
From our CPU to reality
Before we dive into the description of some details of a commercial CPU we are going to introduce some concepts which will help us to move from our imaginary CPU and a real one.
The μops and the Registers
The μops (micro operations), as we already defined, are the most elemental operations that a CPU executes over its Registers.
All the actions that we distinguished during the analysis of our CPU which were executed in the sequence of an Opcode decoding, actually are μops executed over the CPU Registers.
The CPU is provided with the necessary Registers to fulfill all its μops as:
- to determinate the program instruction to be executed,
- to put the instructions to be requested to the IM,
- to put the received instructions,
- to put the Opcodes to be decoded,
- to put the DM addresses to be queried,
- to put the data returned by the DM,
- to put the data over which the operations will be executed,
- and so on.
Every CPU operation results from a μop over its Registers:
- executing arithmetic or logical operations with the data they contain, s
- hifting the bits of the data they contain,
- writing data in them,
- transferring data between them,
- and so on.
All these μops are executed accordingly with the control signals resulting from the Opcode decoding, which route the signals through the CPU circuits in order they can execute any of the necessary μops to fulfill that instruction.
It’s what we’ve just seen in our CPU in a very simplified manner. Once again, the complexity will be the result of the sum of many simplicities.
The μops are atomic operations, i.e. they are not decomposable into other operations and execute within a clock cycle.
For now we stay like this with this theme.
The CPU Activity Cycle
In our imaginary CPU the PC pointed to the instruction to be read (Fetch), the instruction was read and its Opcode decoded (Decode) and through the interpretation of the generated control signals executed (Execute) in the several elements of the CPU architecture, in this including the reading or writing operation in the DM address described by the constant in the instruction read from the IM.
In a same action these 3 stages from the CPU operation cycle and the μops each one included, were executed. It was good for us to understand how and Opcode is decoded in control signals which will execute the μops which will fulfill the instruction.
The reality of a present commercial CPU is very different. Due to its huge complexity, the different stages of the CPU operation cycle (even being part of the same instruction) will execute in different circuits specific for each of them and in different clock cycles.
And each one of the stages needs the information provided by the previous one to start. We can’t Decode while we don’t know what. We can’t Execute while we don’t have the Opcode decoded into its control signals and defined the μops to execute. And all starts by the Fetch, where a memory access is executed.
The CPU and the Memory
The memories are very complex circuits apart from the CPU core. So complex and so important that they will receive a special treatment by this work in separated Chapters which will deal with the Main Memory (MM), the Cache Memory, the Operating Systems and their Virtual Memory and the great computer memory, the Hard Disk Drive (HDD).
For now we are going to approach this theme without any details about the way how the access is made. The CPU provides the addresses to read instructions or to read or write data and delivers them to the MMU (Memory Management Unit) which will deal with the complex process of finding and returning the intended value.
The MMU takes time to do its job, to which we call latency (access and waiting times):
- From 7 to 50 clock cycles, if the MMU manages to solve the question within the several cache levels.
- Of about 200 clock cycles if the MMU has to access the MM to solve the question.
- Of tenth millions of clock cycles if the MMU has to access the HDD to solve its problem.
What’s important to retain here is that the Fetch stage, as it includes a memory access to read the instruction, will have to be separated rom the other stages, which will have to wait by the result of this one.
The CPU and the ALU
As we could see when we built the division circuit, that arithmetic operation is executed by iterations, one per clock cycle. To the multiplication goes the same. Although many logical strategies were created in order to reduce the number of necessary clock cycles to execute the operations, when we are dealing with 64 bits numbers we are surely dealing with many clock cycles of latency for one of those operations.
Therefore, the execution will it too deal with latencies, either in the ALU or in DM accesses, mainly in these last ones, reason why the Execution stage too will have to be separated from the remaining.
The CPU and the Decoding
The decoding process of a modern CPU is very complex. The code is read under the shape of macro instructions, a little more complex than those we have seen and must be converted into a set of micro operations executable by the CPU.
The decoding process includes predictive methods who allow the anticipation and out of order execution of many instructions in parallel.
In conclusion, all the decoding activity is executed by a multiplicity of μops and through several clock cycles. Thus, the Decoding stage too as to be separated from the others.
The Operations parallelization
We have just found 3 execution stages of an instruction which must be executed separately, each one of them using different resources of the CPU:
Fetch, Decoding and Execution
We stop here with our evolution to the reality and assume that each one of these stages is a μop and executes in a clock cycle. Off course this is far from the reality but, as the complexity is obtained through the sum of simplicities, we will proceed with a slow evolution to better understand a new concept that allows the simultaneous execution of several μops in parallel, the Pipeline.
Pipeline
Pipeline or processing in stages, is the technic that the CPU uses to execute the not in a strictly sequential way but in parallel or in stages, according to the available resources.
Remember that for questions of simplicity in the analysis we are doing an instruction is executed by 3 μops, fetch, decoding and execution, each one using proper resources and executing in a clock cycle.
The basic purpose of pipeline consists in initiating a new μop for each clock cycle, using for that the available resources in the CPU.
When the Fetch for an instruction terminates its Decoding begins and the resources for a new Fetch will be available. When Decoding terminates the Execution begins and the resources for Fetch and Decoding stay available. Normally only each 3 cycles a new instruction will begin, each one after the integral completion of the previous one. But through Pipeline a new instruction can be initiated at each clock cycle using the available resources. So being:
When the 1st instruction will be in the Execution stage, releasing the resources for Fetch and Decoding, a 2nd instruction will be in the Decoding stage having released the Fetch and a 3rd instruction will already be at the Fetch stage.
This way, using the pipeline, we can reproduce the behavior of our imaginary CPU executing all the stages of Fetch, Decoding and Execution in a same clock cycle. But now we won’t be executing the 3 stages of the same instruction but one of the different stages of each of the 3 instructions.
The ideal and optimistic purpose of the pipeline is the total occupation of the CPU clocks, thus concluding an instruction for each clock cycle, as we can see represented in Figure 41B, unlike the sequential execution represented in Figure 41A. where an instruction was terminated every 3 clock cycles.
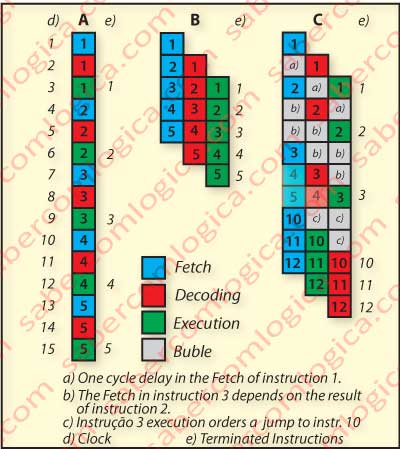 But of course this is not possible, because many conditions can cause delays or losses in the chain of running stages, as it’s intended to illustrate in Figure 41C for three possible situations:
But of course this is not possible, because many conditions can cause delays or losses in the chain of running stages, as it’s intended to illustrate in Figure 41C for three possible situations:
a. – There is a delay in the memory access and instruction 1 takes 1 more clock cycle to complete the quest. The entire sequence of stages in the chain will in consequence delay 1 clock cycle.
b. – The fetch in instruction 3 depends on the result of the execution of instruction 2. It will have to wait 2 clock cycles for its result. The entire sequence of stages in the chain will in consequence delay 2 clock cycles.
c. – Instruction 3 performs a jump to the instruction 10. All the stages of the instructions executed by anticipation (instructions 4 and 5) will be ignored. The chain of stages is emptied and is restarted from the end of instruction 3.
In any of the previous situations are generated empty spaces in the stages chain called Bubbles. When all the operations running in pipeline are waiting for the result of the ordered operations the pipeline operation stops, i.e it Stalls, what corresponds to a series of clock cycles in sequence filled only with Bubbles.
Bubbles and Stall are critical for a CPU performance, reason why the main purpose when conceiving a pipeline is to reduce their amount to a minimum.
If now we think that actually all the stages that we considered have huge latencies in each one of their operations – ALU operation, Memory access or Decoding operation – it’s easy to imagine that in a short period the pipeline will be completely filled with bubbles and that much likely the CPU will spend the most of its time stalling and not operating.
The available resources will be used in a very small percentage of their capacities. And this is the reason why the CPU manufacturers are nowadays heavily investing in the parallelization of the operations.
Let’s do another step into the reality. Off course the stages of a CPU operation cycle are not μops, but they are decomposable in many μops. Each stage of the pipeline is composed not by stages of the CPU cycle but by operations that will use available resources and execute in one clock cycle. So, their components are the μops.
To increase the amount of stages in a pipeline we need to launch many μops to fill those stages. To launch many μops we need to increase the number of instructions being executed simultaneously, therefore the execution of out of order instructions, what demands the reorganization of the μops after their execution.
In order to reduce the number of bubbles the instructions must be previously analyzed to predict the existence of deviations (jumps) in the program normal sequence. Actually, the execution of instructions by anticipation will be useless when an unpredicted jump happens, as all the job done by anticipation will have to be thrown out and a big stall will happen.
Summarizing, we will have to:
- Increase the number of μops executing simultaneously.
- Increase the number of stages of the pipeline.
- Reorder the executed out of order according to the normal sequence of the program instructions.
- Predict program deviations (jumps).
- Create storage temporary capacity (Buffers) for all the resources.
And a lot more will have to be done, but this is enough for us to understand the huge amount of logic that has to be introduced in the CPU chip to provide all this functions. And logic in hardware means transistors.
The Transistors size
So, the investment in parallelization implies a huge increase in the need for transistors inside the CPU Chip, for all the logic we have just seen will be necessary can be executed.
For some time that the steady increase in clock frequency of a CPU is no longer the main goal of the manufacturers research teams. The reduction in the size of transistors which in consequence became closer of each other raised the problem of noise transmission between the lines of the circuit, thus misrepresenting the information that circulates in them.
This way, the transistors size reduction in order to increase their number in the same area was in opposition with the clock frequency increase. It was necessary to choose one of the two:
- Proceed increasing the clock frequency in the CPU circuits.
- Proceed reducing the transistors size, so allowing to increase their number in the same area.
What’s it good for having a car that reaches 150 mil/h if we are running with it in traffic jams? If we do nothing about the traffic, we’ll only get faster to the bottleneck.
For the CPU the same goes. If nothing is done to avoid the bubbles, the most we increase the frequency of the signals carried on its circuits, the sooner we get to stall.
The production cost of a silicon wafer with integrated circuit is accounted by the wafer area and not by the number of transistors we place in it.
Nowadays, the largest investment of CPU manufacturers towards the maximum instruction parallelization, giving rise to the absolute need to increase the number of transistors to contain the necessary logic, clearly favors the second choice.
The purpose is to get to the execution of a macro instruction per clock cycle. It seems elemental but it is a monstrous job.
It’s time to go into our case study.