
Da nossa UCP para a realidade
Antes de entrarmos propriamente na descrição de alguns pormenores de uma UCP comercial, vamos introduzir alguns conceitos que nos ajudarão à transição entre a imaginária UCP que serviu de base à sua apresentação e a realidade de uma UCP comercial.
As μops e os Registadores
As μops (micro operações), como já definimos são as operações mais elementares da UCP, que esta realiza sobre os seus Registadores.
Todas as ações que definimos durante a análise da nossa UCP e que se realizavam na sequência da descodificação de um Opcode, na realidade serão μops executadas sobre os Registadores da UCP.
A UCP é provida dos Registadores necessários para poder cumprir todas as suas μops:
- determinar a instrução do programa a ser consultada,
- colocar as instruções a serem pedidas à MI,
- colocar as instruções recebidas,
- colocar os Opcode a serem descodificados,
- colocar os endereços da MD a serem consultados,
- colocar os dados devolvidos pela MD,
- colocar os dados sobre os quais se vão exercer operações,
- etc.
Qualquer operação na UCP resulta de uma μop sobre Registadores,
- executando operações aritméticas ou lógicas com os dados que eles contêm,
- executando deslocações de bits sobre os dados que eles contêm,
- escrevendo dados neles,
- lendo dados deles,
- transferindo dados entre eles,
- etc.
Todas estas μops são executadas de acordo com os sinais de controlo que resultam da descodificação dos Opcode, que encaminham os sinais pelos circuitos do computador de forma a executarem cada uma das μops necessárias para essa instrução.
Foi o que acabámos de ver na nossa elementar UCP, de uma forma simples. Mais uma vez a complexidade vai ser a soma de muitas simplicidades.
A μops são atómicas. i.e. não decomponíveis noutras operações e executam-se num ciclo de clock.
Para já ficamos por aqui quanto a este tema.
O Ciclo de Atividade da UCP
Na UCP imaginária que acabámos de analisar, o Registador PI aponta para o endereço da instrução em código máquina a ser lida (Busca), o Opcode dessa instrução é descodificado (Descodificação) e pela interpretação dos sinais de controlo gerados é executada (Execução) nos diversos elementos da arquitetura da UCP, incluindo a escrita ou leitura de dados num endereço da MD descrito pela constante lida da MI.
Numa mesma operação máquina estes 3 estágios do ciclo de operação da nossa UCP foram percorridos e as μops que cada um deles incluía foram executadas. Serviu para entendermos como um opcode se descodifica em sinais de controlo que vão executar as ações (μops) que farão cumprir a tarefa da instrução.
A realidade de uma UCP comercial é muito diferente, até mesmo pela sua atual enorme complexidade. Mesmo sendo parte da mesma instrução os diferentes estágios do Ciclo da UCP são executados em circuitos específicos para cada um deles em diferentes ciclos de clock.
E cada um dos estágios precisa da informação do anterior para se poder iniciar. Não se pode Descodificar enquanto não se souber o quê. Não se pode Executar enquanto não se tiver o Opcode descodificado nos seus sinais de controlo e definidas as μops a executar. E tudo começa pela Busca, onde se executa um acesso à memória.
A UCP e a Memória
As memórias são circuitos separados do núcleo da UCP e bastante complexos. Tão complexos e tão importantes que vão merecer tratamento em separado em Capítulos que se seguem, envolvendo análises à forma de funcionamento da Memória Principal (MP), das Caches e do Sistema Operativo com a sua Memória Virtual e da grande memória do computador, o Disco Rígido (HDD).
Para já vamos abordar a questão sem pormenores sobre a forma como é feito esse acesso. A UCP fornece os endereços para ler instruções ou para ler e escrever dados e entrega-os à MMU (Memory Management Unit – Unidade de Gestão de Memória), que se encarrega do complexo processo de encontrar e devolver à UCP o que ela procura.
A procura desses valores pela MMU tem latências (tempos de espera e acesso):
- De 7 a 50 ciclos de clock, se a MMU conseguir resolver a procura nos diversos níveis de cache.
- De cerca de 200 ciclos de clock se a MMU tiver que recorrer à MP para resolver a procura.
- De dezenas de milhões de ciclos de clock se a MMU tiver que recorrer ao HDD (Disco Rígido) para resolver a procura.
O que interessa reter é que o acesso à memória para leitura de instruções, a Busca, por estes motivos terá que ser separada dos restantes estágios da UCP, que vão ficar à espera do resultado deste.
A UCP e a ULA
Como pudemos ver quando construímos o circuito de divisão, essa operação faz-se por iterações, uma em cada ciclo de clock. Para a multiplicação vale o mesmo. Apesar de estratégias de lógica entretanto implementadas, que passam mesmo pela paralelização por desmultiplicação de uma operação dentro da propria ULA reiniciando com operandos intermédios, o que permite em cada ciclo iniciar nova operação, quando falamos em 64 bits falamos em latências de muitos ciclos de clock para uma operação.
Portanto, a execução também terá que lidar com latências, quer seja para operações na ULA ou para leituras ou escritas de dados na memória. Assim, também o estágio de Execução vai ter que ser separado dos restantes estágios do ciclo da UCP.
A UCP e a Descodificação
Os processo de descodificação atuais são de uma enorme complexidade, partindo de um conjunto de macro instruções complexas que chegam à UCP para execução, para um conjunto elementar de micro operações executáveis pela UCP.
O processo de descodificação incluí já métodos preditivos que permitem antecipar a execução das instruções recebidas de forma a podê-las lançar em execução fora de ordem e em paralelo.
Em conclusão, pois tudo isto veremos já com maior pormenor, toda a atividade de descodificação se desenvolve através de muitas μops e muitos ciclos e clock. Com latências também, portanto. Então também este estágio de Descodificação deve ser separado dos outros.
A paralelização das Instruções
Já encontrámos 3 estágios de execução de uma instrução que devem ser executados em separado, cada um utilizando diferentes recursos da UCP:
Busca, Descodificação e Execução
Vamos parar aqui, por agora, na nossa transição para a realidade e assumir que cada um destes estágios constitui uma μop e se executa num ciclo de clock. Claro que tal está muito longe da realidade, mas como a complexidade se atinge pela soma de simplicidades, vamos continuar com uma evolução lenta do nosso imaginário, nesta fase para melhor entendermos um novo conceito que permite a execução de diferentes instruções em paralelo e simultâneo, o Pipeline.
Pipeline
Pipeline ou processamento em estágios, é a técnica pela qual uma UCP executa as instruções, não de uma forma estritamente sequencial mas em paralelo ou em estágios, de acordo com os recursos disponíveis.
No nosso estado presente de evolução, uma instrução é executada por 3 μops – busca, descodificação e execução, cada uma usando recursos próprios e executando-se num ciclo de clock.
O princípio base do pipeline consiste em iniciar uma nova μop a cada ciclo de clock, utilizando para isso recursos disponíveis na UCP.
Quando a Busca de uma instrução se conclui inicia-se a sua Descodificação e ficam disponíveis os recursos para Busca. Quando a Descodificação se conclui inicia-se a Execução e ficam disponíveis os recursos para Busca e Descodificação. Normalmente só de 3 em 3 ciclos se iniciaria uma instrução, cada uma após o cumprimento integral da anterior. Mas através do pipeline uma nova instrução pode ser iniciada utilizando os recursos disponíveis. Então:
Quando a 1ª instrução estiver no estágio de Execução, tendo deixado livres os circuitos de Busca e Descodificação, uma 2ª instrução estará já no estágio de Descodificação, tendo deixado livre o circuito de Busca e uma 3ª instrução estará já no estágio de Busca.
Assim, com o pipeline conseguimos repetir a proeza da nossa UCP executando todos os estágios de Busca, Descodificação e Execução em simultâneo no mesmo ciclo de clock. Só que agora não são os 3 estágios da mesma instrução mas um dos diferentes estágios de cada uma de 3 instruções.
O objetivo ideal e otimista do pipeline é o total preenchimento dos tempos da UCP e assim conseguir concluir uma instrução em cada ciclo de clock, como na Figura 41 – Amostra da esquerda, contrariamente à situação de execução sequencial em que só concluía uma instrução de 3 em 3 ciclos, como na Figura 41 – Amostra central.
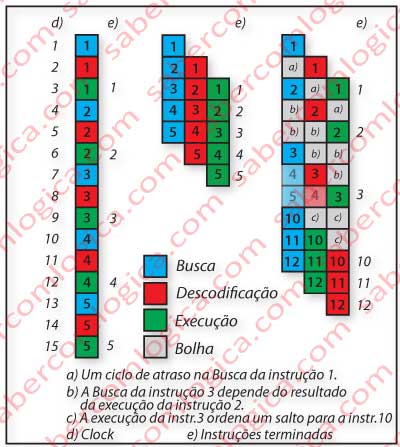
Pipelining ou Processamento em estágios.
Mas evidentemente tal não é possível, pois muitas situações podem provocar atrasos ou perdas na cadeia de estágios em execução, como se pretende ilustrar na Figura 41 – Amostra da direita em três possíveis situações:
a. -Existe um atraso na consulta à memória e a instrução 1 demora mais 1 ciclo a concluir a busca. Toda a sequência na cadeia de estágios vai atrasar igualmente 1 ciclo
b. -A instrução 3 depende do resultado da execução da instrução 2. O seu início vai ter que aguardar pela conclusão da 3, gerando uma quebra de 2 ciclos em toda a cadeia.
c. -A instrução 3 executa um salto para a instrução 10, pelo que todas as partes de instruções executadas em cadeia sequencial são ignoradas recomeçando de novo a partir do final da instrução 3. A cadeia de estágios é esvaziada e é recomeçada de novo.
Em qualquer das situações são gerados espaços de tempo não utilizados a que se chama Bolhas. Quando as instruções em pipeline se encontram todas em espera por latências das operações que cada uma ordenou, a operação em pipeline pára, ou entra em Stall, o que corresponde a uma série de ciclos seguidos preenchidos só com bolhas.
Tanto as bolhas como o stall são críticos para a performance de uma UCP, pelo que o objetivo da conceção de um pipeline é a criação de condições para reduzir a sua existência ao mínimo.
Avançando um pouco mais em relação à realidade e considerando as latências de acesso à memória, os tempos de realização de certas operações na ULA ou mesmo o tempo de um complexo processo de descodificação, é fácil imaginar que rapidamente o pipeline de uma UCP será um autêntico mar de bolhas e que muito provavelmente estará durante muito mais tempo em Stall do que a realizar operações.
Em resumo, os recursos disponíveis vão ser utilizados numa percentagem muito pequena das suas capacidades. Para isso os fabricantes de UCP estão presentemente a concentrar muitos dos seus esforços na paralelização de instruções.
Vamos avançar na aproximação à realidade. Os estágios do ciclo da UCP não são evidentemente μops mas são decomponíveis em muitas μops. Cada estágio do pipeline é composto não por estágiCada estágio do pipeline é composto não por estágios do ciclo da UCP mas por operações que utilizem recursos disponíveis e que se executem num ciclo de clock. São as μops os seus componentes.
Para aumentar o número de estágios de um pipeline é preciso lançar muitas μops para preencher esses estágios. Para lançar muitas μops é necessário começar a executar muitas instruções em simultâneo, portanto a execução de instruções fora de ordem, o que pressupõe que a reordenação das μops seja refeita após a sua execução.
Para que tal possa ser feito com o menor número de bolhas, é preciso efetuar análise prévia às instruções de forma a que seja possível prever a existência de saltos.
Efetivamente, de nada valerá estar a executar instruções por antecipação se entretanto uma delas incluir um salto que entretanto se verifica sem ter sido previsto. Todo o trabalho feito para além desta será perdido e teremos um enorme stall no pipeline.
Bom, pelo que já vimos temos que:
- Aumentar o número de μops em execução simultânea
- Aumentar o número de estágios do pipeline
- Executar instruções fora de ordem.
- Reordenar as μops executadas fora de ordem de acordo com a sequência natural das instruções.
- Fazer previsão de saltos nas instruções executadas fora de ordem.
- Criar capacidade de armazenamento (Buffers) temporário nas diversas fases.
E mais terá que ser feito, mas só isto já basta para percebermos a enorme quantidade de lógica que tem que estar associada com estes processos. E lógica em hardware significa transístores.
A dimensão dos transístores
O investimento em paralelização implica um enorme aumento na necessidade de transístores no chip da UCP para que toda a lógica associada ao que vimos referindo possa ser executada.
Já há algum tempo que o constante aumento da frequência de clock de uma UCP deixou de ser o objetivo principal das equipas de investigação dos seus fabricantes. A redução da dimensão dos transístores e a sua consequente maior proximidade começou a levantar o problema da transmissão de ruído entre as linhas dos circuitos, assim deturpando a informação que neles circula.
Assim, a redução da dimensão dos transístores, como forma de aumentar do seu números na mesma área de circuito e o aumento da frequência do clock, passaram a estar em antagonismo. Era necessário dar a preferência prioritária a uma das duas escolhas
- continuar a aumentar as frequências de clock nos circuitos da UCP ou
- continuar a reduzir a dimensão dos transístores, permitindo a inclusão de mais no mesmo espaço.
De que vale ter um carro que atinge os 300 Km/h se andarmos com ele em ruas engarrafadas? Se nada fizermos para tornar as estradas mais fluídas, o mais que conseguimos é chegar mais depressa aos engarrafamentos.
Pois com a UCP passa-se o mesmo. Se nada se fizer para evitar as bolhas, por muito que se aumente a frequência com que os sinais circulam nos seus circuitos, o que vamos conseguir é chegar mais depressa ao stall.
O custo de produção de uma bolacha de silício com circuitos integrados é contabilizado por área de bolacha e não pelo número de transístores na mesma inseridos.
O grande investimento dos construtores de UCP no sentido da paralelização máxima da execução de instruções com a consequente necessidade de aumentar o número de transístores para conterem a lógica que a suportará, favorece claramente a segunda escolha.
O objetivo é conseguir a execução de uma macro instrução por ciclo de clock. Parece elementar. Mas é uma tarefa monstruosa.
Está na altura de passarmos ao nosso caso de estudo.