
A Cache no Intel Nehalem (i7)
Vamos agora analisar, na base do que temos vindo a descrever, a organização de memória do processador i7 da Intel, no qual foi implementada a nova arquitetura Nehalem. É um processador de última geração, no momento em que este trabalho é e executado, em que os mais pequenos detalhes são explorados, na base do atual desenvolvimento desta ciência, com o fim de obter a máxima performance e aproveitamento do processador.
O Intel i7 é um processador multinuclear, com 4 ou 6 núcleos incluídos no mesmo Chip, cada um com autonomia equivalente a um processador isolado, partilhando no entanto com os outros os recursos incluídos numa zona a que chamamos “não núcleo”, mas que faz parte integrante do Chip. No nosso caso de análise vamos considerar um Chip com 4 núcleos.
Neste local vamos abordar exclusivamente a organização de memória deste processador, evitando o uso de termos por ora confusos e a abordagem de questões que só serão entendidas após a análise dos Sistemas Operativos, ocasião em que voltaremos ao tema.
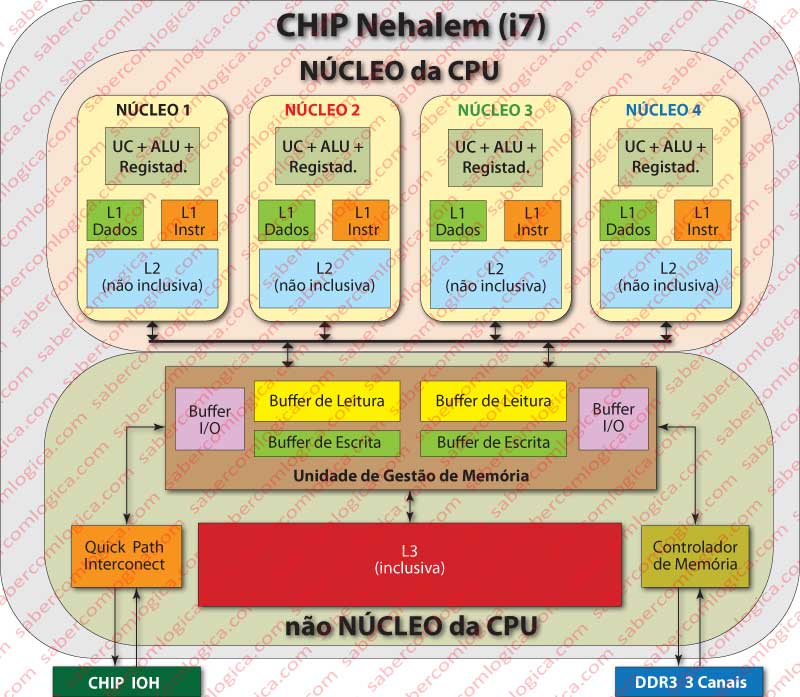
Este processador dispõe de 3 níveis de cache, designados por L1 (Level 1 ou nível 1), L2 e L3. As L1 e L2 existem individualmente associadas a cada núcleo do processador. A L3 é partilhada por todos os núcleos, tal como podemos ver na Figura 1.
A cache L1 está dividida em duas:
- A L1 de instruções, uma cache associativa de 4 vias, com 128 blocos por via. Os blocos são de 64 Bytes e a capacidade desta cache é de 128*4*64=32.768 Bytes ou 32 KB. Esta cache tem uma Latência de 3 ciclos de clock.
- A L1 de dados, associativa de 8 vias, com 64 blocos por via. Os blocos são de 64 Bytes e a capacidade da cache é de 64*8*64 = 32.768 Bytes ou 32 KB. A latência desta cache é de 4 ciclos de clock.
A cache L2 é integrada de dados e instruções, com 8 vias, 512 blocos por via, blocos de 64 Bytes e consequentemente uma capacidade de 512*8*64 = 262.144 Bytes ou 256 KB. Esta cache é não inclusiva e a sua latência é de 10 ciclos de clock. .
A cache L3 é integrada e partilhada, tem 16 vias, 8.192 blocos por via, os blocos têm 64 Bytes e a sua dimensão é consequentemente de 8.192*16*64 = 8.388.608 Bytes ou 8 MB. Esta cache é inclusiva e a sua latência é de aproximadamente 40 ciclos de clock. Porque se encontra na zona não núcleo do Chip e por esta zona ter uma frequência de clock própria e diferente da do núcleo, indicamos o valor da latência em ciclos de clock do núcleo e por um valor aproximado.
A descrição que vem sendo feita poderá ser melhor acompanhada na Figura 2 onde já se detalham com algum pormenor as características dos vários elementos intervenientes e suas ligações.
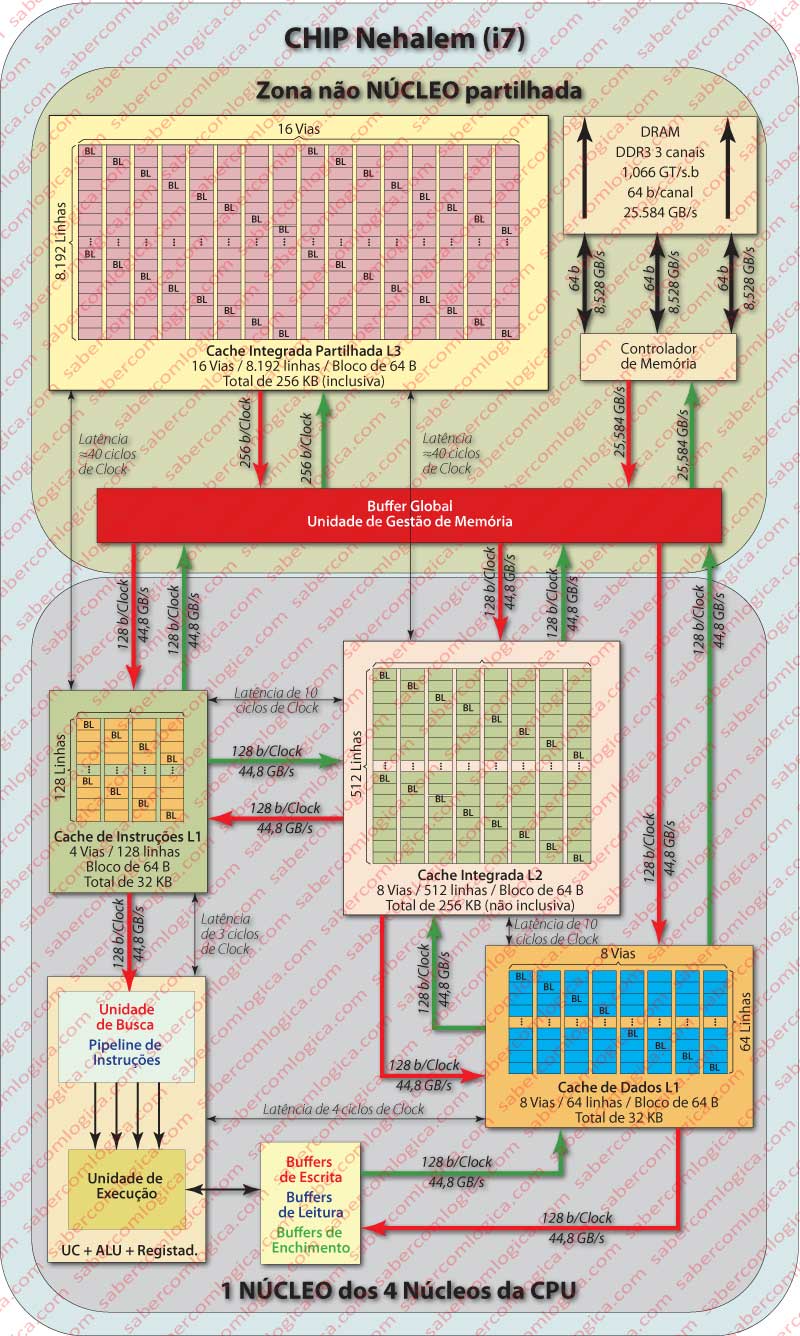
O facto de a cache L3 ser inclusiva permite-lhe responder a pedidos de blocos de algum núcleo sem ter necessidade de intervir junto das caches L1 ou L2 de outro núcleo que detenham o mesmo bloco. Este é um aspeto fundamental no processador multinuclear, que como é evidente não se resolve só assim, mas que por envolver concorrência fica para tratar após os Sistemas Operativos.
Mas o que é isso de cache inclusiva?
Diz-se que uma cache é inclusiva quando todos os registos de uma cache de nível inferior estão nela incluídos incluídos, isto é, todos os registos em L2 e L1 têm cópias guardadas também em L3.
Diz-se que uma cache é não inclusiva quando os registos presentes numa cache de nível inferior não estão na de nível superior, isto é, os registos de L1 não têm que estar em L2.
A política de escrita em qualquer dos níveis de cache é Write back.
Os Buffers existentes entre a Unidade de Controlo da CPU e a cache L1 têm por fim tornar mais eficiente o uso do sistema de memória por parte da CPU. Com o auxílio desses buffers o i7 consegue:
- Continuar a executar instruções (não conflituosas) sem ter que esperar que um dado seja escrito ou obtido da memória ou cache.
- Execução de operações de memória fora de ordem.
- A busca previsível de instruções na L1, baseada em lógica de hardware.
- Determinar a lógica do mesmo tipo de buscas na L2, o que é feito carregando em L2 dados com base nas últimas requisições feitas por L1 a L2.
- Determinar por previsão (na execução de operações fora de ordem) se uma determinada leitura pode ser feita antecipadamente por não ser afetada por nenhuma escrita anterior.
- E muitas outras.
Entre esta UCP e a Memória Principal (MP), a arquitetura Nehalem introduziu várias inovações:
- O Controlador de Memória (CM) é residente no interior do Chip da UCP, permitindo portanto que a comunicação entre a UCP e a MP se faça diretamente e não utilizando mais o FSB.
- Três canais de comunicação foram estabelecidos entre o CM e a MP.
- Cada canal da memória RAM é gerido independentemente pela Unidade de Gestão de Memória Nehalem. Isto significa que, enquanto num pode enviar dados, noutro pode receber e noutro refrescar, assim como pode receber ou enviar nos 3 canais em simultâneo.
Coerência de Cache
Vamos agora falar de um aspeto muito importante das caches, que ressalta da atual arquitetura multinuclear das UCP, que permite um ambiente multitarefa distribuído em diferentes núcleos. Multitarefa é um ambiente de execução programável, em que um programa ao executar se divide em várias linhas de execução não conflituosas mas concorrentes. A multitarefa será analisada e mais bem definida quando falarmos de Sistemas Operativos. Para já o que interessa reter é que:
- Nesse ambiente, as várias tarefas que executam em paralelo fazem-no em núcleos diferentes da UCP.
- Nesse ambiente podem coexistir várias tarefas que partilham os mesmos recursos, isto é, que podem aceder à mesma informação em cache, em núcleos diferentes.
Como sabemos, a UCP pede à memória os valores que pretende. Ora, esses pedidos são feitos à cache L1, que para a UCP e de uma forma transparente, representa a tal memória com quem fala. Nos processadores multinucleares, como aquele que acabámos de analisar, podem existir tantas caches L1 quantos os núcleos desse chip UCP. Assim sendo, pode acontecer que uma tarefa altere um valor na cache L1 do núcleo A, onde está a executar e outra tarefa faça de seguida uma leitura do mesmo valor na cache do núcleo B, onde essa tarefa está a executar. E o bloco de cache que contém esse valor já estava carregado em ambas as caches antes do início destas operações.
Se isto fosse possível, a segunda tarefa ia ler da memória um valor com o qual ia realizar operações, que seria diferente daquele que na realidade devia utilizar para esse trabalho. Pior ainda, como estamos perante uma política de write back, quando esse bloco fosse escrito em memória a partir de cada um dos núcleos, uma versão iria sobrepor a outra, tornando a memória inconsistente, isto é, deixávamos de poder garantir que os dados em memória correspondiam sempre à versão mais atual dos mesmos. O que descrevemos seria incoerência de cache. Resulta desde já a necessidade de garantir a coerência da cache.
Por razões práticas, que resultam da forma como os valores são colocados e retirados da cache, por blocos (linhas), a coerência de cache é garantida ao nível do bloco de dados da cache. Nunca é demais relembrar que a unidade de leitura em Memória Principal é o bloco.
Este conflito de acessos sobre os mesmos dados e a redução das latências provocadas pelo seu tratamento, vem de há muito sendo tratado, com mais intensidade com a evolução da presença de processadores multinucleares, gerando protocolos diversos de entre os quais vamos distinguir um para esta nossa abordagem.
Protocolo MESI
Vamos analisar a forma como esta questão é tratada pelo protocolo MESI (Modified, Exclusif, Shared, Invalid). Para além de ser um dos protocolos mais conhecidos é aquele que é usado pela arquitetura Nehalem, no âmbito da qual vimos agora desenvolvendo este trabalho de uma forma mais objetiva.
Para que este protocolo possa ser implementado existem mais bits em cada bloco de cache que permitem definir o Estado do Bloco.
Os diferentes estados possíveis para o bloco, têm como iniciais para os seus nomes as letras do nome do protocolo, sendo assim:
- Modified (Modificado) – É o estado do bloco que está em cache e foi alterado.
- Exclusiv (Exclusivo) – É o estado do bloco que só está numa das caches dos núcleos da UCP.
- Shared (Partilhado) – É o estado do bloco que se encontra em várias caches, podendo ser lido por qualquer uma.
- Invalid (Inválido) – É o estado do bloco cujo conteúdo não corresponde à última versão em memória.
Como se pode ver na Figura 3, os blocos de cache têm um conjunto de bits iniciais, sobre alguns dos quais já tínhamos falado. Mas vamos repetir, descrevendo cada um e indicando como contribuem para a determinação do estado do bloco ( foi considerado que estamos perante uma política de escrita de write back, a usada nos processadores Nehalem, em cujo contexto este tema está a ser abordado):
- Valid bit ou bit de validação, que assume o valor 1 quando o bloco é válido, isto é pode ser acedido porque os valores que dele constam correspondem aos atuais na memória principal.
- Dirty bit ou bit de modificação, que assume o valor 1 quando o bloco foi escrito e portanto alterado em qualquer dos seus Bytes.
- Shared bit ou bit de partilha, que assume o valor de 1 quando o bloco está em mais do que uma cache de núcleo, podendo ser acedido porque os valores que dele constam correspondem aos mais atuais em memória.
- LRU bits ou bits MUR, utilizados pelo protocolo de substituição de blocos LRU (Least Recently Used) ou MUR (Menos Utilizado Recentemente). São 3 nas caches L1 e L2 (8 vias) e 4 na cache L3 (16 vias).
- Bit de inclusão -Na cache L3 aparecem ainda mais 4 bits em cada bloco que têm por fim identificar em que caches de que núcleo esse bloco se encontra incluído, se estiver. Cada um assume o valor 1 se no núcleo por ele representado, esse bloco estiver replicado. Isto é possível porque a cache L3 é inclusiva, isto é, todos os blocos que se encontrem nas caches L1 e L2 também se encontram na cache L3.
Os bits LRU estão colocados no gráfico de apresentação geral da Figura 3, mas não vão ser preenchidos nos casos de análise de coerência. porque não têm relação com a coerência de cache e porque, para se entender o seu significado, teriam que ser apresentadas as várias vias de cada cache, o que não podemos fazer por manifesta falta de espaço.
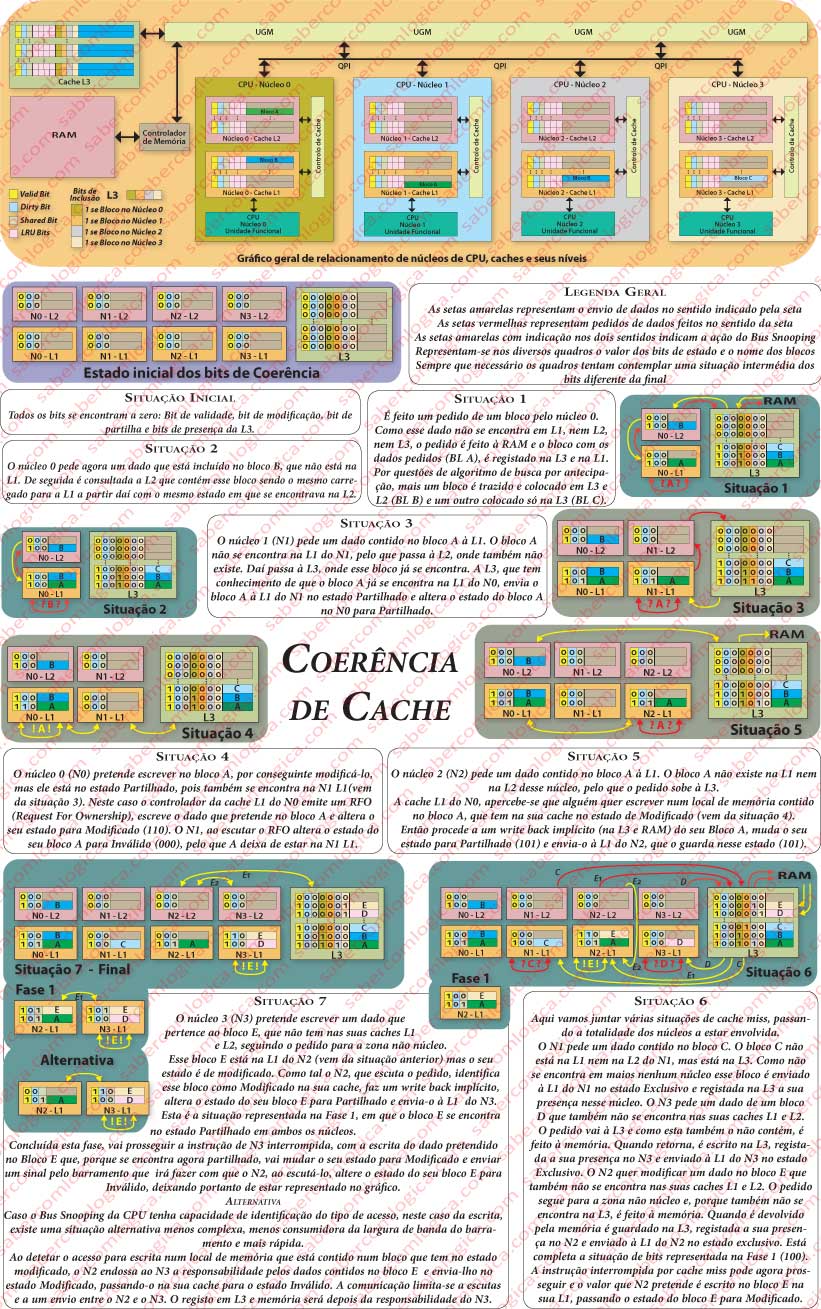
Os restantes bits dos blocos das caches L1 e L2 vão representar os vários estados da seguinte forma:
- O bit de validade a 0 invalida o bloco e o significado de qualquer dos outros bits bits. O estado do bloco será Inválido.
- O bit de validade a 1 e os restantes bits a 0 representam um bloco no estado de Exclusivo.
- O bit de validade a 1 e o bit de partilha a 1, representam o estado de um bloco Partilhado.
- O bit de validade a 1 e o bit de modificado a 1, representam um bloco no estado de Modificado.
Vamos agora perceber como é que os blocos mudam de estado e entre que estados se pode produzir a mudança.
Bus Snooping
Antes de avançarmos mais convém introduzir aqui um conceito importante para o entendimento do que se vai dizer de seguida. Primeiro é importante sabermos que os núcleos da CPU estão interligados através de um barramento QPI (Quick Pass Interconect).
Para as situações de memória distribuída e partilhada, já existente em grandes sistemas com vários processadores e caches individuais, foi implementada uma técnica a que se deu o nome de Bus Snooping ou Bus Sniffing (Roubar o Barramento ou Cheirar o Barramento), agora estendida às CPU multinucleares.
Bus Snooping, consiste numa tecnologia em que todos os controladores de cache estão permanentemente a monitorar o barramento (o termo mais correspondente é sniffing, também utilizado em redes para o monitoramento do tráfego nas mesmas).
A utilização de snooping deriva do facto de que nestes casos, o controlador de cache, além de monitorar também pode roubar, ou chamar a si, a operação no barramento. Por esta razão, os controladores de cache de cada núcleo tanto podem estar à escuta do que se passa no barramento como, em função do que escutam, adquirir o barramento e enviar notificações ou dados pelo mesmo.
A arquitetura Nehalem provém os seus processadores com capacidades de Bus Snooping.
Vamos prosseguir, porque com esta pequena definição, adiante se entenderá melhor como funciona esta tecnologia.
No arranque do computador todos os bits de validade dos blocos são colocados no estado de Inválido, o que significa que o bloco não contém os valores mais atuais da memória.
Leitura de um bloco
Aquando de uma leitura a um bloco inválido na cache L1, dá-se uma cache miss na L1, sendo feita uma leitura da L2. Se o bloco se encontrar na cache L2, é transferido para a L1 com os indicadores de estado que detiver na ocasião. Se também a L2 der cache miss, então é feita uma procura na L3 e na memória.
O bloco já se encontra na L3.
Neste caso a L3 sabe se esse bloco se encontra em alguma das caches dedicadas de outros núcleos e em quais. A L3 consegue saber isso devido ao vetor de 4 bits que cada um dos seus blocos possui e que já referimos, onde regista a presença ou não desse bloco nos diferentes núcleos.
Caso não exista em nenhuma das caches dedicadas ele é enviado à cache L1 do núcleo requisitante no estado de Exclusivo.
Caso exista em alguma das outras caches então ele é enviado ao núcleo requisitante no estado Partilhado. Se existir só em mais uma cache, então estará nessa cache no estado Exclusivo e o seu estado nessa cache é alterado para Partilhado. Se existe em mais do que uma das caches dos outros núcleos, então o seu estado já é partilhado, pelo que não há lugar a qualquer alteração do seu estado nessas caches.
O bloco não está na L3 e então é necessário lê-lo da Memória.
Vai-se dar um preenchimento de linha (bloco) de cache, com o registo de um bloco novo na L3 e na L1 ou L2, ou nas duas. A este bloco é atribuído o estado de Exclusivo, pois ele vai estar presente só numa cache de um núcleo.
O bloco está, no estado Modificado, na cache dedicada de outro núcleo.
Através de Bus Snooping, o controlador de cache do núcleo B, que contém o bloco requisitado pelo núcleo A no estado de Modificado, deteta que outro núcleo está a tentar aceder a um local de memória desse bloco.
Então rouba (snoop) o barramento para si, procede a um write back implícito desse bloco, muda o seu estado para Partilhado e envia-o ao núcleo A.
Também a MMU possui a capacidade de Bus Snooping, pelo que por si própria, ao detetar esta situação garante a atualização do bloco em L3 e em MP.
O write back implícito corresponde ao facto de o núcleo B proceder à transferência do bloco para o núcleo A de imediato, sem ter a confirmação da atualização, que é responsabilidade da MMU.
Um bloco que se encontre nos estados de Exclusivo ou Partilhado pode ser livremente lido por qualquer dos núcleos que o detenham, sem que qualquer tipo de comunicação seja necessária, pois contém os dados mais atuais da memória.
Escrita num bloco presente em L1 ou L2
Quando um núcleo pretende escrever um dado em memória começa por consultar a cache L1. Se o bloco que contém esse dado se encontrar na L1 ou na L2, sendo daí transferido para a L1, duas situações se podem dar:
O bloco está no estado de Exclusivo.
Neste caso o núcleo procede à alteração do conteúdo do bloco e o seu estado transita para Modificado. Nada mais é feito, porque ele não existe em mais nenhuma cache dedicada e porque estamos numa política de escrita de write back.
O bloco está no estado de Partilhado.
Neste caso o núcleo emite um RFO (Request For Ownership – Pedido de propriedade) pelo barramento, assume a propriedade do bloco e altera o seu estado para Modificado. Os restantes controladores de cache, que estão à escuta, ouvem um RFO no barramento e, caso tenham o mesmo bloco nas suas caches, passam o seu estado para Inválido, pelo que numa próxima consulta que façam ao mesmo vão ter uma cache miss. Esse bloco passou a ser único nas caches dedicadas, pelo que qualquer consulta ao mesmo por parte do núcleo que o contém, é feita livremente.
O bloco está no estado de Modificado.
Se o bloco se encontra nas caches dedicadas de um núcleo no estado de Modificado é porque ele só existe nesse núcleo. Assim, o núcleo procede à escrita do valor pretendido e mantém o estado do bloco.
Escrita num bloco Ausente de L1 e L2
Neste caso, a procura para escrita nas caches L1 e L2 do núcleo A, que pretende escrever um dado em memória, falha e dá cache miss.
O bloco está, no estado Modificado, na cache dedicada de outro núcleo.
Através de Bus Snooping, o controlador de cache do núcleo B, que contém o bloco requisitado pelo núcleo A no estado de Modificado, deteta que outro núcleo está a tentar aceder a um local de memória desse bloco. Então rouba (snoop) o barramento para si, procede a um write back implícito desse bloco, muda o seu estado para Partilhado e envia-o ao núcleo A.
Agora o núcleo A vai escrever nesse bloco, vai mudar o seu estado para Modificado, vai colocar essa informação no barramento e o núcleo B vai passar o estado desse bloco para Inválido.
Há uma forma mais simples de fazer isto, com muito menor ocupação da largura de banda do barramento.
Quando o núcleo B deteta que o núcleo A pretende efetuar uma escrita num local de memória pertencente a um bloco que ele detém no estado de Modificado, envia-o nesse estado ao núcleo A, passando-lhe portanto a responsabilidade pelas modificações desse bloco e mudando o estado desse bloco na sua cache para Inválido.
O núcleo A vai escrever então num bloco no estado de Modificado, situação que já vimos atrás e que não dá direito a qualquer comunicação.
O bloco não existe em nenhuma das caches dedicadas dos núcleos.
Neste caso a indicação de cache miss é colocada no barramento e não é roubada por nenhum controlador de cache de outro núcleo, chegando assim à MMU.
Trata-se então de um primeiro acesso a um bloco, pelo que a MMU, depois de o recolher de L3 ou da memória, o envia para a L1 do núcleo requisitante no estado de Exclusivo. Então o núcleo procede à escrita do dado no bloco que acabou de receber e altera o seu estado para Modificado.