strength to strength.
What Mary did was dividing the confection processes in tasks (threads) and throw them running in parallel in different parts of the kitchen.
Threads are exactly the same, in the CPU context. The process launches several separate threads, which are executed in the same context, the same address space but in separate stacks.
The threads contribute to increased father process performance. Among the various ways by which this can be done, we highlight two as examples:
- Changing values of global variables by means of the functions of each, such that the parent process can now continue with the new value of those variables, using operations that threads performed by it, in parallel. For example in image processing of a game in simulated 3D there is a huge amount of variables that can be calculated without interdependencies between them and which contribute to the final aspect of each frame. For this reason the GPU (Graphics Processing Unit) has hundreds of cores, some of them having even exceeded one thousand cores.
- Parallel execution of program functions that have no sequence between themselves and which can therefore be performed separately and in parallel, all contributing to the end defined by the program. For example the analysis of thousands of files of a volume which, instead of being performed one by one by the process can be done for as many threads in parallel as many cores CPU has.
Through these two examples it becomes clear that multitasking environment is especially efficient in multinuclear processors.
Each core is an independent CPU, still only able to run a process/thread at a time, so it’s worth nothing to have many threads if we don’t have the necessary number of processing cores to keep them at peak performance.
Evidently the previous statement considers the fact that each core can have multiple tasks of the same process running in multiprocessing environment, for each one, for this purpose, is a process.
Programming by threads gets the best results as more CPU cores there is. For this the advent of multinuclear CPU chips such as the Intel i7 e.g., with four cores and Hyper-Threading on each core.
Hyper-threading? What’s this?
Hyper-threading
Hyper-threading is a technology developed by Intel and first employed in its Pentium 4 Northwood.
Hyper-threading simulation consists of two logical processors on a single physical core of a CPU, using the time not used by the CPU resulting from Pipeline bubbles.
Although the pipeline technique has already been addressed in the Chapter about CPU, we recall here the essential, as in the result of applying this technique arises hyper-threading.
Pipeline is the technique by which a CPU executes machine instructions not in a strictly sequential but in a parallel manner, according to the clock cycles for each micro operation (μOp) and the availability of resources.
For example, if a statement is executed in four clock cycles, each cycle of the CPU clock begins a new instruction in parallel with the above, using the resource already abandoned by the first one.
The ideal and optimistic result for this method would be a total completion time of the CPU, but this is not the reality.
Whenever an instruction must be waiting for another one’s result, or several already ran instructions are set aside for the existence of unexpected jumps, unused spaces of time are generated. To these spaces we call Bubbles.
It is precisely these bubble times that CPU Hyper-threading technology uses to create a second logical processor inside the CPU.
Thus, on the same physical CPU two logical processors are created, each with its own programmable interrupts controller and its set of registers, sharing the remaining physical CPU resources.
We will soon see in a case study, what the Intel Nehalem architecture (an i7, e.g.) created within a processor core, thanks to the huge number of transistors that can actually be placed in a single chip, in order to make better use of cores processing, having as an objective to achieve the execution of one instruction per clock cycle, i.e. the complete extinction of bubbles on a heavy staged pipeline.
This is the way that we talked about earlier. Instead of increasing the frequency of CPU vibration, the Human is trying to take full advantage of the currently existing one. And there are tons of work ahead and immense possibilities that get opened.
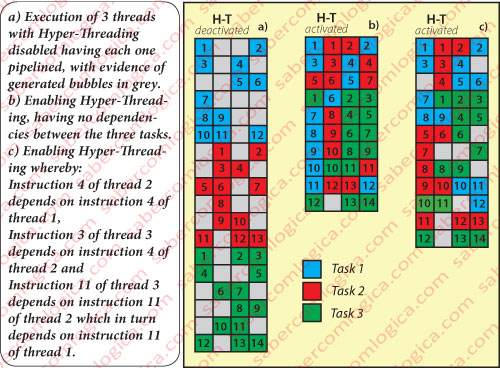
We will now use Figure 1 that represents the execution of three threads in three different situations:
- a) The three threads are performing in sequence, each in pipeline, with Hyper-Threading disabled, representing up the gray bubbles.
- b) With Hyper-Threading enabled but considering that there are no dependencies between the three threads.
- c) With Hyper-Threading enabled but considering the following dependencies:
- Instruction 4 of thread 2 depends on instruction 4 of thread 1,
- Instruction 3 of thread 3 depends on instruction 4 of thread 2 and
- Instruction 11 of thread 3 depends on instruction 11 of thread 2 which in turn depends on instruction 11 of thread 1.
The columns of the tables represent the stages of the pipeline, in this case 4 stages.
The filling with decomposition pipeline and without Hyper-Threading activated in situation a) was done randomly, but happened so that filling of bubbles in situation b) is total and the execution time is reduced in about 45%. This is due to the fact that we didn’t consider the existence of dependences between the three threads.
In situation c) we already considered some dependencies between threads, as described above. It is thus apparent that the number of bubbles increases, despite the activation of Hyper-Threading, and the time reduction is about 30%, what is unfortunately closer to reality.
According to information from Intel, the execution times reduction due to Hyper-Threading is about 30% on average.
This technology is still very much alive in multinuclear Intel processors such as the i7, which by that mean provide up to 12 logical processors.
Programming by threads is what is expected to guarantee the performance increase in the future according to the evolution of CPU.
The size of transistors is decreasing. CPU manufacturers have no longer, in increasing CPU frequency vibration, their first goal. The concept of multiple CPU cores on the same chip, each core having all the components of an independent CPU, including level 1 and 2 caches.
All this evolution indicates the investment that CPU manufacturers are making in parallelism, thus in executing programs by threads.
They are doing exactly as Mary, when she found her kitchen full of people colliding with each other. She didn’t put people running faster. She found a way for people to execute its tasks without conflicting each other.
Multi Thread Programming
Under these conditions it is evident the tremendous improvement in performance of a program ready to run in multi thread environment.
But the development of such programs is very complex requiring much knowledge and care. However it is still the sum of the most elementary simplicities.
The division of a process in threads, keeping the process running itself, is a consequence of a programming technique much more complex than normal programming, because the competition problems that generate situations of data inconsistency can easily happen if not properly planned and treated.
The OS itself has a destabilizing role in this inconsistency. OS may at any moment, between μOps, remove the CPU to one of the running threads.
Suppose that the removed thread had just read the value of a global variable to modify it. Suppose OS grants CPU access to another thread of the same process, which will precisely read the same variable, modifies it and writes it. If this is possible to happen, when the previous thread resumes in CPU, it will use the previous value of this variable, that it read (had read it before the 2nd thread changed it, modifies it and writes the result.
When this happens, we will have a situation of data inconsistency, i.e. one of the operations that affected the actual variable is null or duplicated and the end result is wrong.
Executing threads is like running a program in a distributed environment, only within the same computer. Here’s an example.
Suppose the referred variable was the balance of a Bank account of a customer, and that the Bank has only a central server and multiple terminals.
The customer had a balance of € 5,000 and went to a Bank agency to withdraw his money. The employee who attended him began to perform thread 1.
In the meantime, another client went to another Bank agency to raise a check of € 5,000, issued by the 1st client over the same account. The employee who attended him began to perform thread 2.
Both threads started almost simultaneously, but thread 1 started first. It read the customer’s balance, which was 5,000 € and when it was going to run the next step, the OS took the CPU from it and granted the CPU to thread 2. Task 2 read the customer’s balance, which was still € 5,000, and paid the amount of the check.
When CPU was granted again to thread 1, it will continue its work from the point where it was. For it, the account balance which had just read is € 5,000 and so it will deliver that value to the customer. Result:
- The customer account holder is delighted.
- The Bank is furious.
- The programmer is fired and prosecuted.
The OS has direct intervention on generating problems of data inconsistency when switching processes on CPU.
The development of algorithms for the OS, which allow overcoming all possible scenarios in which the inconsistency can be generated, proved to be of enormous complexity, even turning the system slower.
Thus, OS developers decided to provide tools to help program developers, creating in its kernel routines that implement functions to be called by program developers under their own algorithms, to solve their problems.
Semaphore and Mutex
The Contest
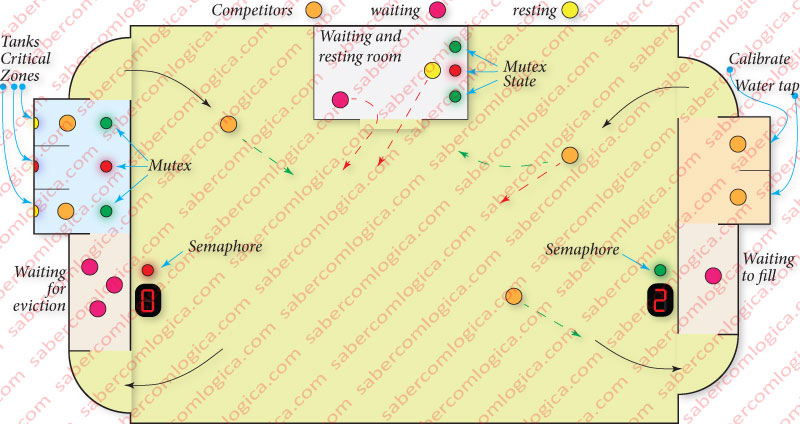
Bob entered a competition which aimed to pour water into 3 deposits that were strictly empty at the beginning, for a given period of time, with buckets with 5 liters of capacity each.
For that purpose he should build a team. The buckets were pre-filled into a single tap, from which each competitor had to traverse a course of 50 mt until the filling deposit.
At the end the winning team will be the one that has the best ratio, i.e. more liters dumped by competitor and shall know the exact amount of water existing in the three deposits, a condition that, if not met, will lead to disqualification.
Next to the filling and eviction areas there is a small waiting area and at the middle of the course there is a resting area.
Access to the filling and eviction areas is done through the waiting areas. None is visible to anyone in course.
We can follow the description in Figure 2.
The Rules
The organization of the competition created a set of rules in order to compel the important work of planning and rationalization:
- Only a competitor could be at a time in the dumping area of each deposit.
- As soon a competitor leaves that zone, another one lying in the waiting area can advance.
- Before a competitor starts dumping he should press a button that lights a panel only visible to him for a few seconds, indicating the amount of water in the tank.
- When a competitor finishes dumping, he should write the new amount of water in that deposit with quick access large keys and. Then, he could begin a new route.
- Because competitors need to rest, periodically a buzzer rings and a red light turns on in a deposit. The competitor that in that moment is present in that deposit has to stop immediately and withdraw to the rest room.
- In the rest room, a red light in identical position as the deposit, indicated the competitor while he should rest there.
- This competitor should go to the waiting area and then to the deposit where it had been interrupted, resuming his task at the exact point where he was interrupted.
- The contest should to be done in total silence, being expressly prohibited any communication between competitors.
- A maximum of three competitors can stay at any of the waiting areas.
- The waiting, dumping and filling areas are not visible to competitors on the route.
The Strategy
Because the contest was a challenge to planning and strategy, with prestigious awards, Bob has well prepared his strategy before the contest.
He decided that it would launch simultaneously several people to fill and pour buckets as a way to put more water in the deposits over the same period. But the situation was not as simple as that, because rules placed several constraints that he has been annotating during training sessions. Apart from the fact that the more competitors were at rest, the worse the average yield would be.
He tested until the less cost effective possible the times of filling and calibrating the buckets, so that the tap of the tank could be always opened and filling buckets. For this reason he only wanted two competitors simultaneously filling in the area: one filling and another calibrating. When the one who was filling finished his job and began calibrating, another competitor in the waiting area immediately began filling his bucket as calibrating took less time than filling.
In the dumping area the analysis was much more complex. There was also a waiting room with access restrictions before this area. It was therefore important to analyze how the waiting areas would work.
Bob began by studying the available resources in the waiting areas. As those resources were not visible from the course, he considered that it was necessary that the competitors at course knew the state of those resources before they got there.
The waiting areas were at the tops of the course and the resting area was a room in the middle of the course. The simple fact that competitors could reach those waiting areas and only then check that the resource was depleted, forcing them to return immediately to the resting room, was not only a useless waste of energy as an obstruction to the movement of the competitors who were in course.
He decided to put an electronic display outside the waiting areas. The value in the display was increased by a button that was pressed by the competitor at the entry and decremented the same way at the exit.
The display was initiated to 3 and decremented by everyone who came and never left. When there were 3 competitors inside the waiting area, 0 was indicated and a green light went red, which meant for the competitors that they should wait in the resting room before heading to the waiting areas. Just when the value turned out of 0, any of the competitors could move on. To these viewers Bob called Semaphores.
Solved the access control to the waiting areas, Bob continued with the analyses of the dumping area.
Because he knew the competitors could be stopped at any time, he divided the eviction to be made according to the rules in three distinct actions:
- Reading the value of the quantity in the deposit.
- Dump the bucket.
- Register the new quantity in the deposit.
These actions had, regarding the dumping action, the property of being Atomic actions, i.e. not decomposable in other actions. While the dump task could be interrupted by the horn at any time between actions that compose it, neither of these could be stopped, because it was not decomposable.
Once the stopped competitor was out of the dumping area, other competitor would advance for the same deposit, would read the value of the quantity of water in the tank, pour the bucket and record the new quantity. And then another could move, and repeat the procedure.
Meanwhile the time came for the stopped competitor to get out of the resting area and resume his action. When he returns to the dumping area and to the deposit where he was, as he had done the reading and had to resume exactly where he was stopped, he started by pouring the bucket, recording the new quantity and leaving for a new course. He had read 55 Lt, thus registering the new amount of water as 60 Lt. And he was doing well.
Just that in the meanwhile, after he had been stopped, the other two competitors had already passed and the amount of water in the deposit was not 55 but 65 Lt. By making his register he shuffled everything and created a situation of data inconsistency, which would cause that at the end the total amount of water in the deposits indicated by Bob would not be correct, consequently losing the contest.
Bob realized that each dumping action, once begun had to be completed by the competitor who initiated it, not being possible to any other competitor to execute any dumping action in that deposit in the meanwhile. Bob called it a Critical Section and started thinking of a way to accomplish what he realized.
Then he placed a red light on top of each deposit, which is turned on when the competitor presses the button to read the value of the quantity of water and is turned off only when the competitor finishes the introduction of the new quantity. It’s just like a semaphore that starts at 1. Bob called it Semaphore of Mutual Exclusion, but as he found the name too great he simplified it to Mutex.
That way, the competitors who were in the waiting area, when seeing their fellow getting out of the dumping area with the red light on, did not progress to such a deposit.
When the time came for the stopped competitor to resume his action, he drove directly to the deposit where he was when interrupted, because he knew that the red light was not for him. Concluding his action, he turns off the red light and returns to the course.
With all his analysis done, Bob thought it was time to test everything in training sessions, which would enable him to tune the optimal number of competitors. The rationalization was essential because the winner would be the one with the best ratio.
But that is an issue which is beyond the scope of this story which Bob certainly did well, because he won the contest.
From Metaphor to Reality
Threads, which as we have already seen are program lines made to execute in parallel in the same process, will encounter problems during its execution identical to those of our competitors.
The Semaphores and Mutex are precisely the names of the tools that OS offers to help treat and control these situations.
The threads launched by a process share the same memory space with father process, where each task has its own stack, being however common the heap and the space for program data, namely the global variables defined in the program and already created in compilation process, initialized or not, i.e. with a value already assigned or simply declared and therefore with reserved memory space.
All variables that are declared within a given program part at run time, become extinct when completed this part of the program being not visible in other spaces but the one where they are created. For this reason, this type of variable is usually placed on the stack, which is not shared.
As threads are running in parallel actions of the same process, they will need to work with global variables (e.g. the amount of water inside the deposits), those who are viewed by all actors within a process therefore being in shared memory areas.
It’s precisely in the sections where threads access this kind of variables that competition between them can generate situations of data inconsistency, being therefore called critical sections. It’s in these sections that the way threads can act has to be managed, in order to avoid situations of inconsistency.
For this purpose OS offer specific tools, case of Mutex and Semaphores. These tools are created, closed, opened or extinct through system calls, i.e. instructions causing interrupts that trigger the execution of OS kernel routines associated with them.
The control of these tools has to be done by program developers, which must define the critical sections and manage the way threads act inside them. They have to decide where and how to put them in the program, in order to avoid data inconsistency but also not to cause a program blocking.
Programming with threads is a high-level programming that requires a very deep understanding of how these tools work and great caution in its implementation.
In a complex program, tens or hundreds of mutex and semaphores can coexist, spread through its various critical sections, so being necessary to bear in mind how each one is acting in any moment and its possible interference with the others.
Programming with threads is the key for any complex program to be efficient, thus taking advantage of the new multi core CPU technology. Actually it’s in parallelization that CPU manufacturers are presently investing to increase their performance.
This parallelization is responsibility of CPU concerning the treatment of each program thread in each CPU core, but it’s a developer’s responsibility to supply and control the threads that will run in parallel in the different physical and virtual (through hyper-threading) CPU cores.
But each CPU core has its own L1 and L2 cache, where the same global variable can simultaneously be present to be changed by each thread. How is that solved?
That’s precisely the reason why we introduced the subject of cache consistency in cache chapter.
It’s the simultaneous action of OS, not allowing different threads simultaneously in the same critical section, and CPU hardware, not allowing any data changed in one CPU core’s cache to be accessed in any other core’s cache before being updated, that prevent that situation
We decided to introduce this subject via a metaphor, so avoiding the use of a program to do it. Such program would be complex and could not achieve the intended goal.
It’s our purpose in latter chapters to make an approach to programming languages that will enable the analysis of this issue through concrete programming actions.