
Application Layer
As already stated, the application layer is where the applications (programs) that create or read the message to send or receive run.
The most common protocols for packaging these messages are:
- HTTP (Hyper Text Transfer Protocol), used for Web communications, i.e., to request and receive pages of Internet sites or to send or receive data to or from other computers.
- SMTP (Simple Mail Transfer Protocol), used to marshal the e-mail messages.
- FTP (File Transfer Protocol), used to package files that you wish to transfer.
- DNS (Domain Name System), used to know addresses of computers using their names.
- BitTorrent used to allow communication between multiple computers to share files.
There are many more but for now they will not be mentioned.
By describing these protocols, several network applications have already been referred, such as Web, electronic Mail and μTorrent.
Network applications use application-specific architectures which are:
- Client – Server architecture,
- Peer to Peer (P2P) architecture and
- Hybrid architecture, which combines the previous.
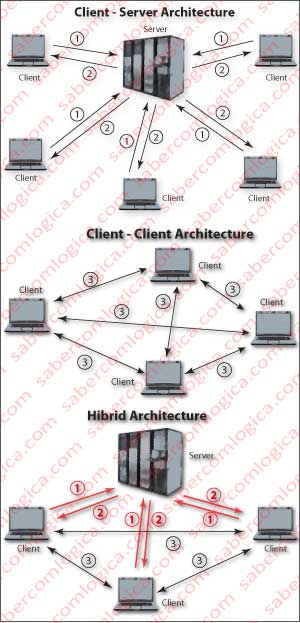
The Client-Server architecture requires a connection between a client and a server. The client makes requests (Figure 1a line 1) and the server provides services (Figure 1a line 2).
Client, for us as Internet users, is the Web Browser for the WEB (Internet Explorer, Google Chrome, Firefox, etc.) or Outlook (or similar mail client) for e-mail.
The Web Server is a machine that, being somewhere in the network, stores the objects that make up the pages that the clients request.
Thus, in the client-server architecture, the client requests an object to the server, which provides it.
The applications that use the first four protocols above mentioned (HTTP, SMTP, FTP and DNS) are client – server applications.
In this architecture clients do not talk to each other, i.e. they are not interconnected, they only communicate with servers.
In Peer to Peer architecture (P2P), the clients talk to each other (Figure 1b line 3). For that purpose they have specific applications that (for instance) seek the network for peers that have the file they want to receive, establish communication with those Peers and began to load the said file by blocks (download) from those Peers, while placing again blocks of those files (upload) in the network.
In the hybrid architecture, the peers ask a server through a client-server connection(Figure 1c lines 1 and 2) for the address of other peers that provide the desired file, establishing from there on a P2P connection with each other (Figure 1c line 3).
An example of this architecture are the programs that use the BitTorrent protocol, such as the application μTorrent, which surely the vast majority of those who are reading this text know. In this application, the client queries a server for a specific file, receiving the addresses of the seeders available for the requested file. Then the application establishes a P2P communication between its client (peer) and the other clients (peers). Just not to crush a mess, there is also an application with the name BitTorrent that uses the BitTorrent protocol.
To analyze all the protocols at each layer and on all possible networks it would likely to be written a book over 1,000 pages, which is certainly not our goal, here we will only analyze the WEB, one of the most common among all Internet users, consisting in the navigation through Sites and its pages.
Those who are interested to reach global or higher levels of knowledge will have to attend high school computing, and we would feel we won because someone found its vocation training.
When we click a link
Let’s see what happens and what is the activity that is developed after clicking on a link until we receive the page for that link.
Suppose a document you are reading has the following hyperlink, that we are interested in consulting
http://www.comdominiopartners.pt/index.html
Actually what an hiperlink does is using the URL (Uniform Ressource Locator) that it represents.
This URL has two components:
- The host name (WEB server in this case): www.condominiopartners.pt
- and the name of the object we want: /index.html
Then, clicking this link, we selected the URL it contains, and our browser will send a request via HTTP, the protocol used in web applications, as we have already referred.
Let’s see how the HTTP protocol works for this situation.
HTTP Protocol
First of all, we’ll talk about some strange names which we’ll refer in this paragraph.
HTTP is implemented on the client machine (browser) and server machine (Web Server) and describes the shape and structure that the two machines will use to exchange messages among themselves. It is therefore through HTTP that the two machines are going to talk to one another.
And what is that conversation about?
The client machine will ask for a Web page to the server machine, which consists of objects that the Web Server has stored.
A Web page is based on an object, the HTML (Hyper Text Markup Language).
HTML is a Web language defined as Markup language. Markup language is a textual language annotated so that the different texts that compose it stand out in what they represent.
The HTML object contains references to other objects that make up the page, such as images, JavaScript scripts, Java applets, Flash movies, CSS, etc.
From these objects we make a special reference to CSS (Cascade Style Sheet) object which is written in style sheet language and is used to define the presentation of a document written in a markup language, with special focus on HTML.
Style sheet language is a programming language that expresses the presentation of structured documents.
Analyze these languages isn’t, for now, the purpose of this work.
However we tell you how you can visualize the base code of HTML, CSS and JavaScript in a Web page. Any Browser has developer tools that emphasize this code. We can use the Web developer tools any browser provides but personally we use the Firebug with Firefox.
To learn about HTML, CSS or JavaScript programming languages, which are managed by the W3C (World Wide Web Consortium), you can visit the site from W3Schools: http://www.w3schools.com/
But first we must realize the work that the computer will have when that hiperlink is clicked. So let’s proceed. Not with this hiperlink but with the one we are using for our work:
http://www.comdominiopartners.pt/index.html
The HTTP protocol has a limited number of methods such as GET, POST, HEAD, PUT, DELETE.
The GET method is used when the HTTP protocol builds a request for a page to a Web server, the one which follows to the next layer of the protocol stack.
The message generated in our case will look like this:
GET /index.html HTTP/1.1\r\n
Host: www.condominiopartners.pt\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n
Accept-Language: pt-pt,pt;q=0.8,en;q=0.5,en-us;q=0.3\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7\r\n
Keep-Alive: 300\r\n
Connection: keep-alive\r\n
\r\n
or, with the symbols of carriage return and line feed translated
GET /index.html HTTP/1.1
Host: www.condominiopartners.pt
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: pt-pt,pt;q=0.8,en;q=0.5,en-us;q=0.3
Accept-Encoding: gzip, deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
where the first line is the request line and all other lines are the header lines. As we can see, the various lines are separated by one line.
At the end of the message there’s a Data body, which is used in the POST method, when the HTTP request sent to the server has to do with elements of a filled form in the client (browser), for example.

The general rule of an HTTP request message is consistent with Figure 2 which shows a schematic representation of the organization of a request (GET) HTTP.
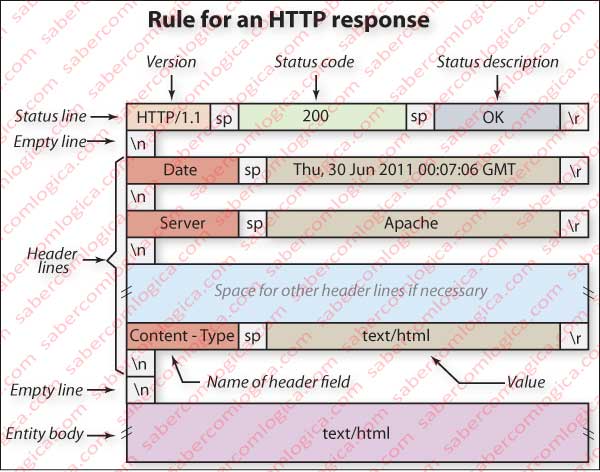
The server, upon receiving this request in its application layer generates an HTTP response message sending to the client the object that it requested.
This message will look like this:
HTTP/1.1 200 OK\r\n
Date: Thu, 30 Jun 2011 00:07:06 GMT\r\n
Server: Apache\r\n
Last-Modified: Mon, 31 Jan 2011 12:26:35 GMT\r\n
Accept-Ranges: bytes\r\n
Content-Length: 13822\r\n
Connection: close\r\n
Content-Type: text/html\r\n
\r\n
Line-based text data: text/html
or, with the symbols of carriage return and line feed converted:
HTTP/1.1 200 OK
&
Date: Thu, 30 Jun 2011 00:07:06 GMT
&
Server: Apache
&
Last-Modified: Mon, 31 Jan 2011 12:26:35 GMT
&
Accept-Ranges: bytes
&
Content-Length: 13822
&
Connection: close
&
Content-Type: text/html
&
&
Line-based text data: text/html
corresponding to the same template and separation lines described above. In this case there is an entity body filled out, with 13,822 Bytes that actually represent the object index.html requested, described in the line header with the title Content-Length.
For clarification purposes, index.html is the default name of a site home page.
The general rule of an HTTP response message is consistent with Figure 3, which gives a schematic representation of its organization.
The status codes are generally those indicated, highlighting as an example some of the most significant in each group:
1XX – Informational
2XX – Success
200 – OK
3XX – Redirection
301 – Moved Permanently
304 – Not Modified
4XX – Client Error
404 – Not Found
5XX – Server Error
503 – Service Unavailable
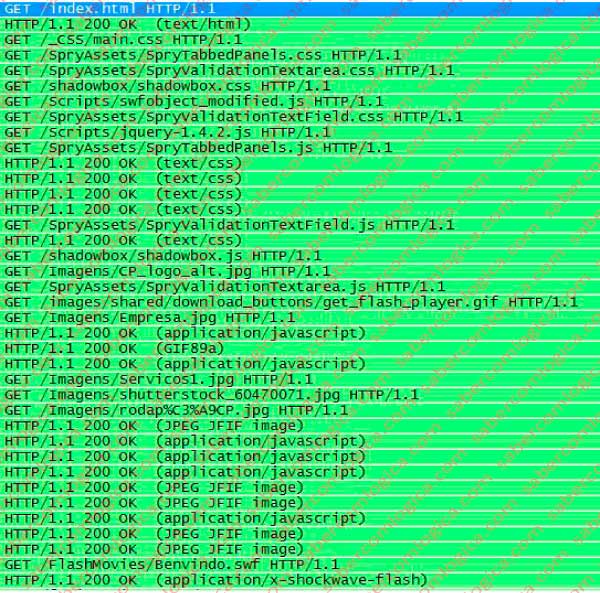
Once received by the browser (in the future we will call like this the HTTP client) the decoding of the index.html file states that must be obtained from the same Web server all the objects for which this piece points out, which are an integral part of the requested page.
This way are issued all the requests we can see in Figure 4 (beginning with GET), to whom correspond all the answers that also show in the same frame.
It is thus the number of HTTP messages exchanged between the browser and the Web Server to display a Web page that can easily be viewed, simply following the respective hiperlink.
I suggest you take the opportunity to see the html, css and javascript codes for that page, for example using the Firebug in Firefox.
But, as we insisted to highlight, this is the number of messages to be exchanged during the whole process between the client and server application layers (HTTP), specifically 19 requests and 19 responses. And the procession is just getting out of the churchyard.
Connections
It’s now time to introduce another important concept about connections, which consists on the persistence or non persistence of connections, depending on the way machines are configured.
If we look now on the messages exchanged between the machines (as described above), we find that the browser tells the server in the header row that it wants a persistent connection
Connection: Keep-Alive
but the server responds by saying that it doesn’t want this type of connection, but rather a non-persistent one, indicating in the end of the response to the request that it will close it according to the header row
Connection: Close
The fundamental difference between the two connection types is clear from its name, that is, if it remains alive until the final of the conversation or not.
When a conversation ends and no one closes it, it falls by itself after some time, specifically indicated in the header
Keep-Alive: 300
The persistent connection has advantages over the non-persistent one, as it allows all files that are linked with the index page to be required without having to establish a new connection for each.
The protocol for the establishment and termination of connections requires the deployment of a series of messages between the client and server, as we shall see briefly, that in addition to consuming more resources (buffers and variables) on the server makes the process slower on the whole.
The persistent connection can be with or without pipelining.
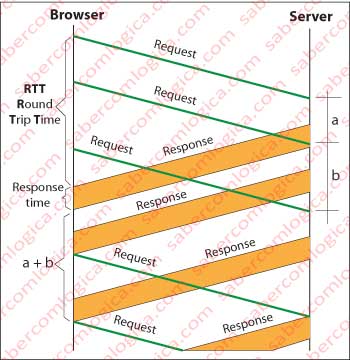
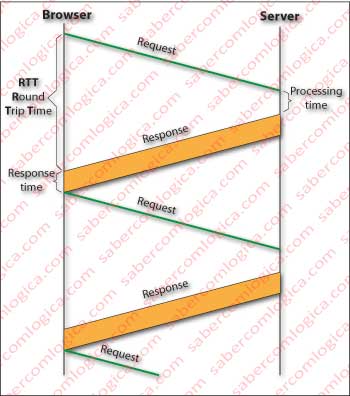
In non-parallel or stop and wait connections, as in Figure 5, the client waits for the completion of the response to a request to send another request. The total communication becomes much slower, as it will add up all the processing and transmission times from all messages and acknowledgments.
In parallel connections, as in Figure 6, the client sends in parallel (this is meant as a parallel sequence, because it can not send two concurrent requests), after the reception of a requested object, the requests for all objects pointed to by the received one. Thus communication is much faster, since it does not add up all the times of all messages.
This concept will be far better understood when we discuss the transport layer. We’ll get there.
Regarding this concepts, what happened with connection?
In our case, the server did not accept a persistent connection. If the browser had no way to get around the issue, we would certainly be much more time waiting for the page.
But in situations like this one, most browsers solve the problem by launching new connections, one for each request object, immediately after verifying the need for this object during the reading of the HTML file. And that is precisely what happened in our case, as we shall see when we realize the TCP.