
Protocolo DNS
Mas vamos avançar desde o ponto onde tínhamos ficado, quando acabámos de fazer a requisição. Construída a requisição pela camada aplicação com o protocolo HTTP, a mesma vai ser enviada para a camada abaixo, a camada transporte.
Mas alto. Ainda falta o nome do servidor www.condominiopartners.pt criado para o entendimento humano e que não é inteligível pela máquina que, como sabemos, só entende os dígitos 0 e 1. Para nós era muito complicado se começássemos a conhecer-nos pelos números dos nossos Bilhetes de Identidade. O João passava a ser o 332445626, o António o 245617287 e por aí fora. Por isso conhecemo-nos pelos nossos nomes e temos um número de BI ou número mecanográfico que é aquele pelo qual as máquinas nos identificam.
Então e agora, como fazer?
Agora há que usar o protocolo DNS (Domain Name System) para consultar o servidor de nomes, que fará a tradução do nome da hiperligação para um endereço IP, que será usado lá mais para a frente na camada de rede, no endereçamento da mensagem. O endereço IP que vamos usar durante este parágrafo será o IPv4. O IPv4 é composto por um conjunto de 4 Bytes, representado na forma de 4 números decimais separados por um ponto (1 Byte cada).
Concretamente ao nome www.condominiopartners.pt corresponde o enderço IP 188.72.202.158 ou seja, 10111100 01001000 11001010 11001010 em código binário, o tal que a máquina entende.
No atual contexto vamos só preocupar-nos em saber como é que a máquina faz para descobrir esta relação. Quanto aos endereços IP, à forma de endereçamento e encaminhamento, deixamos mais para a frente, para um parágrafo separado.
O DNS é simultaneamente uma gigantesca Base de Dados (BD) espalhada por uma multiplicidade de servidores e um protocolo que funciona no Browser, normalmente utilizado por HTTP, SMTP e FTP, por exemplo.
Então o Browser retira da URL o URN (Uniform Resource Name), isto é, do URL http://www.condominiopartners.pt/index.html retira o URN www.condominiopartners.pt e passa-o para a aplicação DNS do lado cliente, que envia uma consulta para um servidor DNS com o URN obtido. O cliente DNS recebe então uma resposta com o endereço IP correspondente ao servidor que tem o nome definido pelo URN.
Simples, não é?
Pois, dito assim até parece. Mas há atualmente cerca de 1,4 mil milhões de utilizadores da Internet.
Onde está a máquina que tem o mapeamento de todos estes endereços?
Como é evidente, não seria possível ter todos os endereços concentrados numa máquina.
- A distância a percorrer, para muitas máquinas seria enorme
- A entrada dessa máquina estaria permanentemente saturada e os tempos de espera seriam enormes.
- Devido à dimensão da Base de Dados e ao enorme tráfego sobre a mesma, os tempos de consulta também seriam bastante grandes e a sua manutenção um trabalho gigantesco.
A solução encontrada foi a distribuição da Base de Dados de uma forma hierárquica, por um número enorme de máquinas espalhadas pelo mundo. Assim, o meu servidor de nomes começa por contactar um servidor de nomes de raiz, isto é, um servidor onde estão registados os servidores que conhecem endereços dos domínios de topo da Internet, como por exemplo, com, org, edu, gov, net, … , pt, es, fr, de, eu, uk, us, br, etc. Aí obtemos os endereços dos servidores de nomes de TLD (Top Level Domain), concretamente no nosso caso os servidores de nomes do TLD pt. E vai ser um desses servidores, o que for contactado, que vai fornecer os endereços dos servidores de nomes autorizados para o nome condominiopartners.pt.
Finalmente, o meu servidor de nomes vai contactar um desses servidores, que lhe vai fornecer o endereço IP do condominiopartners.pt, concretamente 188.72.202.158.
Os servidores de nomes (raiz, TLD e autorizados), são sempre vários e espalhados pelo mundo, por razões de:
- Proximidade,
- Divisão de carga
- Segurança (replicação)
O meu servidor DNS é um servidor de nomes local e pode estar muito próximo do local onde está o meu Browser.
Mas então, com esta enormidade de consultas entre servidores, só para obter o nome vamos ter um significativo tempo de espera. Certo?
Certo. Mas, para evitar que assim seja, cada servidor de nomes dispõe de uma Cache de DNS, onde regista por tempo limitado os resultados das consultas que vai fazendo, o que lhe permite que em consultas idênticas que se sigam, a resposta seja imediata e sem mais consultas. O próprio servidor DNS local faz isto, substituindo-se assim aos servidores de nomes autorizados.
DNS (Domain Name System)
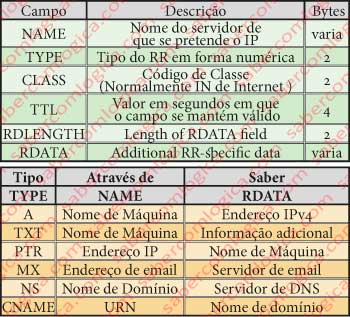
Os registos de mapeamento armazenados em um servidor de nomes, os RR (Resource Records), são constituídos pelos campos descritos na tabela da Figura 1 (em cima). Do valor de TYPE dependem o NAME e o RDATA e consequentemente aquilo que uma consulta DNS a um Resource Record permite saber, conforme a tabela da Figura 1 (em baixo).
- Se TYPE = A então NAME é o nome do hospedeiro e RDATA é o seu endereço IPv4
- Se TYPE = NS então o NAME é um domínio e RDATA é o nome de um servidor com autoridade para fornecer os endereços de hospedeiros do domínio
- Se TYPE = MX então NAME é o nome de domínio contido no endereço de email e RDATA é o nome do servidor de email para esse nome de domínio.
- Se TYPE = CNAME então NAME é o nome que se procura e RDATA é o nome de domínio contido no mesmo
Há muitos mais tipos mas vamos ficar por aqui como exemplo. Já contém o que nos interessa.
CLASS para o nosso caso é sempre definida como IN que significa Internet.
TTL é o tempo de validade do registo.
Vamos agora ver o formato da mensagem DNS, que é igual, tanto para a pergunta como para a resposta, variando simplesmente algumas flags e o preenchimento de alguns campos (Figura 2).
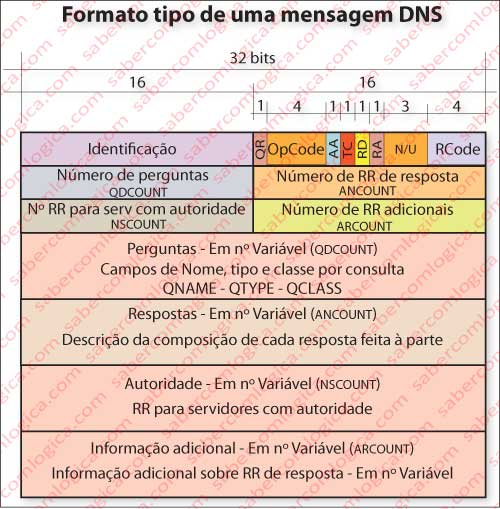
Identificação refere-se a um código único que permite relacionar a resposta com a pergunta.
As Flags estão nos segundos 16 bits:
- QR – Question (0) ou Resposta (1);
- OpCode – Operation Code, 4 bits, sendo por exemplo, 0 (Standard Query), 1 (Inverse Query) e 2 (Server Status Request);
- AA – Authoritative Answer (resposta de servidor com autoridade);
- TC – Truncated. Acontece quando a mensagem é muito grande e não cabe nos campos destinados. É continuada por outra;
- RD – Recursion desired (na pergunta);
- RA – Recursion Available (na resposta);
- RCode – Return Code. Por exemplo, 0 (Nenhum erro), 3 (Nome não existe).
O método de consulta é normalmente híbrido, isto é, resultante de uma mistura dos métodos iterativo e recursivo. Mas, porque aqui se fala em recursion desired e recursion available, vou fazer uma mínima introdução ao método.
No método recursivo o cliente consulta o seu servidor de nomes A, que por sua vez consulta um servidor de nomes B, e assim sucessivamente até que retorna ao servidor de nomes B, que dá a resposta ao servidor de nomes A, que por sua vez dá a resposta ao cliente.
No método iterativo o Cliente pergunta ao servidor A, que indica ao Cliente o servidor B como possível conhecedor do nome. Então o Cliente consulta o servidor B que lhe indica o servidor C como possível conhecedor do nome. E assim sucessivamente até o Cliente consultar o servidor X que conhece o nome e lhe dá a resposta.
O método híbrido foi aquele que descrevi logo no início deste parágrafo.

A título de exemplificação vamos agora ver como são as mensagens DNS de consulta e resposta que foram
trocadas no nosso caso de estudo.
Transaction ID: 0x1a53
Flags:
0 = QR: Message is a query
0000= Opcode: Standard query (0)
0 = AA: No
0 = TC: Message is not truncated
1 = RD: Do query recursively
0 = RA: N/A
000 = Z: reserved (0)
0 = Non-authenticated data OK: Non-authenticated data is unacceptable
0 = N/A
0000= No error
Questions: 1
Answer RRs: 0
Authority RRs: 0
Additional RRs: 0
Queries:
www.condominiopartners.pt: type A, class IN
Name: www.condominiopartners.pt
Type: A (Host address)
Class: IN (0x0001)
e porque neste caso é especialmente interessante, até porque permite visualizar como se indica o Domain Name digitalmente, vamos apresentar o código binário para esta consulta na Figura 3 (Em cima), sob a forma hexadecimal, em que como sabem cada dois dígitos representam um Byte.
Em relação ao nome, veja-se o significado da forma de apresentação do mesmo também na Figura 3 (Em baixo).
Vamos agora ver o modelo da mensagem de resposta, deixando a interpretação convosco:
Transaction ID: 0x1a53
Flags: 0x8180 (Standard query response, No error)
1 = Response: Message is a response
0000= Opcode: Standard query (0)
0 = Authoritative: Server is not an authority for domain
0 = Truncated: Message is not truncated
1 = Recursion desired: Do query recursively
1 = Recursion available: Server can do recursive queries
0 = Z: reserved (0)
0 = Answer authenticated: Answer/authority portion was not authenticated
0 = N/A
0000 = Reply code: No error (0)
Questions: 1
Answer RRs: 2
Authority RRs: 2
Additional RRs: 0
Queries
www.condominiopartners.pt: type A, class IN
Name: www.condominiopartners.pt
Type: A (Host address)
Class: IN (0x0001)
Answers
www.condominiopartners.pt: type CNAME, class IN cname condominiopartners.pt
Name: www.condominiopartners.pt
Type: CNAME (Canonical name for an alias)
Class: IN (0x0001)
Time to live: 4 hours
Data length: 2
Primary name: condominiopartners.pt
condominiopartners.pt: type A, class IN, addr 188.72.202.158
Name: condominiopartners.pt
Type: A (Host address)
Class: IN (0x0001)
Time to live: 4 hours
Data length: 4
Addr: 188.72.202.158
Authoritative nameservers
condominiopartners.pt: type NS, class IN, ns ns4.ptwebserver.com
Name: condominiopartners.pt
Type: NS (Authoritative name server)
Class: IN (0x0001)
Time to live: 17 hours,42 minutes,13 seconds
Data length: 21
Name server: ns4.ptwebserver.com
condominiopartners.pt: type NS, class IN, ns ns3.ptwebserver.com
Name: condominiopartners.pt
Type: NS (Authoritative name server)
Class: IN (0x0001)
Time to live: 17 hours, 42 minutes, 13 seconds
Data length: 6
Name server: ns3.ptwebserver.com
Cookies
As cookies podem fazer parte do cabeçalho HTTP, e são muito utilizadas por Sites que pretendam conhecer o historial e hábitos genéricos dos seus clientes nas visitas a esses sites, reconhecê-lo como cliente registado e outras.
O serviço de cookies tem 4 elementos fundamentais:
- Uma linha no cabeçalho de resposta HTTP
- Uma linha no cabeçalho de requisição HTTP
- Um arquivo de cookies gerido pelo Browser
- Uma base de dados devidamente gerida no servidor.
O serviço de cookies é criado quando se acede pela primeira vez a um site que utiliza cookies, como é o caso de um serviço de vendas eletrónicas, por exemplo.
Então, na mensagem de resposta esse Site envia uma mensagem em cujo cabeçalho HTTP inclui:
Set-Cookie: 234879
O nosso Browser então vai adicionar este código ao arquivo de cookies relacionando-o com o Site.
A partir daqui, de cada vez que formos aceder a este Site, o Browser, antes de construir o pacote HTTP, verifica se no arquivo de cookies existe alguma cookie relacionada com o nome da consulta. Verificando que sim insere no cabeçalho uma linha
Cookie: 234879
Assim, o servidor do Site em questão, quando abre o pacote consulta a sua Base de Dados e verifica que esse Browser já o visitou. Provavelmente até já terá um arquivo organizado referente a essa cookie, que lhe diz quais as preferências e muitos outros hábitos do cliente que utiliza esse Browser.
Certamente já vos aconteceu ao chegarem a um Site como a Amazon, Pixmania ou eBay, por exemplo, ser-vos apresentada uma lista com opções de compra de produtos a que acederam das últimas vezes que os visitaram. Pois é precisamente desta forma que o tal Site descobriu essas preferências. Não é bruxedo, descansem!
Os Sites destas grandes empresas dispõem de um tipo de Bases de Dados, conhecidas por Data Wharehouses (Armazéns de Dados), que são alimentadas por dados recolhidos sobre quaisquer atividades existentes sobre o seu site, como por exemplo todos os cliques que alguém em qualquer parte do mundo faz num hiperligação que conduza a esse Site, bem como pelos registos da Base de Dados que já não são necessários à gestão corrente (o chamado histórico).
Sobre estes dados são executadas consultas efetuadas por programas altamente elaborados que percorrem regularmente os arquivos dos ficheiros constituídos com toda esta informação, criando outros registos organizados de forma completamente diferente e já virados para a gestão da própria empresa.
A este processo de tradução chama-se Datamining. É através do DataMining que posteriormente se elaboram avançados programas de gestão da informação com vista aos serviços de apoio à decisão. Fizemos uma suave tangente à área das Tecnologias de Informação.
No caso de posteriormente se registarem num destes Sites, também a vossa informação pessoal é associada. Certamente já vos aconteceu, ao chegarem a um destes Sites, antes mesmo de fazerem Login, serem tratados pelo vosso nome. E continua a não ser bruxedo. É trabalho efetuado com a ajuda das cookies.
É também por causa das cookies que é possível num Site de compras eletrónicas ir constituindo um carrinho de compras que só é pago no fim. As cookies permitem ao servidor reter o estado do utilizador num ficheiro específico.
As cookies têm levantado muitas discussões sobre a intrusão que representam para a privacidade de cada um. Mas isso são outras águas que, para este trabalho, não vêm a propósito.
As cookies são também usadas na camada transporte com o nome de SYN Cookies, tendo por fim prevenir ataques informáticos usados para tornar um serviço inacessível. Precisamente porque são usadas na camada transporte, só lá lhes faremos referência, para que possa ser entendida.
Servidor Proxy
O servidor proxy é fundamentalmente uma Cache Web, um servidor que fica entre o Browser e o exterior. Assim, qualquer requisição que parta do Browser passa primeiramente pelo servidor proxy, competindo a este a consulta ao exterior.
Por cada resposta recebida o servidor proxy vai enriquecendo a sua cache com as preferências daqueles que o utilizam, de tal forma que a partir de determinada altura só uma muito menor percentagem das requisições não é satisfeita pelo servidor proxy.
O servidor proxy é normalmente utilizado em redes empresariais, de edifícios, de campus universitários, etc.
Como tal, o servidor proxy também permite, se as pessoas assim o quiserem, funcionar como uma potente Firewall e mesmo como um seletor do tipo de conteúdo das páginas que são requisitadas.
E como é que o proxy sabe que a informação que tem em cache não está desatualizada?
O servidor Proxy tem guardado junto com o elemento que tem em cache sobre um Site, a data da última atualização do site que lhe foi enviada como uma das linhas do cabeçalho
Last-Modified: Wed, 22 Jul 2011 10:20:32
A partir de algum tempo em cache (normalmente muito pouco), quando chega uma requisição ao proxy sobre esse Site em cache, o servidor proxy faz uma consulta ao referido Site com um GET condicional, para o que inclui no cabeçalho uma linha
If-modified-since: Wed, 22 Jul 2011 10:20:32
Como resposta, ou obtém nova informação sobre o Site ou a simples curta mensagem em que a primeira linha diz
HTTP/1.1 304 Not Modified
sendo 304 o estado e o texto o seu significado curto.
Conclusão
Agora que temos o endereço IP para o nosso servidor, já podemos passar o pacote com a consulta HTTP para a camada abaixo, ou seja a camada transporte.