
Ficheiros de Metadados da MFT
Ficheiro $AttrDef

Vimos aquando da análise ao PBS (Partition Boot Sector) que a MFT se iniciava no offset 3000h. Sendo o ficheiro $AttrDef a 5ª entrada da MFT, como se pode ver na figura 6, alguns artigos atrás (siga o link).
1 KB, ou 1.024 bytes, representam um offset de 400h. Tendo 400h de offset por entrada e 4 entradas antes dele, o $AttrDef deverá iniciar-se no offset 3000h+4x400h=4000h.
Deslocando-nos para esse offset, aí encontramos o nosso ficheiro, cuja edição hexadecimal está na figura 32.
O ficheiro $AttrDef ocupa os dois setores 32 e 33, do offset 4000h ao 43FFh e é composto por duas partes:
- o descritor geral e
- os diversos atributos que lhe são próprios.
Os bytes de 4000h a 402Fh correspondem ao descritor de ficheiro, já foi analisado na apresentação genérica do descritor de ficheiro. Tem o tamanho de 30h ou 48 bytes.
Os bytes de 4030h a 4077h correspondem ao atributo $STANDARD_INFORMATION, já analisado na descrição genérica do atributo. Tem o tamanho de 48h ou 72 bytes.
Os bytes de 4078h a 40E7h correspondem ao atributo $FILE_NAME, já analisado na descrição genérica do atributo. Tem a dimensão de 70h ou 112 bytes.
Os bytes de 40ED8h a 41678h correspondem ao atributo $SECURITY_DESCRIPTOR, já analisado na descrição genérica do atributo. Tem o tamanho de 80h ou 128 bytes.
Os bytes de 4168h a 41AFh correspondem ao atributo $DATA, já analisado. Tem o tamanho de 48h ou 72 bytes.
Os 4 Bytes de 41B0h a 41B3h – FF FF FF FF – são o terminador do ficheiro $AttrDef
Na tabela da figura 32, resumimos a constituição essencial do ficheiro $AttrDef.
Ficheiro $MFT
O cabeçalho ou descritor deste ficheiro, seguindo a sua tabela descritiva que está na figura 7 e a sua edição hexadecimal na figura 34 diz-nos que:
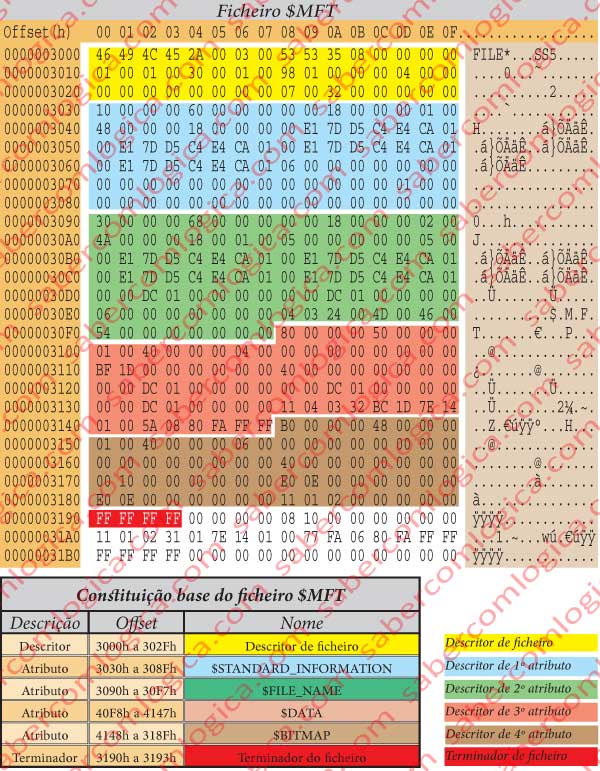
- A sua assinatura é FILE.
- O Offset para a update sequence é 2Ah.
- A update sequence tem 3 palavras de comprimento.
- O nº de sequência do Log File é 08535335h.
- O seu número de sequência é 1.
- Hard Link count é 1.
- O offset para o 1º atributo é 30h.
- As flags indicam que o ficheiro está em uso.
- O tamanho real do ficheiro é 0198h=408 Bytes.
- O espaço alocado para o ficheiro é 400h=1024 Bytes.
- Este é o ficheiro base.
- O ID do próximo atributo a entrar é 7.
- O update sequence number é 32 00.
- A update sequence array é 00 00 e 00 00.
- O primeiro atributo inicia-se em 3030h.
O 1º atributo é um $STANDARD_INFORMATION, correspondente ao tipo 10h. De acordo com as tabelas das figuras 10 e 13, respetivamente para o cabeçalho e para o atributo e os valores do corpo do atributo no quadro da figura 34 com a edição hexadecimal do ficheiro $MFT que o contém, obtemos a informação:
- O seu comprimento é de 60h (96 bytes), começando o próximo atributo em 3030h + 60h = 3090h.
- É residente,
- O comprimento do nome é 0.
- O offset para o nome é 18h. Sem nome, portanto.
- O ID do atributo é 1.
- O comprimento dos dados do atributo é 48h (72 bytes).
- O offset para os dados do atributo é 18h.
Os dados do atributo dão-nos a data/hora de criação e alteração do ficheiro, de alteração da MFT e da última leitura do ficheiro e mais algumas que agora não nos interessa avaliar para o nosso objetivo.
O segundo atributo é um $FILE_NAME, correspondente ao tipo 30h. Usando as tabelas das figuras 12-10 e 12-15, respetivamente para o cabeçalho e para o atributo, e os valores do corpo do atributo no quadro da figura 12-34 com a edição hexadecimal do ficheiro $MFT que o contém, obtemos a informação:
- O seu comprimento é de 68h (104 bytes), começando portanto o próximo atributo em 3090h + 68h = 30F8h.
- É residente.
- Tem ID=2.
Refere-se ao diretório Pai, que se encontra na entrada 5 da MFT ( o ficheiro . ).
Para além das datas referidas para o atributo anterior, que este também nos fornece para ele próprio, fornece-nos o nome do ficheiro a que pertence e que é, como bem sabemos, $MFT.
O terceiro atributo é um $DATA, que é do tipo 80h. Usando o descritor de cabeçalho deste atributo não residente e sem nome, na figura 12-20 e os valores do corpo do atributo no quadro da figura 12-34 com a edição hexadecimal do ficheiro $MFT que o contém, obtemos a seguinte informação:
- Tem o comprimento de 50h, começando portanto o atributo seguinte no offset 30F8h + 50h = 3148h.
- Não é residente.
- Tem o ID=4.
- O VCN inicial é 0.
- O VCN final é 1DBFh = 7.615.
- O tamanho real do atributo é de 01DC0000h= 31.195.136 Bytes.
- O tamanho alocado é igual.
- O tamanho inicial da corrente de dados também é igual. Ainda não foi alterado portanto.
- O offset para os data runs é 40h, o que significa que estes começam no offset 30F8h + 40h = 3138h e o seu valor é 11 04 03 32 BC 1D 7E 14 01 00 …
Aos dados deste atributo corresponde a definição, dimensão e localização da MFT (Master File Table) que vamos já analisar de seguida
O quarto atributo é um $BITMAP, correspondente ao tipo B0h. A descrição deste atributo está feita na sua apresentação genérica. Só fazemos sobressair aqui que é não residente e que os seus dados ocupam um Cluster a partir do offset 2000h. Aos dados deste atributo corresponde o mapa de bits que representa as entradas da MFT, em que cada bit define o estado de ocupada ou livre de uma entrada.
A Master File Table (MFT)
A Tabela Mestre de Ficheiros é a base do NTFS. Cada ficheiro, cada índice (que para o NTFS é um ficheiro) tem uma entrada na MFT, onde ele é definido e guardado se for suficientemente pequeno para caber em 1 KB ou onde a sua localização em disco é apontada.
Esta é a grande diferença do NTFS. Encontrada a entrada do ficheiro na MFT, está na grande maioria dos casos encontrada a totalidade do ficheiro. E a procura na MFT, como é feita por indexações sucessivas em árvore, não se torna mais lenta devido ao tamanho do HDD, antes devido a um elevado número de níveis de subdivisão em Diretórios.
Os data runs, que dão a localização e tamanho da MFT,
11 04 03 32 BC 1D 7E 14 01 00 …
dizem-nos que:
Estamos perante dois data runs, o que significa que a MFT se encontra em duas localizações. Assim:
O primeiro data run é:
11 04 03
- 1 Byte para o comprimento – 04 Clusters ou 16.384 Bytes a partir de
- 1 Byte para o Offset – 03 Clusters, portanto inicia-se em 3000h.
E o segundo data run é:
32 BC 1D 7E 14 01
- 2 Bytes para o comprimento – 1DBC h = 7.612 Clusters ou 31.178.752 Bytes a partir de
- 3 Bytes para offset – 01147E h = 70.782 Clusters por referência ao offset do 1º bloco, ou seja, 1147E000h+ +3000h = 11481000h.
E acabaram os data runs:
O byte que fica após os 5 bytes (3+2) que seguem o byte 32 é 00, o que significa que acabaram os data runs.
Portanto, a MFT encontra-se dividida em dois blocos em zonas distintas do volume.
- O primeiro bloco de dados é exatamente a posição em que se encontra o ficheiro $MFT, aquele que estamos a analisar, com início em 3000h. Mas é também o offset onde se inicia o conjunto de entradas da MFT que contém os ficheiros de metadados, conforme se pode ver na tabela da figura 6, onde $MFT é o primeiro, a entrada 0. Este bloco vai dispor assim de 16 entradas, equivalentes aos seus 4 Clusters de tamanho, onde vão estar os ficheiros de metadados, aqueles que começam com $, conforme se pode ver na figura referida.
- O segundo bloco de dados inicia-se no Offset 11481000h e tem 7.612 Clusters de tamanho. Este será o bloco de dados onde vão estar as entradas para os nossos ficheiros e índices, que começam na entrada 24, mais uma vez como se pode ver na figura 12-6.
A soma em Bytes dos dois blocos (31.195.136) tal como a soma de clusters dos dois blocos (7.616) corresponde ao que acabámos de ler através do quadro hexadecimal do cabeçalho do atributo. O endereçamento em VCN (Virtual Cluster Number) para este ficheiro é feito desde o VCN 0 até ao VCN 7615, tal como se podia retirar da leitura do referido quadro.
Está assim identificada e localizada a MFT para o sistema de ficheiros deste volume.
O espaço alocado para a MFT é atribuído aquando da formatação da partição onde o SO está instalado. No entanto, é reservado um espaço em disco anexo ao alocado para futuras expansões da MFT e esse espaço é por hábito bastante generoso, pois o pior que pode acontecer à performance de um sistema é a fragmentação da MFT, para a qual qualquer solução é bastante complexa.
Só para criar uma noção da dimensão de que estamos a falar, um dos Volumes do PC em que estamos a produzir este documento terá perto de 2 milhões de ficheiros e diretórios, o que só por si implica uma MFT com mais de 2 GB de tamanho. Será o caso de muitos que só utilizam o volume C: para todos os seus ficheiros.
Vamos avançar mais um pouco e já vamos perceber o porquê da complexidade de desfragmentar uma MFT.
Ficheiro $LogFile
Este ficheiro está na terceira entrada da MFT, logo inicia-se no offset 3000h + 2 x 400h = 3800h. É usado pelo sistema para um registo imediato e rápido de todas as transações.
À existência e utilização destes ficheiros chama-se Journalling. A sua função é garantir a consistência do sistema de ficheiros.
Estes ficheiros não são úteis ao nosso objetivo, daí não irmos fazer a sua descrição em pormenor. No entanto, devido à sua importância vamos tentar de uma forma resumida dar a entender o que são e o que fazem.
Os HDD têm uma cache SRAM de acesso rápido, onde mantém os últimos ficheiros acedidos e/ou alterados, para uma maior rapidez de acesso nas procuras em disco. Mas essa cache, como memória SRAM (Static Random Access Memory), é volátil. Então, se acontecer um crash do computador com dados em cache por registar, o sistema fica inconsistente. A CPU foi informada sobre o sucesso de determinados registos que afinal não vão estar no HDD, o que pode ser muito grave.
Sendo assim, devemos escrever de imediato no HDD qualquer alteração que se efetue sobre um ficheiro.
Pois, mas assim lá se vai a eficiência da cache.
É preciso atender à enormidade de registos que é preciso efetuar quando se altera um ficheiro.
É ele próprio, a indicação do seu tamanho, se for alterado, a alteração dos data runs, a alteração da sua descrição nos Index Buffers se mudou de posição, a alteração dos mapas de bits, etc.
As cabeças vão-se fartar de passear sobre os pratos do HDD para registar uma simples alteração ao ficheiro. Se a CPU tem que ficar à espera da confirmação para prosseguir com o seu trabalho, lá se vai a performance.
Então e se o crash se der a meio de todos estes registos na MFT ?
Aí o problema já não é o facto de a CPU ser informada de que aconteceu algo que não aconteceu, mas de inconsistência do próprio sistema de ficheiros, isto é, certas partes da sua descrição foram informadas de algo que com ele aconteceu e outras não. Por exemplo, a MFT foi avisada de que o ficheiro foi alterado e ele na realidade não o foi.
Mas então, como resolver a questão?
Bem, uma coisa é certa. Quando se informar a CPU de que o registo foi efetuado, temos que ter a garantia de que foi mesmo. E se houver um corte a meio do registo temos que poder reconstruir tudo de novo.
Foi assim que surgiu o Journalling. Quando há qualquer alteração a um ficheiro, o seu novo estado é inscrito como um só registo no HDD usando para isso o $LogFile.
Nesse registo único fica a indicação de todos os locais possíveis de alteração devido a esse Log, ficando assim garantida a persistência da alteração. Entretanto, depois da confirmação de sucesso da sua inscrição em Log, liberta-se a CPU.
Só depois o sistema se encarrega de executar, usando esse registo em $LogFile, todos os passos no disco.
E assim, se durante o registo efetivo em disco houver um crash, quando o computador retomar, o SO vai verificar se há registos no $LogFile não introduzidos ou parcialmente introduzidos, procedendo em conformidade com cada um para garantir a consistência do sistema de ficheiros.
Só depois de feita a regular inscrição em disco o registo no $LogFile é apagado e o boot do sistema prossegue.
Ficheiro $Bitmap
Este ficheiro constitui a 7ª entrada da MFT, tendo portanto o offset 3000h + 6 x 400h = 4800h.
O ficheiro $Bitmap tem em relação ao HDD a mesma função que o atributo $BITMAP tem em relação aos ficheiros de que é atributo.
Os seus dados, não residentes, são constituídos por um conjunto sequencial de bits (múltiplo de 8 – 1 Byte) de tamanho igual ou superior ao número de clusters do volume. Esses bits representam, cada um, o cluster cujo LCN (Logical Cluster Name) seja igual à ordem do bit na sequência, partindo do bit de menor peso.
Assim, com a simples leitura da sequência de bits, o sistema consegue saber quais são os clusters ocupados e livres.
Ficheiro . (Ponto)
Vamos analisar este ficheiro com o pormenor com que analisámos os primeiros, pois é por aqui que começa o caminho para o nosso objetivo. Este ficheiro representa o Diretório Raiz, onde se encontra o princípio do nosso caminho. Está descrito na figura 35.
Comecemos por analisar o descritor do ficheiro de acordo com a tabela da figura 7, que incluímos atrás como descritor tipo de ficheiro.

- Tem a assinatura FILE.
- O offset para a update sequence é 2Ah.
- O comprimento da update sequence é de 3 palavras.
- O update sequence number é 21 00.
- A update sequence array, isto é, o valor dos bytes substituídos pelo update number no fim de cada setor do ficheiro, é 00 00 e 00 00.
- O use/deletion count tem o valor de 5. Representa o nº de vezes que o ficheiro foi reutilizado. Quando o ficheiro é apagado é levado a 0.
- O hard link count tem o valor de 1. Indica o número de diretórios com referência a este ficheiro.
- O offset para o primeiro atributo é 30h.
- O tamanho real do ficheiro em disco é 280h=640 bytes e o tamanho alocado é de 400h=1.024 Bytes.
- A ID do próximo atributo a entrar é 17h ou 23.
Passemos agora à análise de cada atributo individualmente.
O 1º atributo é $STANDARD INFORMATION, do tipo 10h, tem o comprimento de 48h, tem ID=1 e é residente. O comprimento dos dados do atributo é de 30h e o offset para os mesmos é 18h. Data de criação em 25/04/10 às 22:15:38 e datas de modificação, de modificação da MFT e do último acesso em 11/05/10 às 21:48:08.
O 2º atributo é um $FILE_NAME , tipo 30h, tem 60h de comprimento, ID=2, comprimento de dados de 44h e offset para o seu início 18h. A referência ao ficheiro Pai é entrada 5 da MFT, foi criado em 25/04/10 às 22:15:38 e foi modificado, modificada a MFT e teve o último acesso em 11/05/10 às 21:48:08. O comprimento do nome é 1, o seu namespace é 3 (Win32 e DOS) e o seu nome é . (ponto).
O 3º atributo é um $SECURITY_DESCRIPTOR, tipo 50h, é residente, tem 68h de comprimento, ID=3, tem 50h de comprimento de dados e offset de 18h para o início dos mesmos. Sobre os seus dados não vamos fazer referência.
O 4º atributo é um $INDEX_ROOT, tipo 90h. Este atributo já foi analisado na sua descrição genérica. O essencial que agora interessa é que uma flag indica se o índice é alocado externamente e por isso devemos passar à leitura do atributo seguinte.
O 5º atributo é o $INDEX_ALLOCATION, tipo A0h. Este atributo também já foi analisado na sua descrição genérica. O INDEX_ALLOCATION aponta sempre para o índice externo correspondente à entrada da MFT que o refere. Neste caso estamos dentro do ficheiro . (ponto) e o índice apontado é o Diretório Raiz, que como já foi visto tem 1 cluster de dimensão e está no offset 30000h.
E é para o Diretório Raíz no offset 30000h que vamos, para aí iniciarmos o nosso percurso até ao ficheiro que procuramos.