
Camada Aplicação
Como já foi dito, a camada aplicação é onde correm as aplicações (programas) que criam ou lêem a mensagem a enviar ou receber.
Os protocolos mais frequentes para empacotar estas mensagens são:
- HTTP (Hiper Text Transfer Protocol), usado para as comunicações WEB, isto é, para pedir e receber páginas de Sites da Internet ou para enviar ou receber dados para ou de outros computadores.
- SMTP (Simple Mail Transfer Protocol), usado para empacotar as mensagens de correio eletrónico.
- FTP (File Transfer Protocol), usado para empacotar ficheiros que se pretendem transferir.
- DNS (Domain Name System), usado para conhecer endereços de computadores através dos seus nomes.
- BitTorrent, usado para permitir a comunicação entre múltiplos computadores com o fim de partilharem ficheiros.
Há muitos mais, mas que por agora não serão mencionados.
Ao descrever estes protocolos já foram referidas diversas aplicações de rede, como por exemplo a WEB, o Correio eletrónico e o μTorrent.
As aplicações de rede utilizam arquiteturas de aplicação específicas que são:
- Arquitetura Cliente – Servidor,
- Arquitetura Peer-to-Peer (P2P) ou cliente – cliente.
- Arquitetura Híbrida, que combina as duas anteriores.
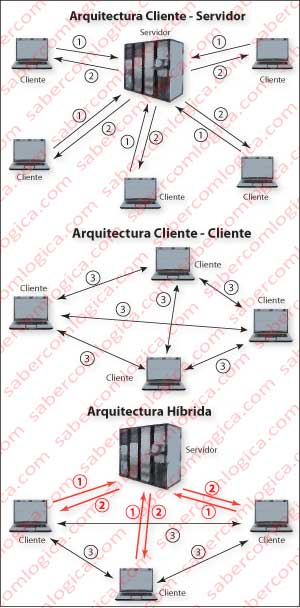
A arquitetura Cliente – Servidor pressupõe uma ligação entre um Cliente e um Servidor que, tal como os nomes indicam, solicitam (Figura 1a linha 1) e fornecem (Figura 1a linha 2) serviços.
O Cliente, no nosso caso, como utilizadores da Internet, é o Browser (Internet Explorer, Google Chrome, Firefox, etc.) para a WEB e o Outlook (ou similar) no caso do Correio eletrónico.
O servidor WEB é uma máquina que está algures na rede e guarda os objetos que compõem as páginas que o Cliente requisita.
Portanto, na arquitetura cliente – servidor, o cliente requisita um objeto ao servidor, que lho fornece.
Dos protocolos que indiquei, as aplicações que utilizam os 4 primeiros (HTTP, SMTP, FTP e DNS) são aplicações Cliente – Servidor.
Neste tipo de arquitetura os clientes não falam entre si, ou seja, não se interconectam. Só comunicam com os servidores.
Na arquitetura Peer-to-Peer (P2P) os clientes falam entre si (Figura 1b linha 3). Dispõem para isso de aplicações específicas para o efeito que, por exemplo, procuram na rede que clientes têm um ficheiro especifico que pretendem, estabelecem comunicação com esses Peers e começam a carregar o dito ficheiro a partir desses Peers, por blocos, colocando simultaneamente na rede partes desses mesmos ficheiros.
Na arquitetura Híbrida, os clientes consultam um servidor através de uma conexão cliente servidor (Figura 1c linhas 1 e 2) que lhes indica quais os peers (pares/clientes) que estão ligados e que disponibilizam o ficheiro pretendido, passando a partir daí os clientes a estabelecer uma conexão P2P entre si (Figura 1c linha 3).
Exemplo desta arquitetura são os programas que utilizam o protocolo BitTorrent, como por exemplo a aplicação μTorrent, que certamente é do conhecimento de muitos que a utilizam. Nesta aplicação, o cliente (Peer) consulta um servidor que indica os endereços de outros Peers semeadores (seeders) disponíveis para o ficheiro solicitado. A aplicação encarrega-se depois de estabelecer a comunicação P2P entre o seu cliente (peer) e os outros clientes (peers). Só para que não fique confusão instalada em ninguém importa referir que também existe uma aplicação com o nome BitTorrent que utiliza o protocolo BitTorrent.
Quando se clica num link
Porque não é esse o objetivo que nos propomos vamos aqui tratar o caso WEB, um dos mais comuns entre todos os utilizadores da Internet e que consiste na navegação pelos Sites e pelas suas páginas. Vamos ver o que se passa e a atividade que é desenvolvida depois de clicar num link até recebermos a página correspondente a esse link. Suponhamos que, num documento que estamos a ler está a seguinte hiperligação, que estamos interessados em consultar.
http://www.comdominiopartners.pt/index.html
O que na realidade faz uma hiperligação é utilizar o URL (Uniform Resource Locator) que representa. Este URL tem dois componentes:
- O nome do hospedeiro (servidor WEB neste caso): www.condominiopartners.pt
- e o nome do caminho do objeto que se pretende: /index.html
Então, ao clicar nesta hiperligação, acionamos o URL que ela contém e o nosso Browser vai emitir um pedido através do protocolo HTTP, o protocolo usado em aplicações WEB, como já tínhamos referido.
Vamos então ver como funciona o protocolo HTTP para esta situação concreta.
Protocolo HTTP
Antes de mais, vamos falar sobre alguns nomes estranhos a que vamos fazer referência neste parágrafo.
O HTTP é implementado na máquina cliente (Browser) e na máquina servidor (Web Server) e descreve a forma e a estrutura que as duas máquinas vão usar para trocar mensagens entre si. É portanto através do HTTP que as duas máquinas vão conversar uma com a outra.
E em que consiste essa conversa?
A máquina cliente vai pedir à máquina servidora uma página Web, que é constituída por objetos que o Web Server tem guardados. Uma página Web tem por base um objeto que é o HTML (Hyper Text Markup Language). HTML é uma linguagem descritiva Web definida como Markup language.
Markup language é uma linguagem textual, anotada por forma a que os diferentes textos que a compõem se distingam naquilo que representam.
O objeto HTML contém referências para outros objetos que compõem a página, como sejam imagens, scripts em JavaScript, applets de Java, filmes Flash, CSS etc. Destes objetos uma especial referência para objetos CSS (Cascade Style Sheet) que é escrita em Style Sheet Language e que serve para definir a apresentação de um documento escrito numa markup language, com especial incidência em HTML.
Style Sheet Language é uma linguagem que expressa a apresentação de documentos estruturados.
Falar sobre estas linguagens não é, para já, o objetivo deste trabalho. No entanto indicamos como, quem estiver interessado, pode visualizar os códigos base de HTML, CSS e JavaScript de uma página Web. Qualquer Browser dispõe de ferramentas de developer (programador) que evidenciarão esse código. Pessoalmente costumamos utilizar o Firebug do Firefox. Para obterem mais informação sobre HTML, CSS ou JavaScript, linguagens de programação geridas pelo W3C (World Wide Web Consortium), poderão visitar o Site das W3Schools: http://www.w3schools.com/
Mas antes vamos compreender bem o trabalhão que vão dar ao computador quando carregarem nesse hiperligação. Por isso, vamos continuar, não com este mas com a hiperligação em concreto do nosso trabalho
http://www.comdominiopartners.pt/index.html
O protocolo HTTP tem um número restrito de métodos, como por exemplo GET, POST, HEAD, PUT, DELETE.
O método GET é o usado quando o protocolo HTTP constrói uma requisição de uma página Web a um servidor, que depois passará à camada seguinte da pilha de protocolos.
A mensagem gerada, no nosso caso terá este aspeto:
GET /index.html HTTP/1.1\r\n
Host: www.condominiopartners.pt\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n
Accept-Language: pt-pt,pt;q=0.8,en;q=0.5,en-us;q=0.3\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7\r\n
Keep-Alive: 300\r\n
Connection: keep-alive\r\n
\r\n
ou, com os símbolos de carriage return e mudança de linha traduzidos
GET /index.html HTTP/1.1
Host: www.condominiopartners.pt
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: pt-pt,pt;q=0.8,en;q=0.5,en-us;q=0.3
Accept-Encoding: gzip, deflate
Accept-Charset: ISO-8859-1, utf-8; q=0.7, *; q=0.7
Keep-Alive: 300
Connection: keep-alive
em que a primeira linha é a linha de requisição e as restantes linhas são as linhas de cabeçalho. Como se pode notar, as diferentes linhas são separadas por uma linha em branco. No termo da mensagem existe um corpo de dados, usado no método POST, quando o cliente envia ao servidor uma requisição com elementos de um formulário preenchido, por exemplo.
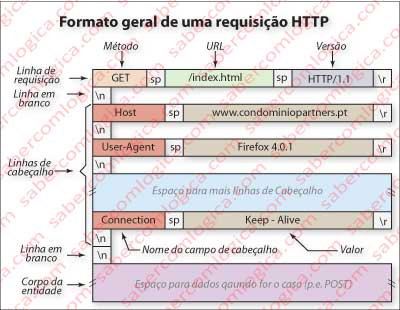
A regra geral de uma mensagem de requisição HTTP é conforme com a Figura 2, que apresenta um quadro esquemático representativo da sua organização.
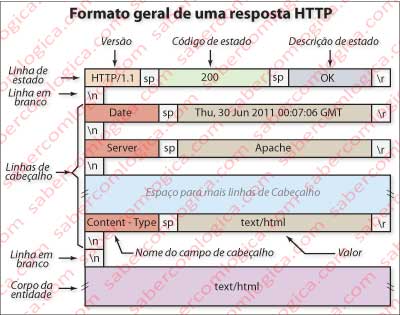
O servidor, ao receber esta requisição na sua camada aplicação, gera uma mensagem HTTP de resposta em que envia ao cliente o objeto que ele requisita, de acordo com a regra geral de uma mensagem de resposta HTTP, conforme com a Figura 3, que apresenta um quadro esquemático representativo da sua organização.
Essa mensagem terá o seguinte aspeto:
HTTP/1.1 200 OK\r\n
Date: Thu, 30 Jun 2011 00:07:06 GMT\r\n
Server: Apache\r\n
Last-Modified: Mon, 31 Jan 2011 12:26:35 GMT\r\n
Accept-Ranges: bytes\r\n
Content-Length: 13822\r\n
Connection: close\r\n
Content-Type: text/html\r\n
\r\n
Line-based text data: text/html
ou, com os símbolos de mudança de linha convertidos:
HTTP/1.1 200 OK
&
Date: Thu, 30 Jun 2011 00:07:06 GMT
&
Server: Apache
&
Last-Modified: Mon, 31 Jan 2011 12:26:35 GMT
&
Accept-Ranges: bytes
&
Content-Length: 13822
&
Connection: close
&
Content-Type: text/html
&
&
Line-based text data: text/html
correspondendo ao mesmo modelo de linhas e sua separação descritos atrás. Neste caso existe um corpo de entidade preenchido, concretamente com 13.822 bytes que constituem o objeto index.html solicitado, descritos no cabeçalho na linha com o título Content-Length.
O nome index.html é o nome por defeito da Home Page de um Site.
Os códigos de estado são genericamente os indicados, ressaltando a título de exemplo alguns dos mais significativos em cada agrupamento:
1XX – Informativos.
2XX – Sucesso.
200 – OK.
3XX – Redirecionamento.
301 – Permanentemente movido.
304 – Não modificado.
4XX – Erro do cliente.
404 – Não encontrado.
5XX – Erro de servidor.
503 – Serviço indisponível.
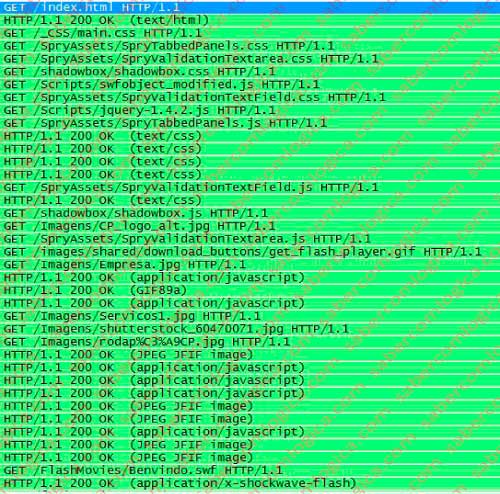
Uma vez recebido pelo Browser (passaremos a chamar assim o cliente HTTP) o ficheiro index.html, da descodificação do mesmo resulta a necessidade de obter do servidor Web todos os objetos para os quais essa folha aponta e que fazem parte integrante da página solicitada.
Serão assim construídas todas as requisições que constam do quadro junto (com GET), a que corresponderão todas as respostas que também constam do mesmo quadro ( Figura 4).
Verifica-se assim o número de mensagens HTTP trocadas entre o Browser e o Web Server para a exibição de uma página Web que poderão facilmente visualizar, bastando para isso seguirem o respetivo hiperligação.
Sugerimos que aproveitem para verem também o código html, css e javascript, usando por exemplo o Firebug do Firefox.
Mas, como fizemos questão de realçar, este é o número de mensagens que serão trocadas durante todo o processo entre as camadas aplicação (HTTP), concretamente 19 requisições e 19 respostas. Ainda agora a procissão vai no adro.
Conexões
Entendemos ser agora o ponto ideal para introduzirmos mais um conceito importante sobre as conexões, que é o facto de poderem ser conexões persistentes ou conexões não persistentes.
Se repararmos agora nas mensagens trocadas entre as máquinas (conforme descritas atrás), verificamos que o Browser indica ao servidor que pretende uma conexão persistente na linha de cabeçalho:
Connection: Keep-Alive
mas o servidor responde-lhe dizendo que não quer esse tipo de conexão, antes uma conexão não persistente, indicando no fim da resposta ao seu pedido que vai fechá-la.
Connection: Close
A diferença fundamental entre os dois tipos de conexão ressalta do próprio nome, isto é, se ela se mantém viva até ao final da conversação ou não.
Quando uma conversação termina e ninguém a fechou, ela cai por si ao fim de algum tempo, concretamente o indicado na linha de cabeçalho:
Keep-Alive: 300
A conexão persistente tem vantagens sobre a não persistente, pois permite que sejam requisitados todos os ficheiros que estão ligados com a página sem ter que estabelecer nova conexão para cada um deles.
O protocolo de estabelecimento e finalização de conexões obriga ao envio de uma série de mensagens entre o cliente e o servidor, como veremos mais adiante e que, para além de consumir mais recursos (buffers e variáveis) no servidor, torna o processo no seu global mais lento.
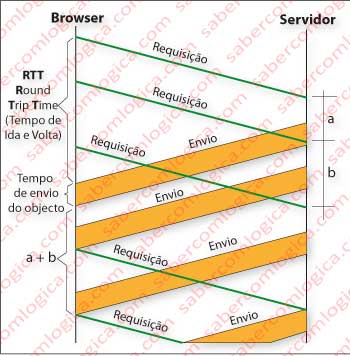
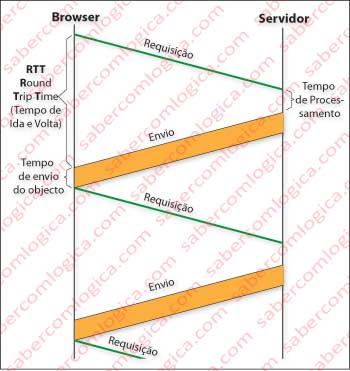
As conexões persistentes podem ser com ou sem paralelismo.
Nas conexões sem paralelismo ou pare e espere, conforme a Figura 5, o cliente espera pela conclusão da resposta a uma requisição para enviar outra requisição. É evidente que a comunicação no total se torna bem mais lenta, porque se vão somar todos os tempos de processamento e envio de todas as mensagens e reconhecimentos.
Nas conexões com paralelismo , conforme a Figura 6, o cliente envia em paralelo (entenda-se este paralelo como sequencial, pois não pode enviar dois pedidos em simultâneo) com a receção de uma requisição as requisições de todos os objetos que pretende. Assim sendo a comunicação fica muito mais rápida pois não se somam todos os tempos de todas as mensagens.
Este conceito entender-se-á muito melhor já de seguida na camada transporte. Já lá vamos.
No nosso caso o servidor não aceitou uma conexão persistente. Caso o Browser não tivesse forma de dar a volta à questão, certamente iríamos estar muito mais tempo à espera que a página aparecesse.
Mas neste caso a maioria dos Browsers resolve o problema lançando novas conexões, uma para cada requisição de objeto imediatamente após verificar a necessidade desse objeto durante a leitura do ficheiro HTML. E foi precisamente isso que aconteceu no nosso caso, como veremos quando percebermos o TCP.