
Organização Lógica do HDD
O que nós vimos até agora sobre a grande memória persistente do computador, o HDD (Hard Disk Drive ou Disco Rígido), foi a sua forma de funcionamento mecânica, a forma física como guarda a informação que lhe é entregue para preservação e a forma como a referencia.
Relembramos o CHS (Cilinder, Head, Sector), em que o setor é a quantidade mínima que pode ser lida ou escrita num HDD.
Também vimos como a densidade de informação contida no HDD foi aumentando, como o número de setores por pista foi tornado variável conforme as pistas se afastam do centro, como a colocação sequencial dos dados é feita nos HDD de forma intercalada, para que a mudança de setor não o obrigue a esperar uma revolução do prato, etc.
Toda esta evolução permite-nos atualmente dispor de uma enorme quantidade de memória de massa num pequeno prato, mas organizada de tal forma que só mesmo o controlador do HDD sabe lidar com ela. Controladores estes que são o segredo do sucesso de muitos fabricantes, duma complexidade lógica tremenda, consequência da permanente investigação de milhares de Engenheiros.
Com toda esta complexidade põe-se agora a questão:
Então como é que nós lidamos com esses dados quando precisamos de aceder ao HDD? Temos que indicar o CHS de cada dado e a forma como todos eles estão arrumados para os obter? Temos que referir todos os Setores onde um determinado conjunto de dados que precisamos está guardado? E como é que nós sabemos quais os setores em que o controlador do HDD os guardou?
É evidente que a resposta a todas estas questões é que nós não sabemos nem podemos lidar com um HDD a este nível. Não seria imaginável que um programador, quando necessitasse de aceder a um determinado grupo de dados que guardou ou pretende guardar no HDD, tivesse que conhecer todos os pormenores da sua localização.
Foi aqui que os SO (Sistemas Operativos) nos vieram ajudar, criando uma abstração que representa cada tipo de conjunto de dados que nós criamos e manuseamos.
Ficheiro
O Ficheiro (File) é a abstração que existe entre os humanos e o HDD e é composto pelo conjunto de informação (bits) que forma algo que para nós tem um significado, como por exemplo:
Um programa, um filme, uma música, uma fotografia, um texto, uma base de dados, uma palavra, este livro, aquele pequeno programa que fizémos em Assembly quando falámos da CPU, etc.
Tudo o que se regista em HDD é sob a forma de Ficheiro. Portanto, a memória persistente (não volátil) do computador é composta por Ficheiros, que podem conter a essência do funcionamento do nosso computador, ou simples armazenamento de dados. Ficheiros cuja dimensão pode ir de alguns Bytes até centenas de Gigabytes ou mais.
Portanto, para nós tudo o que é a informação com que trabalhamos está contida em ficheiros, que o HDD guarda em Setores por ele espalhados, da forma que o seu controlador lhe indicar. Nós falamos com o HDD em ficheiros, aquilo que entendemos e tem significado lógico para nós, a tal abstração. O HDD transforma-a em posições CHS que só ele conhece e de que nós nos abstraímos.
Mas para que isso aconteça, muita lógica está no meio e a sua análise é o objetivo deste Capítulo.
Cluster
O Cluster é mais uma abstração lógica que nós humanos arranjámos no HDD para conseguirmos lidar com ele. O cluster é um bloco de dados formado por um determinado conjunto de setores, desde 1 até 64.
Mas se já tínhamos os setores, uma unidade física em disco que agrupava muitos bytes, porquê agora mais esta unidade lógica a agrupar setores?
Para isto se poder entender, precisamos de dizer que cada Cluster só pode conter um Ficheiro ou parte do mesmo. Isto é, um Ficheiro pode dividir-se por muitos Clusters mas um Cluster só pode conter um Ficheiro. Um ficheiro, mesmo que tenha um só Byte de dimensão, ocupa um cluster.
Bom, agora já começa a entender-se a história do cluster. Pretende-se associar o ficheiro com uma determinada quantidade fixa de espaço no HDD. Mas então, essa quantidade de espaço que varia de 1 a 64 setores deve ter que ser fixa para um HDD? E como é que se determina?
Como um ficheiro pode ter dimensões muito variadas, a dimensão do cluster deve ser determinada por forma a se conseguir, nas mais diversas situações, a melhor relação de compromisso entre o espaço realmente ocupado pelos ficheiros e o espaço ocupado pelos clusters que os contêm.
A esta diferença chama-se Slack e é por definição o espaço ocupado mas não utilizado em disco, isto é, o somatório do espaço dos clusters não ocupado pelos ficheiros.
Vamos lá com um exemplo prático: se num determinado HDD a predominância for de ficheiros com 1 KB de dimensão e se os clusters forem definidos como contendo 8 setores, portanto com 4 KB de dimensão, teremos um slack médio de 3 KB, isto é, num HDD de 40 GB cheio só existem na realidade 10 GB de dados efetivos. Neste caso o cluster deveria ser dimensionado para 2 setores ou 1 KB, de forma a que o slack fosse mínimo.
Pretende-se portanto que os Clusters tenham a dimensão que provoque menos slack num HDD. Conforme o tipo de ficheiros que formos armazenar nesse HDD, se é que podemos definir um tipo, devemos encontrar para esse HDD a melhor relação para um menor slack.
A dimensão do cluster num HDD é fixa e única, isto é, é a mesma para todo o HDD. Podemos no entanto variar a dimensão do Cluster em diferentes HDD que irão armazenar diferentes tipos de ficheiros.
Para que tal seja possível, não precisamos mesmo de várias unidades físicas de HDD pois, como já veremos adiante, num mesmo HDD podem ser criados vários Volumes, correspondentes a Partições do mesmo HDD.
LBA (Logical Block Adressing)
Já percebemos que o SO arranjou uma abstração que se chama ficheiro, que essa abstração representa para nós as diversas formas de conjuntos de informação com que lidamos e a que precisamos de aceder num HDD. Mas para um HDD essa coisa que dá pelo nome de ficheiros, é uma transparência e simplesmente não existe. Para o controlador do HDD só há Setores, organizados em pistas (que em conjunto e no mesmo alinhamento vertical formam o Cilindro) em faces de pratos (representados pelas Cabeças), onde vai colocar ou procurar os dados a que pretendemos aceder e que constituem os tais ficheiros, que ele arruma à sua maneira, certamente a mais eficiente nos seus termos.
Portanto, nós falamos em ficheiros e o HDD fala em geometria CHS (Cilinder, Head, Sector).
Para complicar mais a questão, os mesmos SO que criaram a abstração lógica com que nós arrumamos os dados na nossa cabeça, os ficheiros, não percebem nada disso de CHS.
Inicialmente, quando o SO queria comunicar com o HDD usava o BIOS, que estabelecia o diálogo com o HDD em CHS. Conforme a capacidade dos HDD foi aumentando o BIOS foi ficando mais desadaptado da sua formatação inicial. De forma a não perder a compatibilidade com computadores mais antigos ainda em funcionamento, foram feitas extensões ao BIOS para continuar no seu papel comunicador com o HDD.
Com o surgimento do Bit Zoning (diferenciação em zonas, da quantidade de setores por pista desde o centro até aos limites do prato), a geometria CHS tornou-se exclusiva de cada fabricante e o endereçamento CHS passou a ser uma prerrogativa do controlador de HDD, impossibilitando o BIOS de fazer o seu endereçamento.
Surge então o LBA (Logical Block Adressing), uma abstração lógica introduzida pelos fabricantes de HDD para comunicarem os seus locais de endereçamento sem referenciarem a sua geometria CHS e fugir às limitações que o BIOS impunha ao seu crescimento.
O BIOS continuou a ser por algum tempo o interlocutor perante o SO, arranjando extensões nos bits que tem para representar a geometria CHS, o extended BIOS e apreendendo a traduzir de LBA para CHS e vice-versa, continuando a ser a geometria CHS a que é apresentada ao SO.
Mas afinal o que é o LBA?
O LBA consiste na tradução da geometria CHS para uma numeração sequencial dos setores (Blocos).
Por exemplo o LBA 0 corresponde ao CHS 0,0,1, o LBA 1 ao CHS 0,0,2 e o LBA 1.953.520.065 será o CHS 121601,255,63 como acontece para um HDD com 1 TB.
O endereçamento por LBA é agora feito diretamente pelo SO por referência ao número respetivo do Bloco, tendo como limitação a sua capacidade de endereçamento em bits. Um SO de 32 bits pode endereçar 4.294.967.296 Blocos o que dá para discos com 2.199.023.255.552 bytes, ou seja 2 TB de capacidade.
Não fizémos esta referência por acaso.
Este é o limite de endereçamento para um SO de 32 bits. Mas podem ser construídos HDD com capacidade superior. Os sucessivos aumentos de densidade de bits por polegada quadrada e a variação do número de pratos permitem já muito mais.
A extensão do valor do setor para o valor mais corrente do cluster (4KB) é uma das soluções possíveis para o crescimento da capacidade de endereçamento em LBA para os SO de 32 bits.
Sistemas de Ficheiros
Portanto, estávamos nos ficheiros, a tal abstração que o SO nos arranjou para juntarmos informação.
Mas nós não nos vamos dirigir aos ficheiros chamando por eles à entrada do HDD nem vamos certamente endereçá-los por LBA. A única coisa que nós sabemos é que precisamos de um tal ficheiro para trabalhar ou que temos dados que queremos guardar como ficheiros. E a partir daqui mais nada. Quando tal acontece pedimos ao SO que trate disso. E é o que ele faz.
Os Sistemas de Ficheiros são a forma que cada SO arranjou para organizar os ficheiros representam no HDD. E não só! Hoje em dia um sistema de ficheiros deve não só organizar os ficheiros, mas também garantir a segurança e restrições de acesso que tenham que ser impostas aos ficheiros bem como a consistência do próprio sistema. Poucas palavras para uma enormidade de trabalho. É o que vamos tentar mostrar como é feito, dentro dos limites do razoável e inseridos num objetivo que vamos definir.
Há muitos tipos de Sistemas de Ficheiros, mas de todos queremos salientar três:
O FAT (File Allocation Table), que começou pela versão FAT 8, depois FAT 12, passou ao FAT 16, depois ao FAT 32 e finalmente ao extFAT (extended FAT). O número à frente de FAT simboliza a quantidade de bits disponível para cada elemento da tabela de alocação. Este foi o sistema de ficheiros adotado pela Microsoft para o seu MS-DOS, o primeiro SO vendido separado de uma máquina. Talvez por isso seja o sistema de ficheiros mais conhecido entre os muitos leigos curiosos que a partir daí puderam explorar as suas potencialidades criativas em informática, tornando-se muitos em verdadeiros profissionais e mesmo investigadores.
Com o crescimento da capacidade dos HDD, o sistema de ficheiros FAT tornou-se extremamente pesado, porque:
- ou tinha enormes tabelas de alocação que reduziam a sua eficiência, como veremos adiante;
- ou criavam clusters de enorme dimensão, com a consequente perda de espaço em disco por slack.
Nesta perspetiva, este sistema de ficheiros começou a tornar-se proporcionalmente ineficiente, devido à sua forma de organização e funcionamento, dando lugar a um novo sistema de ficheiros que a Microsoft implementou para o seu primeiro SO vocacionado para servidores, o Windows NT.
O NTFS (New Technology File System), foi criado pela Microsoft quando quis atingir também o mercado dos computadores de pequenas redes e passou a ser o sistema de ficheiros adotado pelos SO Windows NT para PC (a partir do XP). O NTFS foi elaborado a pensar no funcionamento dos PC em rede, com a necessidade de criar diferentes tipos de restrições de acesso a diferentes tipos de ficheiros. Dispõe por isso de definições de segurança que permitem condicionar o acesso e as formas de acesso ficheiro a ficheiro, o que era da máxima importância para a exploração de redes em que múltiplos utilizadores podiam ter acesso a todos os ficheiros armazenados. Tem a capacidade de guardar muito mais informação por cada ficheiro, dispondo de um sistema de journaling que lhe permite recuperar de crashs do sistema, mantendo na totalidade a consistência do sistema de ficheiros. Tem uma estrutura de organização e funcionamento que lhe permite ser insensível ao aumento de capacidade dos discos.
Foi quando o FAT começou a sua decadência por ineficiência que a Microsoft estendeu o NTFS a toda a família NT, inclusive aos SO de vocação para PC, começando no Windows XP e estando na sua máxima performance com os atuais Windows, inclusive no novo Windows 10. O seu sucessor, o ReFS (Resilient File System), não está ainda preparado para grandes aventuras no mundo dos SO para PC.
O EXT (Extended File System), é o sistema de ficheiros desenvolvido especialmente para o Linux. A versão ext foi substituída pela versão ext2 e tem vindo a sofrer atualizações até à corrente versão ext4. O ext foi inicialmente inspirado e partiu de bases do UFS, o sistema de ficheiros do Unix. Dispõe de fortes parâmetros de segurança na limitação de acesso aos ficheiros e desde o ext3 dispõe de journaling.
A importância do NTFS é proporcional ao peso que a Microsoft detém no segmento dos Personal Computers (PC), sendo por essa razão o sistema de ficheiros sobre que iremos fazer incidir mais a nossa abordagem ao tema.
Faremos uma abordagem ao FAT, até porque ainda é de uso corrente em pequenos suportes digitais, como Pendrives, disquetes e outros. Pode ainda ser considerada a sua utilização em pequenas partições, ou partes lógicas de um HDD criadas para suportarem por exemplo o Sistema e o software, pois há opiniões experientes de que o FAT, para pequenas dimensões de discos é mais rápido do que o NTFS. Tal não será de admirar, devido ao facto de ser muito menos pesado em termos de informação disponibilizada. O NTFS, por cada alteração ou criação de ficheiros tem que escrever numa enormidade de pontos, como iremos ver.
Vamos então avançar, começando por analisar elementos lógicos fundamentais no HDD. Ma antes vamos entender o editor hexadecimal com que vamos analisar o conteúdo do HDD.
O Editor Hexadecimal
Porquê nova referência ao sistema numérico hexadecimal aqui e agora?
Cada dígito hexadecimal representa quatro dígitos binários, portanto dois dígitos hexadecimais representam um Byte ou oito dígitos binários (bits). Foi porque sabíamos que íamos chegar a este ponto, que introduzimos logo no início, noções sobre sistemas numéricos posicionais em que incluímos o hexadecimal. Quando se começa a evoluir na informática e a chegar a endereços, posições em discos ou à leitura dos bytes de um setor, tudo passa a ser feito em hexadecimal.
E porquê?
Porque tudo fica muito mais claro:
- Os bytes são sempre representados por dois dígitos.
- Os 512 Bytes de cada setor são representados numa forma de tabela regular de 32×16 Bytes, aproveitando as 16 colunas para todos os dígitos hexadecimais (0 a F), sendo assim fácil de identificar a posição de cada Byte. Veja-se este tipo de organização na representação de um setor do HDD na figura1.
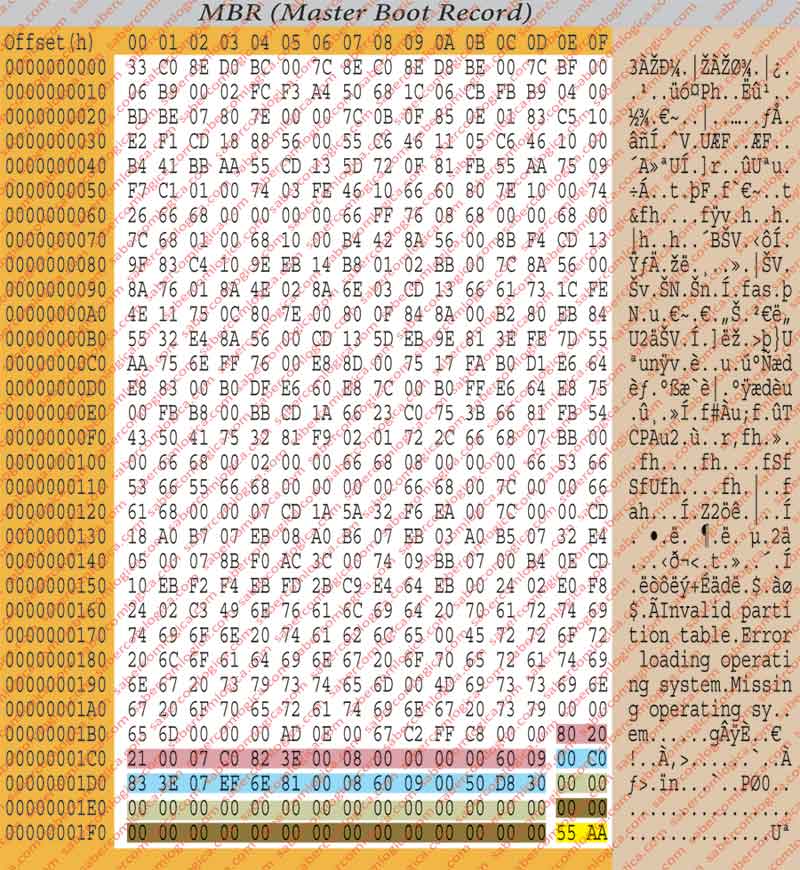
Cada uma dessas colunas representa o offset relativamente à posição que se encontra do lado esquerdo. Assim, se no início da linha está por exemplo o valor 0010h e o byte que nos interessa está na coluna C, portanto com o offset Ch, a sua posição será 0010h+Ch=001Ch.
Agora vamos verificar como é fácil a conversão de hexadecimal em binário. Por exemplo os dois dígitos 72h são convertidos um a um. Assim: 7h = 0111 e 2h = 0010 resultando então que 72h = 01110010 = 114 (decimal) ou 72h = 7 x 16 + 2 = 112 + 2 = 114 (decimal)
Observação: Quando se usa a letra h à frente de qualquer conjunto de dígitos de 0 a F, significa que esse número (se como número puder ser interpretado por outro sistema de numeração, como é o caso no exemplo anterior) está em hexadecimal.
Falámos há pouco em Offset, referindo-nos ao deslocamento, em termos de 16 colunas (0 a F), numa tabela de 32 linhas.
Mas Offset pode ter outro significado quando aplicado globalmente, referindo nesse caso a deslocação do byte em relação ao início do disco (volume), se for absoluto, ou em relação a uma qualquer posição de referência, se for relativo.
A tabela da figura 2 pretende ilustrar estas questões sobre offset e é retirada da figura 1.
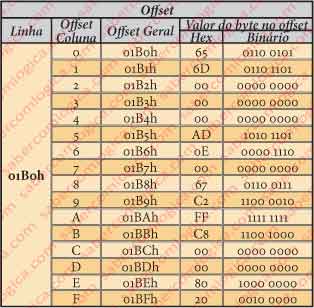
É bom que esta questão fique clara, porque o termo offset vai ser nossa companhia permanente neste Capítulo.
Nada melhor do que olharmos para a figura 1 para entendermos como funciona um leitor hexadecimal de um disco. O disco é apresentado no formato de linhas com 16 colunas, havendo na intersecção de cada uma um conjunto de dois dígitos. Esses 2 dígitos são a representação hexadecimal de 1 Byte.
Na coluna da esquerda é apresentado o offset (h) da linha em relação ao início do disco. Na linha superior é apresentado o offset em relação ao início da linha, de cada Byte representado. Na figura 2 representa-se o conjunto dos bytes de uma dada linha (01B0h) relacionados ao seu offset, posição global e valor.
Na leitura do editor aparece uma coluna à direita que faz a interpretação em código ASCII estendido (8 bits) de cada um dos Bytes da linha. Nalguns casos faz sentido, quando o valor dos Bytes representa texto. Nos restantes casos não faz qualquer sentido. Mas dá para entender, quando se procura uma mensagem algures num ficheiro.
Falámos há pouco em partições mas ainda não definimos o seu significado. Quando se formata um disco… Formata? Também não definimos tal. Vamos lá devagar e comecemos pela formatação.
Formatação
Formatar um HDD é, tal como o nome indica, dar-lhe forma interior, ou antes, estruturá-lo internamente para que os dados possam ser lidos e escritos nos locais permitidos.
Há dois níveis essenciais de formatação:
- A formatação de baixo nível, que consiste em:
- Ensinar ao controlador do disco a geometria do HDD, isto é, o bit zoning, o número de setores por pista em cada zona, o número de pistas por cada zona, o número total de pistas e consequentemente de cilindros, o número total de setores e o número de cabeças.
- Colocar em disco a informação necessária para que a cada momento as cabeças possam saber onde estão, isto é, sinalizar o início de cada setor e a sua identificação,
- Colocar elementos de orientação para as cabeças, no seu movimento de procura pela pista solicitada. Como o movimento do atuador é linear, são colocados bits de identificação espalhados pelas pistas com a sua identificação, como forma de ajudar o atuador a mais facilmente se posicionar corretamente. Se nos lembrarmos que as diferenças de temperaturas suportadas por um HDD provocam dilatações e consequentes alterações de posição física das pistas, entendemos quão necessária é esta informação.
A formatação de baixo nível, devido à sua enorme complexidade, nos atuais HDD já vem feita de fábrica.
- A formatação de alto nível consiste em colocar em disco a informação de como ele se encontra organizado. O número de partições que tem, onde começam e onde acabam, os elementos de código necessários para o arranque do computador, a identificação do sistema de ficheiros escolhido, com a localização dos elementos de que cada um dispõe para identificar os dados a guardar em disco.
Partições
A partição de um HDD é uma das primeiras tarefas que se executa quando se faz a formatação de alto nível.
Consiste na divisão do HDD em diversas peças separadas, ou partições. Cada partição passa a constituir um Volume, o que em termos lógicos representa um disco independente. É isso que o utilizador vê. Se criarmos duas partições, passamos a ter dois discos com letras diferentes, por exemplo o disco C: e o disco D:.
Mesmo que não se pretendam criar partições no HDD, durante a formatação é sempre criada uma partição única, ou um Volume, que aparece ao utilizador como um só disco, por exemplo o disco C:, mas que na realidade é um Volume dentro do HDD.
Embora isto venha a ser referido em pormenor adiante, podemos já adiantar que, enquanto o HDD tem um setor de arranque, o primeiro, que é independente de qualquer Sistema Operativo (SO), a partição tem outro setor de arranque, também o primeiro, que já é criado pelo SO que a vai utilizar.
Quando estamos a trabalhar com um só volume, não estamos a utilizar o HDD como tal mas sim um Volume dentro do HDD. Cada disco físico ou HDD, aceita um máximo de 4 partições, por questões que têm a ver com a limitação da tabela de partições que está no setor de arranque do HDD. Chamam-se partições primárias.
Caso se pretendam criar mais partições, então uma destas quatro tem que ser convertida numa partição estendida, dentro da qual poderão então ser criadas partições lógicas em muito maior número. A partição estendida tem por fim precisamente aquilo que o nome indica, isto é, estender a tabela de partições para fora do espaço que lhe é reservado, guardando dentro de si o ponteiro para a localização dessa tabela estendida.
A diferença fundamental entre partições primárias e partições lógicas é que só nas primeiras é possível criar um bootable Volume, ou seja, um volume a partir do qual possa ser feito o arranque do sistema.
À partição de arranque do sistema damos o nome de partição ativa e é importante não esquecermos de a criar pois, caso contrário o sistema não arranca.
Vamos então passar à análise dos elementos de um HDD que permitem o arranque do sistema e a localização posterior dos ficheiros. Para melhor entendimento vamos acompanhar a análise com imagens de setores do HDD obtidas através de um editor hexadecimal. Agora já será mais fácil entender essas imagens pois já referimos como um editor hexadecimal apresenta o conteúdo do disco.
Vamos usar para a representação um HDD de 500 GB com duas partições primárias, sendo a primeira Bootable.
Mas ainda antes, vamos fazer uma pequena abordagem à forma como os conjuntgos de Bytes devem ser interpretados após a sua leitura feita na forma como reralmente se encontram no Volume
Endianness
Endianness, na ciência da computação, refere-se à ordenação das partes individualmente endereçáveis enquanto partes integrantes de uma unidade maior.
As partes individualmente endereçáveis são os bytes e os conjuntos maiores são grupos de bytes que só têm significado interpretados em conjunto. Endianness tem a ver com a ordem dos bytes nesses grupos. A diferença vai estar no byte que aparece em primeiro.
- Se o byte de menor ordem no conjunto for o primeiro evoluindo sequencialmente até ao último, o byte de maior ordem, então estamos perante uma UCP little endian.
- Se o byte de maior ordem no conjunto for o primeiro evoluindo sequencialmente até ao último, o byte de menor ordem, então estamos perante uma UCP big endian.
Vamos ver um caso prático para melhor podermos entender esta coisa do nome pomposo “Endianness”. Para isso vamos utilizar o conjunto de bytes significativos que vão do offset 01DAh até ao offset 01DDh da Figura 1, que representam o número de setores da 2ª partição, ou seja 819.482.624 setores, o que em binário e representado em hexadecimal se faz com o conjunto de 4 bytes 30 D8 50 00.
As UCP da Intel são little endian, isto é, escrevem os conjuntos significativos de bytes no HDD partindo do de menor ordem no conjunto para o de maior ordem no conjunto. Assim, olhando para a Figura 2a conseguimos ver a ordem em que ficam registados no HDD após a passagem pela cabeça de escrita e que é 00 50 D8 30.
O editor hexadecimal apresenta os bytes pela ordem que são lidos individualmente do HDD, pois desconhece qualquer significado de qualquer conjunto e mesmo qualquer conjunto – para ele são bytes. Então agora sigam lá o percurso da cabeça de leitura sobre o prato do HDD, vejam qual o primeiro byte a ser lido, a sequência e o último byte a ser lido e digam lá se o que foi lido não é o conjunto 00 50 D8 30 que se encontra do offset 01DAh até ao offset 01DDh da Figura 1?
Pois é, e estão ao contrário, porque:
- o primeiro a ser lido, o 1º a ser escrito e de ordem mais baixa(00), vai ficar na ordem mais alta (00),
- o segundo a ser lido, o 2º a ser escrito e de 2ª ordem (50) fica na 3ª ordem (50)
- o terceiro a ser lido, 3º a ser escrito o de 3ª ordem (D8) fica na 2ª ordem (D8)e
- o último a ser lido o último a ser escrito e de ordem mais alta (30) fica na ordem mais baixa (30).
Portanto quando os conjuntos de bytes significativos são escritos por uma UCP little endian, ao serem lidos têm que ser interpretados na ordem inversa da leitura dos bytes individuais, isto é, quando se lê 00 50 D8 30 deve-se interpretar como 30 D8 50 00. E cá temos nós o valor pretendido de 819.482.624 setores.
MBR (Master Boot Record)
MBR (Master Boot Record) é o primeiro setor de qualquer disco rígido. Nele estão contidas todas as informações necessárias ao arranque do sistema.
O MBR é criado no HDD propriamente dito, fora de qualquer partição e, portanto, independente do sistema de ficheiros que venha a ser escolhido. É nele que se encontra a tabela de partições.
Vamos começar por interpretar o conteúdo do MBR, conforme se pode acompanhar na figura 1. Desde o offset 0000h até ao offset 01BDh está o código de boot do MBR. Do offset 01BEh até ao offset 01FDh está a tabela de partições, um espaço de 64 Bytes onde podemos verificar a existência de definição para 4 partições, compostas por 16 Bytes cada e realçadas a cores a primeira, a segunda, a terceira e a quarta partições primárias. Nos dois bytes finais, sublinhados a amarelo, está a boot signature do setor do MBR.
Vamos agora entender como funciona o processo de boot do computador a partir do MBR.
O Boot do computador
Quando se liga o computador, a sua CPU vai iniciar o seu ciclo de busca, descodificação e execução. Mas, como no ponteiro de instruções, ou PC (Program Counter), ainda não está nada, ele vai ficar num ciclo infinito a apontar para ele próprio.
O computador é assim. Enquanto não lhe ensinarem o que fazer, ele simplesmente não faz nada.
Lembram-se certamente de já termos falado do BIOS. Pois é precisamente o BIOS que é responsável pelo BOOT do computador, contendo os programas necessários para o efeito.
Mas se a UCP não faz nada, como é que encontra o BIOS?
Vamos lá então ver como funciona o processo de arranque ou Boot de um computador.
Quando se liga o interruptor do computador, a CPU coloca no PC (Program Counter) da CPU o endereço de base da ROM do BIOS, estabelecido por acordo entre os fabricantes do BIOS e da CPU, arrancando assim com os programas contidos no BIOS. Então o BIOS executa o POST verificando a conformidade dos principais periféricos e o SETUP e carrega em memória o código presente no MBR, iniciando a sua execução.
O código em execução do MBR, procura na Tabela de Partições a identificação das partições existentes, verifica a existência de uma partição ativa e se a mesma é bootable. Verifica finalmente a assinatura de boot correspondente aos dois últimos Bytes do MBR e que devem corresponder a 55 AA, senão o processo de boot é suspenso.
Se tudo estiver bem com a assinatura, transfere para o boot sector dessa partição ativa bootable a continuação do processo de boot. Após a leitura da tabela de partições, o código de boot do MBR carrega em memória o código do setor de boot da 1ª partição, o qual por sua vez irá procurar o executável que dará início ao Sistema Operativo instalado nessa partição, que a partir desse momento toma conta do computador.
E se este processo estivesse a decorrer no seu computador, neste momento ele estaria pronto para operar debaixo do SO que tem instalado.
Tabela de partições
Por uma primeira análise da tabela de partições verificamos só existirem duas partições primárias, pois os bytes de definições das duas últimas estão todos a zero.
Vamos agora analisar o que o código de boot lê nos Bytes de cada partição, descritos na figura 4 que é a apresentação isolada do que se encontra no MBR. Vamos analisar a 1ª partição, a bootable, do offset 01BEh ao offset 01CDh.

O byte em 01BEh é o Indicador de Boot (80 se for bootable). Assim verificamos que a 1ª partição é bootable e a 2ª partição não.
Os Bytes de 01BFh a 01C1h referem-se ao CHS [Cylinder (10 bits), Head (8 bits), Sector (6 bits)] de início da partição. São ignoradas devido à dimensão do disco.
O byte 01C2h é o identificador de sistema de ficheiros. O seu valor é 07 para partições NTFS primárias ou lógicas e 06 para partições estendidas.
Os Bytes de 01C3h a 01C5h referem-se ao CHS de fim de partição. São ignoradas devido à dimensão do disco.
Os bytes de 01C6h a 01C9h representam o valor do Setor Relativo, descrito em LBA (Logical Bloc Address). Corresponde ao offset em setores desde o início do HDD até ao 1º setor de cada partição. O seu valor no caso em análise – Offset em setores – 00 00 08 00 = 2.048 / Offset de início – 2.048 x 512 = 1.048.576 = 100000h
Os bytes de 01CAh a 01CDh representam o número total de setores da partição. Relembramos que a nossa CPU funciona em little endian. Então, para sabermos o seu valor em decimal vamos ter que inverter a ordem dos bytes em hexadecimal, o que significa: Total de setores – 09 60 00 00 = 157.286.400
Resumindo: A 1ª partição tem 2.048 setores antes do seu início, tem o tamanho de 157.286.400 setores e começa no offset 100000h. E é neste offset que o Boot do sistema vai prosseguir, agora já entregue ao Sistema Operativo.
Usando o mesmo método que para a anterior podemos concluir que para a 2ª partição teremos em resumo: Offset em setores – 09 60 08 00 – 157.288.448 – Offset de início – 157.288.448 x 512 = 80.531.685.376 ou 12C0100000h – Total de setores – 30 D8 50 00 – 819.482.624.Portanto, a 2ª partição tem 157.288.448 setores antes do seu início, tem o tamanho de 819.482.624 setores e inicia-se no offset 12C0100000h.
A partir daqui o computador está entregue ao Sistema Operativo presente na Partição Bootable, o Windows. Vai assim agora a gestão dos ficheiros ser entregue ao seu sistema de ficheiros, o NTFS. Por isso vamos navegar para o offset 12C0100000h onde se inicia a 2ª partição para cumprirmos o objetivo que lá vamos definir e que nos vai levar a entender um sistema de ficheiros, concretamente o NTFS.