
NTFS – Atributos (continuação)
Atributos não residentes e sem nome
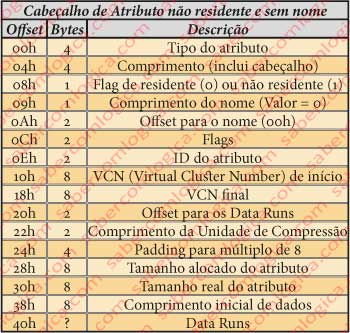
Cabeçalho de Atributo não residente e Sem Nome
Relembramos que no artigo anterior íamos passart para a descrição do atributo $DATA e passámos a sua desxcrição para este artigo por ele ser um atributo não residente e sem nome. A estrutura do cabeçalho deste atributo é diferente da usada até aqui, pelo que vamos desde já juntar uma tabela tipo para o cabeçalho dos atributos com esta classificação na figura 20. E vamos passar de imediato ao atributo $DATA.
Atributo $DATA
Como atributo não residente, a sua composição neste ficheiro limita-se ao cabeçalho, pois os dados encontram-se em qualquer local exterior a este ficheiro. Por essa razão vamos fazer a descrição deste cabeçalho dentro do próprio atributo. Vamos começar por analisar os campos coincidentes com o cabeçalho anterior. Na figura 21 representa-se a edição hexadecimal do cabeçalho do atributo $DATA do ficheiros $AttrDef. Este atributo é o que está representado sobre fundo castanho na figura 32. O cabeçalho é decomposto nos seus diversos campos com fundos de cores diferentes, conforme descritos na tabela. Assim, pode-se ler que:
É um atributo do tipo 80h, ou seja, é um atributo $DATA.
O comprimento do atributo é de 48h, começando o próximo atributo no offset 4068h + 48h = 41B0h.
O atributo não é residente, o que desde já significa que os seus dados não se encontram aqui, neste ficheiro, mas algures no disco.
As Flags dos Bytes 4174h e 4175h podem ter os seguintes significados (só o atributo Data pode ser comprimido ou esparso e só se for não residente, pelo que aqui se justifica esta introdução):
- 0001h – Comprimido.
- 4000h – Encriptado.
- 8000h – Esparso.
- 0000h – Não tem nenhuma destas características.
- No nosso caso (0000h) não tem nenhuma das características.

É um atributo sem nome.
O atributo tem ID=5.
Agora vamos analisar o que é novo e diferente neste cabeçalho.
Os 8 bytes de 4178h a 417Fh que indicam o Virtual Cluster Number de início, No nosso caso é 0.
Os 8 bytes de 4180h a 4187h que indicam o Virtual Cluster Number final, No nosso caso também é 0, devendo portanto o número de clusters do ficheiro ser de 1.
Os 2 bytes em 4188h e 4189h que indicam o offset para os Data Runs. Já vamos perceber o que é isto. No nosso caso o offset é 40h, pelo que o seu início será no offset 4168h + 40h = 41A8h.
Os 2 bytes em 418Ah e 418Bh que indicam o comprimento da unidade de compressão, que será uma potência de 2 em Clusters. No nosso caso é 0, o que significa descomprimido.
Os 4 bytes de 418Ch a 418Fh que correspondem a um Padding a 8 Bytes, Isto significa o preenchimento a zeros do número de Bytes necessário para acertar a simbologia dos Bytes a um múltiplo de 8, neste caso.
Os 8 bytes de 4190h a 4197h representando o tamanho para alocação do ficheiro. No nosso caso é 1000h, ou seja 4.096 bytes, 1 cluster.
Os 8 bytes de 4198h a 419Fh representando o tamanho real do ficheiro. No nosso caso é 0A00h, ou seja 2.560 bytes.
Os 8 bytes de 41A0h a 41A7h representando o tamanho inicial da corrente de dados. Será igual ao valor anterior a menos que por qualquer motivo tenha sido aumentado. É o nosso caso. É igual ao anterior.
O byte 41A8h é onde começa a a cadeia de Data Runs. É aqui que se define onde estão os dados deste ficheiro.
Os 3 bytes de 414Dh a 414Fh são um padding a um múltiplo de 8 bytes.
Data Runs? O que é isso?
Data Run
Os Data Run são uma forma virtual de indexar clusters, servindo portanto neste caso, para indexar os clusters onde se encontram os dados não residentes. A indexação por data runs tem que ser descodificada para poder ser entendida. Vamos fazer a descodificação do data run do nosso caso, que como já vimos tem início no offset 41A8h. Neste offset verificamos a seguinte cadeia de bytes
31 01 41 00 01 00 00 00
que vamos descodificar.
O Byte 31 tem que ser decomposto nos seus dois dígitos, sendo que :
- O meio byte de ordem mais baixa, o 1, representa o número de bytes a seguir a este que determinam o tamanho em clusters do bloco de dados que este data run define. É 1 byte (1), e o seu valor é 01 significando que o bloco de dados tem o tamanho de 1 cluster.
- O meio byte de maior ordem, o 3, designa o número de bytes seguintes aos que definem o tamanho, que definem o offset onde se inicia o bloco de dados que este data run define. São 3 bytes (3), os 3 bytes a seguir a 01, que são os bytes 41 00 01, que definem o offset em clusters do bloco de dados. Esse offset é 010041h, ou seja 65.601 (clusters) x 8 (setores/cluster) x 512 (bytes/setor) = 10041000h.
A dimensão de um data run é indicada pelo primeiro byte, isto é, o byte 31 diz que, para além dele, o data run tem 1 + 3 = 4 bytes. A seguir a este conjunto começa outro data run, caso o primeiro byte não seja 00, o que indicará a não existência de mais data runs. No nosso caso é 00, o que significa que não há mais data runs a definirem o ficheiro, isto é, a totalidade do ficheiro está contida no bloco de dados definido pelo primeiro data run. Significa também que os dados deste ficheiro não estão fragmentados.
Então, um data run é um indicador da posição e dimensão de um determinado bloco de dados de um ficheiro. E a cadeia de data runs define os blocos que constituem os dados de um ficheiro.
Quanto maior o número de data run, maior a fragmentação do ficheiro, uma vez que cada data run indica um dos muitos blocos que compõem os dados do ficheiro.
Para ficheiros muito longos e muito fragmentados, pode acontecer que a cadeia de data run não caiba dentro do espaço do ficheiro, sendo então definida uma extensão para o mesmo onde a respetiva cadeia continua. Daí que a dimensão em bytes dos Data Run seja variável, não sendo por isso indicado um valor para a mesma na tabela anterior.
Mais um pouco de Endianness
Certamente repararam que dividimos um byte em dois meios bytes e lemos o de menor ordem no fim e o de maior ordem no princípio.
Mas isto assim não é little endian, certo?
Pois não e por isso mesmo fizemos aqui esta interrupção. O caso é que o byte pode ter os seus bits escritos na forma little endian, mas nós não o estamos a ler em bits.
O que nós estamos a ler é a tradução feita pelo editor hexadecimal do conjunto de bits que compõem um byte para a sua forma hexadecimal.
Portanto, a partir daqui damos-lhe a forma que quisermos, concretamente a que nos é própria a nós humanos. Da esquerda para a direita equivale a do princípio para o fim. É também dessa forma que a representação hexadecimal do byte tem que ser feita. O editor hexadecimal até sabe a CPU com que está a trabalhar. Identifica-a logo que é instalado. Portanto o conjunto de bits que compõem o byte ele sabe traduzir, porque são indivisíveis no seu significado como byte.
Agora quanto aos bytes, ele já não sabe nada da intenção com que foram escritos e por isso apresenta-os separados e pela ordem que os lê.
Continuemos.
Descodificado o nosso único Data Run, vamos então ao offset 10041000h verificar os dados do cluster que aí começa e analisar os mesmos, através do quadro que juntamos, com o conteúdo útil desse cluster. Por uma questão de razoabilidade na dimensão do quadro, representamos as linhas a zeros entre offset distantes, com uma linha a ponteado.
Ora, os dados deste ficheiro são aquilo que procuramos desde o princípio: a lista e a definição de todos os atributos.
Finalmente a Lista e Definição dos atributos

Para análise deste quadro devemos usar a tabela de ocupação de espaços da figura 22, sendo que cada definição de atributo ocupa A0h, ou 160 bytes.
Vamos ler em pormenor e de acordo com a tabela de ocupação referida, os campos 1º atributo referido na lista de atributos da figura 23, obtida através do editor hexadecimal.
Esta figura representa a leitura feita pelo editor hexadecimal dos dados não residentes do atributo $DATA do ficheiro $AttrDef, que como já referimos é a lista de atributos e sua principais definições.
Os restantes atributos serão lidos sucintamente com base nos mesmos pressupostos.
A linha ponteada dentro de cada atributo, representa a totalidade das linhas com os bytes a 0.
O 1º Atributo é o $STANDARD_INFORMATION
Os primeiros 128 Bytes de 10041000h a 1004107Fh contêm o nome do atributo com o texto descrito, que ocupa na realidade 42 Bytes (21 carateres x 2 bytes). A forma como é feita a leitura do texto já foi analisada. Agora pode ser comparada a interpretação por Unicode (o texto que escrevemos para o nome) com a interpretação por ANSI, na figura 23.
Os 4 bytes de 10041080h a 10041083h definem o tipo do atributo, 10h.
Os 4 Bytes de 10041084h a 10041087h indicam a regra de apresentação. É 0 para este atributo.
Os 4 Bytes de 10041088h a 1004108Bh indicam a regra de ordenação da junção dos registos. É 1 para este atributo.
Os 4 Bytes de 1004108Ch a 1004108Fh são Flags, que podem definir:
- 02h – Indexado
- 40h – Residente
- 80h – Não residente
em que as duas últimas se podem combinar com a primeira. Para este atributo é 40h = residente.
Os 8 Bytes de 10041090h a 10041097h definem o tamanho mínimo do ficheiro. É 30h ou 48 bytes, para este atributo.
Os 8 Bytes de 10041098h a 1004109Fh definem o tamanho máximo do ficheiro. É 48h ou 72 bytes, para este atributo
Seguindo o mesmo método, vamos analisar sucintamente os restantes atributos definidos. Vamos olhar essencialmente para aquilo que muda entre os atributos: o nome o tipo, o tamanho mínimo, o tamanho máximo e a flag.
O 2 º Atributo é o $ATTRIBUTE_LIST,
- tem o tipo 20h,
- é não residente (80h),
- com tamanho mínimo de 0 e
- com o tamanho máximo de FFFFFFFFFFFFFFFFh, correspondente a -1, o que significa com tamanho máximo não limitado.
O 3º atributo é o $FILE_NAME,
- com o tipo 30h,
- residente indexado (42h),
- com o tamanho mínimo de 42h ou 66 bytes e
- com o tamanho máximo de 242h ou 578 bytes.
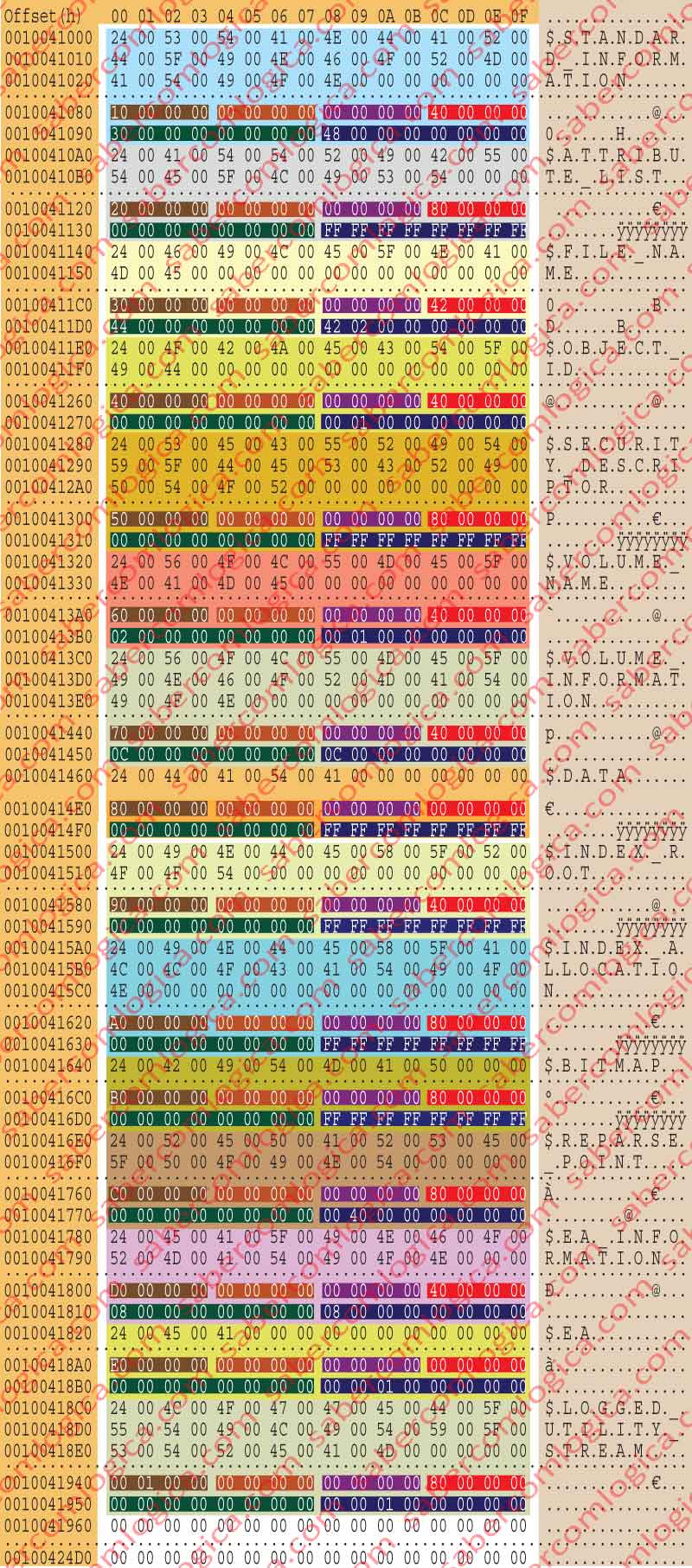
O 4º atributo é o $OBJECT_ID,
- com o tipo 40h,
- residente (40h),
- com o tamanho mínimo de 00h e
- com o tamanho máximo de 100h ou 256 bytes.
O 5º atributo é o $SECURITY_DESCRIPTOR,
- com o tipo 50h,
- não residente (80h),
- com o tamanho mínimo de 0 e
- com o tamanho máximo não limitado.
O 6º atributo é o $VOLUME_NAME,
- com o tipo 60h,
- residente (40h),
- com o tamanho mínimo de 2h e
- com o tamanho máximo de 100h.
O 7º atributo é o $VOLUME_INFORMATION,
- com o tipo 70h,
- residente (40h),
- com o tamanho mínimo de Ch ou 12 bytes e
- com o tamanho máximo de Ch ou 12 bytes(fixa de Ch).
O 8º atributo é o $DATA,
- com o tipo 80h, podendo ser
- residente ou não residente (00h), porque os ficheiros inferiores a 1 KB, sem nome ou só com nome DOS, podem residir no ficheiro, sendo indexados,
- com o tamanho mínimo de 0 e
- com o tamanho máximo não limitado.
O 9º atributo é o $INDEX_ROOT,
- com o tipo 90h,
- residente (40h),
- com o tamanho mínimo de 0 e
- com o tamanho máximo não limitado.
O 10º atributo é o $INDEX_ALLOCATION,
- com o tipo A0h,
- não residente,
- com o tamanho mínimo de 0 e
- com o tamanho máximo não limitado.
O 11º atributo é o $BITMAP,
- com o tipo B0h,
- não residente,
- com o tamanho mínimo de 0 e
- com o tamanho máximo não limitado.
O 12º atributo é o $REPARSE_POINT,
- com o tipo C0h,
- não residente,
- com o tamanho mínimo de 0 e
- com a máxima de 4000h ou 16384 bytes.
O 13º atributo é o $EA_INFORMATION,
- com o tipo D0h,
- residente,
- com o tamanho mínimo de 08h ou 8 bytes e
- com o tamanho máximo de 08h ou 8 bytes (fixa de 08h).
O 14º atributo é o $EA,
- com o tipo E0h,
- residente ou não residente (00h), tal como com $DATA
- com o tamanho mínimo de 0 e
- com o tamanho máximo de 10000h ou 65536 bytes.
O 15º atributo é o $LOGGED_UTILITY_STREAM,
- com o tipo 100h,
- não residente,
- com o tamanho mínimo de 0 e
- com o tamanho máximo de 10000h.
E no ponto onde deveria começar o próximo atributo passam a estar zeros. Acabou a leitura dos dados.
Atributo $BITMAP
Como é um atributo não residente e sem nome, a leitura do seu cabeçalho é feita pela tabela da figura 12-20, que já serviu para o atributo $DATA.
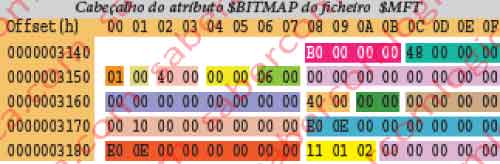
Este atributo é o 4º atributo do ficheiro de metadados $MFT, e consta da imagem da sua edição hexadecimal na figura 12-34 sobre sombreado castanho.
Desse pedaço, fizemos uma representação em pormenor, com a decomposição dos campos do cabeçalho e juntámos aqui na figura 12-24, sendo que a sua interpretação deve ser feita como anteriormente para o atributo $DATA. Assim:
- Tem o tipo B0h.
- Tem o comprimento de 48h, portanto o próximo atributo terá início no offset 3148h + 48h = 3190h.
- É não residente.
- Tem ID=6.
- O VCN inicial e final são 0, pelo que só terá 1 cluster.
- O offset para a cadeia de data runs é 40h, devendo portanto iniciar-se no offset 3148h + 40h = 3188h.
- O tamanho alocado do atributo é 1000h = 4.096 Bytes, ou seja, um cluster.
- O tamanho real do ficheiro é 0EE0h = 3.808 Bytes.
- O tamanho da corrente inicial de dados é 3.808 Bytes, não tendo portanto havido alterações.
- A cadeia de data runs é como segue:
11 01 02 00 00 00 00 00
Vamos interpretar a cadeia de Data Runs.
- Tem 1 byte que define o seu tamanho e esse byte, que fica logo a seguir ao meio byte 1, tem o valor 01. Portanto ocupa 1 cluster.
- Tem 1 byte que define o seu offset em clusters e esse byte, que fica logo a seguir ao byte 01, tem o valor 02. Isto significa que tem início no final do 2º cluster, isto é, no offset 2 x 512 x 8 = 8.192 = 2000h.
- O comprimento deste data run é de 3 bytes ( 1+1+1). Como o byte nessa posição tem o valor 00, este é o último e o único data run.
Resumindo: A cadeia é composta por um data run que nos indica que o ficheiro ocupa 1 cluster e que se inicia no offset 2000h.
Este tipo de atributo, que tal como o nome diz é um mapa de bits, é normalmente utilizado em duas situações: em Index e no ficheiro $MFT.
- Em Index, os bits mostram quais as entradas em uso, sendo que cada bit representa um VCN do Index Allocation.
- No $MFT, o campo de bits mostra, através dos seus bits, quais são as entradas da MFT que estão livres ou ocupadas.
Mas porquê mais esta informação, uma vez que cada entrada da MFT tem assinalado se está ou não em uso?
Um mapa de bits é uma sequência de bits, tantos quantos os elementos que pretendem representar, em que cada bit representa cada um desses pretendentes a representado. O seu estado a 1 ou 0 indica se esse representado está ou não no estado que se pretende definir.
Por exemplo: Admitamos que se pretende representar o estado de ocupado ou livre de um conjunto de 8 entradas de um INDEX. Teremos então um mapa de bits com 8 bits 0 1 0 0 0 11 0 que indicam que as entradas 6, 2 e 1 estão ocupadas e que as entradas 7, 5, 4, 3 e 0 estão livres.
Como no caso corrente estamos a analisar o atributo $BITMAP do ficheiro $MFT, estamos a localizar o mapa de bits das entradas da MFT. Percebe-se assim que a identificação do estado das entradas da MFT por este processo evita a leitura em disco de todas as entradas uma a uma, para identificar quais estão livres e ocupadas, o que seria extremamente moroso. É muito mais rápido verificar uma cadeia de bits do que uma tabela inteira.
Os atributos que se seguem têm estruturas de cabeçalhos diferentes, pois têm classificações diferentes em termos de residência e nome. Por isso vamos apresentar os seus cabeçalhos e fazer a descrição desse cabeçalho dentro de cada um dos atributos. Eles são referenciados na descrição do ficheiro de metadados . (ponto), o diretório raiz. A edição hexadecimal desse diretório encontra-se na figura 35, onde estão os valores tipo que vamos analisar para estes atributos.