
Visão síntese de NTFS
Vamos então recapitular a sequência das operações lógicas de arranque de um computador com o seu bootable Volume formatado em NTFS até à chegada ao ficheiro que procurávamos
- Quando se inicia o computador, o processador é levado a executar o programa contido no BIOS, o qual, depois de concluídas as suas rotinas, põe em execução o código contido no MBR (Master Boot Record).
- A leitura deste código, localiza as partições do HDD, verifica qual é a partição ativa Bootable e passa a execução do código para o seu PBS (Partition Boot Sector).
- Por sua vez, este código, depois de concluída a sua função, passa a execução para o SO e informa-o da localização do início da MFT (Master File Table).
- O SO identifica a MFT e suas características. Procedendo à leitura das suas primeiras entradas, os ficheiros de metadados, o SO obtém informações sobre a própria MFT, sobre a definição dos Atributos que vão estar presentes na caracterização dos ficheiros nos registos da MFT, enfim sobre tudo o que necessita para operar o sistema de ficheiros.
- O SO acede ao Diretório Raiz, ele próprio um ficheiro de metadados, definido nos primeiros registos de metadados da MFT e fica a saber quais são os ficheiros e diretórios que integram essa raiz e qual a entrada de cada um na MFT.Nessa altura o SO está na base da árvore cujos ramos o vão levar a todos os destinos possíveis dentro do Sistema de Ficheiros.
- Consultando essas entradas, o SO obtém informação sobre todos os inícios possíveis de todos os caminhos para um ficheiro.Os ficheiros são sempre referidos pelo seu caminho ou path.
O pathname de um ficheiro é o seu nome integrado num caminho pelos diversos nós da árvore que levam até ele, partindo da raiz. Como por exemplo, o pathname do ficheiro que procurámos,
G:\Todas as Imagens\Diversos Pessoais\Diversos 1\Diversos 1999\Picture4.jpg
é o nome ou pathname com que ele é apresentado ao SO para o procurar no Sistema de Ficheiros. Portanto, quando o SO é chamado a encontrar um ficheiro é-lhe fornecido um pathname. De seguida o SO só tem que ir encontrando no volume as posições dos diversos elementos que lhe vão indicando o caminho.
Vamos então reconstruir simplificadamente o caminho que seguimos para encontrar o nosso ficheiro a partir da raiz, usando para isso a Figura 53 e as alíneas nela representadas e à frente descritas

- a) O sistema já sabe que “Todas as Imagens” é um diretório apontado pela raiz, ou o primeiro nó num dos ramos da árvore que saem da raiz e sabe qual é a sua entrada na MFT. Pergunta à MFT qual a localização do índice de “Todas as Imagens” no volume.
- b) Recebida essa informação da MFT, vai encontrar o índice de “Todas as Imagens”, que lhe diz todos os ramos e nós para que ele aponta. Seleciona nesse índice o nó (diretório) que se encontra no ramo que lhe interessa, “Diversos Pessoais” e obtém a sua entrada na MFT.
- c) Vai à entrada de “Diversos Pessoais” na MFT saber a localização do seu índice no volume.
- d) Vai ao volume consultar o índice de “Diversos Pessoais” e verificar qual é a entrada na MFT de “Diversos 1”.
- e) Vai à entrada de “Diversos 1” da MFT saber qual é a localização em volume do índice de “Diversos 1”.
- f) Consulta o índice de “Diversos 1” para saber qual é a entrada na MFT de “Diversos 1999”.
- g) Vai à entrada de “Diversos 1999” na MFT saber onde fica o índice de “Diversos 1999” no volume.
- h) Vai ao volume ler o índice de “Diversos 1999” e obtém a entrada na MFT do nosso ficheiro “Picture 4.jpg”.
- i) Vai então de novo à MFT ler a entrada onde se encontra “Picture 4.jpg”, para obter a sua localização.
- j) Finalmente vai ao volume ao local onde Picture 4.jpg se encontra e pode atuar sobre ele.
São estes passos que se podem acompanhar também na figura 39 na evolução dos níveis de indexação numa imagem do Explorador do Windows
Então, de cada vez que o SO precisa de encontrar um ficheiro no disco tem de efetuar todas estas operações?
Não, não tem, porque para isso o SO cria uma cache de Diretórios, onde vai guardando referências diretas para todos os nós ou diretórios por onde vai passando. Esta cache será tanto mais completa quanto mais memória RAM o SO tiver disponível, podendo tornar-se mesmo extremamente rápido após algumas consultas.
Será assim que, consulta a consulta, o SO vai ficando com o conhecimento da constituição da árvore de diretórios ou nós e todas as suas ramificações, sendo-lhe a partir daí muito rápida a consulta de qualquer um desses nós, com a apresentação de todos as folhas (os ficheiros) ou nós filhos (outro nível de diretórios), que irá também ficar em cache de nós.
Com esta forma estruturada de organização do NTFS, verificamos que a dimensão da MFT não tem influência na eficiência do sistema. Definido o caminho para um dado ficheiro (pathname), que é fornecido ao SO de cada vez que lhe é pedido para o aceder, uma vez encontrada a descrição do mesmo na MFT, o SO tem lá toda a informação de que necessita para o aceder no volume.
O caminho para os diversos ramos da árvore que têm folhas, já o SO conhece (ou vai conhecendo), se tiver memória RAM com fartura.
Queremos no entanto relembrar todas as leituras de cabeçalhos, atributos, entradas de índice, mapas de bits e outras, que foram feitas. Com tantas indicações sobre cada ficheiro, será fácil a sua corrupção no caso de um registo ser interrompido antes de atualizar toda a informação da MFT inerente a esse ficheiro, inclusive nos ramos superiores.
Daí a existência do $LogFile, cuja única função é o registo atómico (enquanto não confirmada, o programa não prossegue) de toda essa informação sob a forma de um só registo. Posteriormente, esse registo é lido e a sua informação distribuída por todos os registos que foram afetados pela operação que incidiu sobre o ficheiro.
Durante o Boot do computador, o SO verifica sempre a consistência do sistema de ficheiros. E fá-lo precisamente por recurso aos elementos de que dispõe no $LogFile.
Na figura 54 (a seguinte) apresentamos uma simulação gráfica da árvore de indexação que dá acesso a todo o conteúdo do volume, que nós percorremos desde a raiz até ao ficheiro que procurávamos. Claro que nós só ficámos a conhecer as folhas de um dos muitos nós de último nível.
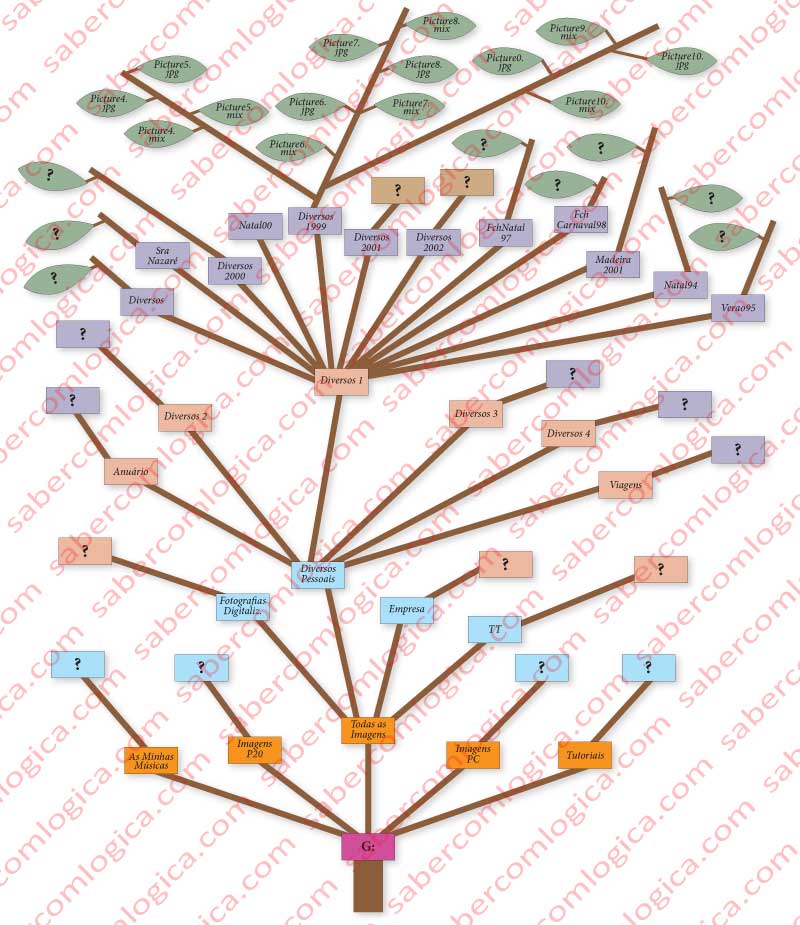
Ao chegar a cada um dos nós, o sistema vai perguntar a um INDEX:
Quem são os teus filhos? Quem é o teu Pai?
O INDEX diz-lhe quem são e fornece-lhe uma entrada da MFT para cada um deles, onde se pode saber onde estão.
FAT (File Allocation Table)
O sistema de ficheiros FAT (File Allocation Table) foi concebido para servir os primeiros PC que funcionavam sob DOS (Disk Operating System). Foi graças a eles que a capacidade de desenvolver aplicações e dar asas à imaginação com um computador desceram até casa do comum cidadão.
Porque, como já dissemos, o FAT (File Allocation Table) nasceu em eras informaticamente pré-históricas, a sua primeira versão dava pelo nome de FAT8. mas começaremos a nossa análise pelo FAT12, o primeiro mais globalmente conhecido.
Mas antes, para percebermos o que isto quer dizer, vamos dar só uma ideia base da constituição do FAT.
Tal como o nome diz, derivando disso mesmo, a base deste sistema de ficheiros reside numa Tabela de Alocação de Ficheiros.
Como funciona? Já lá vamos.
Para já, vamos reter que a cada cluster de um HDD corresponde uma entrada na FAT, isto é, se o disco tiver 1.000 clusters a FAT tem 1.000 entradas. E também que, as entradas dessa Tabela se destinam a descrever clusters do disco.
Dito isto, FAT12 significa que cada entrada dessa tabela dispõe de 12 bits para fazer essa descrição. Será possível termos 2¹² = 4.096 clusters identificáveis (o disco pode ter mais mas não será reconhecida a sua existência).
Como o tamanho dos clusters pode ir de 512 Bytes até 64 KB, a maior dimensão possível de suportar em FAT12 para um Disco será de 4.096 x 64 = 262.144 Kb ou 256 MB, o que, para o tempo era já uma exorbitância.
Ora, considerar sequer a hipótese de utilizar clusters de 64 KB equivale a deitar fora mais de 50% do disco, devido ao efeito que já definimos como slack, correspondente ao espaço não utilizado em cada cluster que recebe ficheiros de menor dimensão, ou partes restantes dos mesmos. Imaginemos 10 ficheiros de 20 KB e 10 de 70 KB. Na realidade precisam de 900 KB, a sua dimensão real. Mas, como cada cluster só pode conter 1 ficheiro ou parte do mesmo, o espaço realmente ocupado em disco será de 10+20=30 clusters, ou seja, 1920 KB.
Como solução para o crescimento dos discos, surgiu o FAT16, vulgarmente conhecido por FAT, pois constituiu o standard deste sistema. Com 16 bits por entrada de tabela, já podia definir 216 = 65.536 clusters, o que permitia utilizar discos de 256 MB (com clusters de 4KB) até 2 GB (com clusters de 32 KB) ou mesmo 4 GB (com clusters de 64 KB).
Finalmente, foi na 2ª revisão do Windows 95 que surgiu o FAT32, que dispõe de 28 bits de endereçamento (4 são reservados para indicadores do sistema). Teoricamente seria assim possível ter 2²⁸, ou 268.435.456 clusters.
Digo teoricamente porque a este valor corresponderia uma tabela com 268.435.456 entradas a 4 Bytes cada (32 bits), ou seja, com a dimensão de 1 GB, o que é impensável para essa tabela. Não devemos esquecer que, para que o sistema seja eficiente, a tabela deverá estar sempre em memória. E reservar 1 GB de RAM só para a FAT era impensável, principalmente atendendo à menor dimensão da RAM nessa ocasião.
O Windows Server 2003, não formatava em FAT32 discos com mais de 32 GB, com setores de 16 KB e, portanto, com uma FAT com 2.097.168, ou 8 MB, o que já era na ocasião perfeitamente aceitável.
Claro que esta limitação era feita pelo Server 2003, numa ocasião em que já dispunha do NTFS para volumes de dimensões superiores.
Retenhamos no entanto essa dimensão, uma vez que também nós agora dispomos do NTFS e de discos de dimensões muito superiores.
Vamos lá ver como funciona o FAT. Num disco formatado com FAT, o MBR (Master Boot Record) é idêntico ao já visto e o PBS (Partition Boot Sector) dá como informações fundamentais para este sistema:
- O número de cópias que mantém (geralmente 2 – original e segurança) da Tabela de Alocação,
- A sua dimensão e da sua cópia em setores,
- O número de setores reservados e
- O número máximo de entradas que pode ter o Diretório raiz, normalmente 512.
Estamos a descrever o FAT16, por ser mais fácil para fazer entender o seu funcionamento. O PBS para FAT 32 teve que ser estendido, passando a ocupar mais do que um setor, de forma a poder dar as informações essenciais ao SO, evitando assim que o SO tivesse que ler toda a FAT, que aumentou substancialmente de dimensão.
O sistema FAT é composto de dois elementos fundamentais:
- As entradas de diretório, em que cada ficheiro (diretório também é ficheiro) tem uma entrada que o descreve e o número do setor em que se inicia. Cada entrada de Diretório dispõe de 32 Bytes.
- A tabela de alocação de ficheiros com 16 bits por entrada. (FAT16).
Entradas de Diretório
As entradas de diretório no sistema FAT são todas com o nome de ficheiro em DOS, isto é, com o nome reduzido a 8 carateres mais 3 para extensão. Vamos analisar estas entradas com um ficheiro de nome:
“Este nome é só para demonstração.doc”
Se o nome do ficheiro tivesse só 8 carateres e 3 de extensão , a descrição do ficheiro ficaria como a que consta da figura 56a, que aqui apresenta o nome do ficheiro reduzido aos 8 carateres mais 3 para extensão, determinados da forma que já vimos atrás.
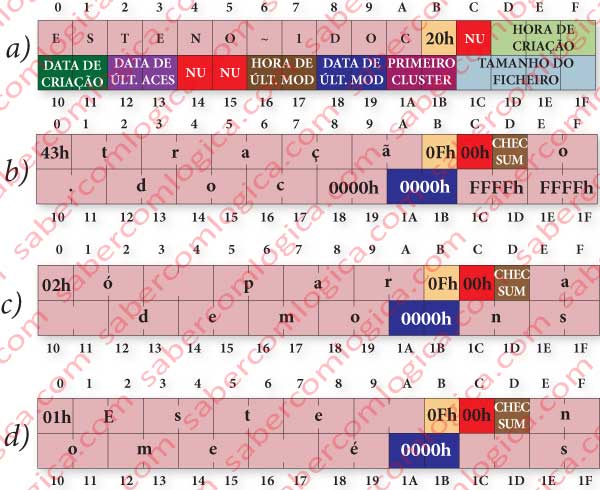
O nome em DOS é descrito em ASCII, com restrição ao uso exclusivo de maiúsculas, números e só alguns dos carateres especiais. Na construção do nome até o ponto é ignorado, pois é implícito e colocado pelo sistema entre os primeiros 8 e os restantes 3 carateres do nome.
Se o nome for grande, como é no nosso caso, então a sua representação é feita por extensão a mais entradas de diretório para o mesmo ficheiro, destinadas exclusivamente à descrição do nome, no nosso caso mais 3 entradas. Já veremos mais adiante como é que o FAT faz para indicar ao sistema que se trata de um nome longo.
A entrada principal de diretório fica exatamente como para um ficheiro de nome pequeno, tal como representada na figura 56a e o significado dos diferentes 32 Bytes que compõem a entrada é como segue:
- Os primeiros 11 Bytes (00h a 0Ah) são usados para o nome (8 para o nome e 3 para a extensão), sendo que o ponto é omitido. O sistema inclui-o.
- O 12º Byte (0Bh) define o atributo do ficheiro, constituído por flags de bit no conjunto de 8 bits, no nosso caso 20h, em binário 00100000, o que significa que se trata de um ficheiro e que terá de ser incluído no próximo backup, como podemos verificar de seguida:
- 0000 0001 – Só de leitura.
- 0000 0010 – Escondido.
- 0000 0100 – Sistema.
- 0000 1000 – Etiqueta de volume . A etiqueta de volume está guardada no diretório raiz.
- 0001 0000 – Diretório. É esta entrada que diferencia ficheiros de diretórios.
- 0010 0000 – Arquivo. Este bit serve só para os backup incrementais. De cada vez que é feito um backup este bit é colocado a 0. Se o ficheiro for modificado é colocado a 1, ficando o sistema informado de que deve fazer o seu backup.
- O 13º Byte (0Ch) não é utilizado pelo FAT16.
- Os 14º, 15º e 16º Bytes (0Dh, 0Eh, 0Fh) definem a Hora de criação do ficheiro descrito pela entrada.
- Os 17º e 18º Bytes (10h e 11h) definem a Data de constituição do ficheiro descrito pela entrada.
- Os 19º e 20º Bytes (12h e 13h) definem a Data do último acesso ao ficheiro descrito nesta entrada.
- Os 21º e 22º (14h e 15h) Bytes não são utilizados pelo FAT16.
- Os 23º e 24º Bytes (16h e 17H) definem a Hora da última modificação do ficheiro descrito.
- Os 25º e 26º Bytes (18h e 19h) definem a Data da última modificação do ficheiro descrito nesta entrada.
- Os 27º e 28º Bytes (1Ah e 1Bh) definem qual o primeiro cluster onde se encontra o ficheiro descrito.
- Do 29º ao 32º Bytes (1Ch, 1Dh, 1Eh e 1Fh) indicam o tamanho do ficheiro descrito.
Bom, e agora como é que o sistema sabe que o nosso ficheiro tem um nome longo?
A técnica usada pelo FAT para informar que se trata de um ficheiro de nome longo é colocar as entradas correspondentes à extensão do nome antes da entrada principal do ficheiro e, fá-lo pela ordem inversa, isto é, da última extensão para a primeira.
Nas entradas de extensão de nome, o atributo é levado a 0Fh, o que em binário é 00001111. Os quatro primeiros atributos em Set é uma situação não esperada pelo DOS que o informa que deve ignorar essa entrada, mas para também não a utilizar como se estivesse livre nem a eliminar.
As entradas de extensão estão representadas nas figuras 56b, c e d.
Nas entradas de extensão de nome cada carater ocupa dois Bytes, porque é descrito em UNICODE. Cada entrada de extensão é composta como segue:
- O 1º Byte corresponde ao número de sequência. Este número indica qual a sequência da entrada de extensão na composição total do nome (por ex. 01h, 02h, 03h,…). A última entrada de extensão terá sempre o bit 6 a 1, sendo sempre portanto igual ou superior a 40h (40h mais a sequência natural dessa entrada).
- Os 10 Bytes seguintes (01h a 0Ah) são utilizados para carateres do nome.
- O atributo (0Bh) está sempre a 0Fh numa extensão de nome.
- O Byte 0Ch não é utilizado.
- O Byte 0Dh é usado para o Checksum de verificação da conformidade do nome DOS.
- Os 12 Bytes seguintes (0Eh a 19h) são utilizados para carateres do nome.
- O 2 Bytes do primeiro Cluster (1Ah e 1Bh) estão sempre a 0000h.
- Os últimos 4 Bytes (1Ch a 1Fh) são utilizados para carateres do nome.
Verificamos que em cada extensão são utilizados 26 Bytes para carateres do nome. Como o nome é representado em Unicode, com 16 bits ou 2 Bytes por carater, cada entrada de extensão representa 13 carateres. O número máximo de entradas para extensões do nome por entrada de ficheiro, será de 20, ou seja, 255 carateres.
No fim do nome são acrescentados 2 bytes a 00h, ou seja um carater a 0000h. A partir daí todos os Bytes dos espaços para carateres não utilizados nessa entrada, serão preenchidos por FFh.
Bom, já vimos como é uma entrada de diretório. Mas, por aquilo que se percebe, é a entrada de diretório de um ficheiro que se nos vai informar qual é o primeiro cluster em que ele se encontra.
Então como é que chegamos à entrada de diretório de um ficheiro?
Vamos começar pelo Diretório Raiz, a origem de todos os caminhos. As entradas de ficheiros no diretório raiz estão limitadas a 512. Nos restantes diretórios não há limitações.
Tal como em NTFS, também aqui os diretórios são tratados como ficheiros.
O Diretório Raiz começa exatamente após o termo da cópia da FAT. Daí a importância das informações fornecidas pelo PBS, que há pouco referimos e que permitem ao SO determinar o seu início. Ver na figura 12-55 a forma de distribuição dos registos FAT na parte inicial do volume.
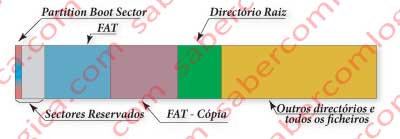
É o Diretório Raiz que contém os primeiros diretórios de uma cadeia hierárquica idêntica à que acabámos de ver para o NTFS. No caso do nosso exemplo, o diretório raiz seria G:.
Se olharmos para a figura 12-54 ela pode representar também a forma de chegarmos a uma entrada de diretório de um ficheiro em FAT. Um ficheiro é sempre referido pelo seu pathname e a sua procura é feita por todos os componentes desse pathname (nome do caminho).
Ao encontrar no Diretório Raiz a entrada de diretório do primeiro diretório, “Todas as Imagens”, no caminho para o ficheiro, essa entrada de diretório indica o primeiro cluster onde as entradas de diretório referentes ao seu conteúdo se encontram.
Ao ler a entrada de diretório de “Todas as Imagens”, encontra lá a entrada de Diretório de “Diversos Pessoais”, a qual diz onde “Diversos Pessoais” se encontra descrito.
E assim vai caminhando até que finalmente encontra a entrada de diretório do ficheiro “Picture4.jpg”.
Na entrada de diretório deste ficheiro, está descrito o primeiro cluster em que ele e encontra.
Mas este ficheiro ocupa muito mais do que um cluster. Assim como a descrição dos diretórios também pode ocupar. Só o Diretório Raiz não pode. E a entrada de diretório só nos aponta o primeiro cluster, aquele onde começa.
Então e os outros?
Isso é precisamente o que a Tabela de Alocação de Ficheiros nos diz.
Tabela de Alocação de Ficheiros
Vamos então passar agora à Tabela de Alocação de Ficheiros, aquela que dá nome ao sistema de ficheiros. Como vimos agora, na entrada de ficheiro é indicado o primeiro cluster em que se encontra o ficheiro.
E o resto?
Bom, se formos à entrada da Tabela de Alocação correspondente a esse primeiro cluster, nela encontra-se descrito o cluster seguinte onde se encontra o ficheiro e assim sucessivamente até que uma entrada refira FFFFh em 16 bits (FAT16).
Vamos de novo relembrar como é que em FAT se encontra um ficheiro: partindo da entrada de diretório, que indica o primeiro cluster em que se encontra o ficheiro, temos que ir de entrada em entrada da FAT à procura do cluster seguinte, até chegarmos ao último.
Portanto, o número encontrado em cada entrada da FAT corresponde ao cluster seguinte que contém o ficheiro e à correspondente entrada da FAT onde se deve ler o valor do cluster seguinte.
Imaginemos então um ficheiro de 22 KB fragmentado. Admitindo que cada cluster tem 4 KB, este ficheiro ocupa 6 clusters. Que podem estar, por exemplo, em 3 regiões diferentes do disco. E o SO vai ter que ler todas as entradas da Tabela para saber onde se encontra a totalidade do ficheiro, cluster a cluster.
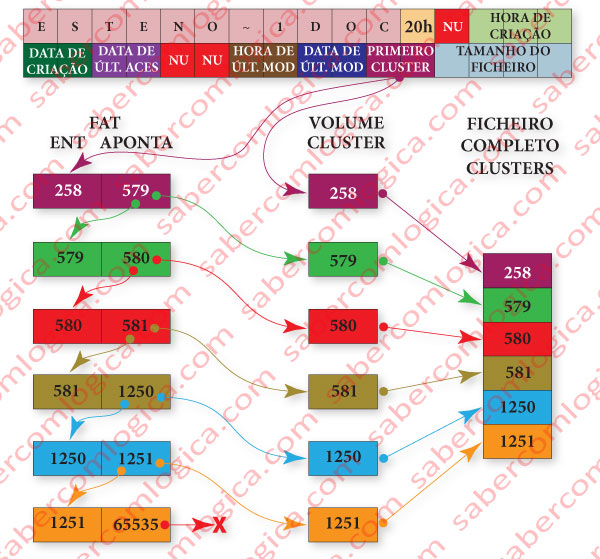
Vamos analisar a figura 12-60 para melhor entendermos o que descrevemos:
Com a informação do primeiro cluster contida na entrada de diretório do ficheiro (suponhamos 258), o SO lê o referido cluster e a entrada correspondente na FAT.
- O conteúdo da entrada 258 da FAT (suponhamos 579) representa o cluster seguinte onde está o ficheiro, que também deve ser lido, bem como o conteúdo da entrada 579 da FAT.
- O conteúdo da entrada 579 da FAT (suponhamos 580) diz ao SO que deve ler o conteúdo do cluster 580 e a entrada 580 da FAT.
- O conteúdo da entrada 580 da FAT (suponhamos 581) diz ao SO que deve ler o conteúdo do cluster 581 e a entrada 581 da FAT.
- O conteúdo da entrada 581 da FAT (suponhamos 1250) diz ao SO que deve ler o conteúdo do cluster 1250 e a entrada 1250 da FAT.
- O conteúdo da entrada 1250 da FAT (suponhamos 1251) diz ao SO que deve ler o conteúdo do cluster 1251 e a entrada 1251 da FAT.
- O conteúdo da entrada 1251 da FAT ( FFFFh ou 65535) diz-nos que este era o último cluster do ficheiro.
Assim e em conclusão:
- O ficheiro corresponde aos clusters 258, 579, 580, 581, 1250 e 1251.
- Para ler o ficheiro do disco têm que ser lidas as entradas 258, 579, 580, 581, 1250 e 1251 da FAT.
Consegue-se assim perceber que o FAT não é adequado para discos de grande capacidade. E por grande capacidade, segundo o Windows entenda-se 32 GB, que estabelece como limite máximo para formatar em FAT.
Ora 32 GB já não se usa. A não ser em pequenas partições, em disquetes, em cartões de memória flash, em Pen drives e em muitos dispositivos portáteis como PDA, câmaras digitais ou telemóveis que ainda possam suportar FAT.
Nestas situações o FAT pode ser considerado mais rápido do que o NTFS pois este tem uma enorme quantidade de parâmetros e registos por ficheiro. O sistema de ficheiros FAT não assegura a consistência do sistema de ficheiros nem fornece segurança ao nível do ficheiro para utilizador e grupos de utilizadores.
Com exceção dos casos referidos o FAT foi substituído pelo NTFS:
- O NTFS assegura a consistência de ficheiros.
- NTFS fornece segurança ao nível do ficheiro para utilizador e grupos de utilizadores.
- Em NTFS, uma vez localizada a entrada na MFT para o ficheiro foi encontrada toda a informação sobre o mesmo bem como a sua localização no Volume, independentemente do seu tamanho.