
MFT Metadata Files
The $AttrDef File
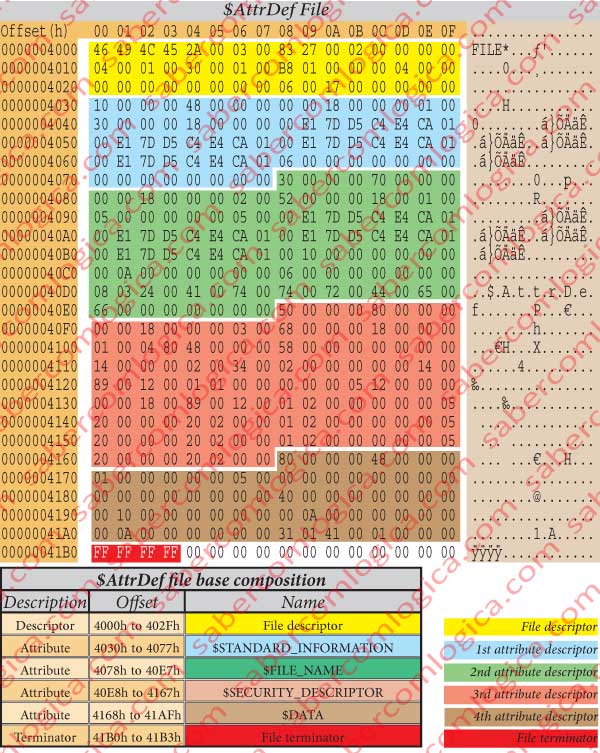
We’ve seen in the PBS analysis that the MFT starts at the offset 3000h. Being the $AttrDef file the 5th MFT entry, as we can see in figure 12-6, it will have 4 records with 1 KB each before it.
1 KB, or 1.024 bytes, represent an offset of 400h. Each entry having an offset of 400h and the $AttrDef file having 4 entries before, it shall start at the offset 3000h+4x400h=4000h.
Going to that offset we found there our file, whose hexadecimal editor representation is in figure 12-32.
The $AttrDef file occupies the 2 sectors 32 and 33, from offset 4000h to 43FFh and is composed by 2 parts:
- The general descriptor e
- The various attributes of its own.
The bytes from 4000h to 402Fh are the File Descriptor, already analyzed in its generic presentation. Its size is 30h or 48 bytes.
The bytes from 4030h to 4077h are the $STANDARD_INFORMATION attribute, already analyzed in its generic description. Its size is 48h or 72 bytes.
The bytes from 4078h to 40E7h are the $FILE_NAME attribute, already analyzed in its generic description. Its size is 70h or 112 bytes.
The bytes from 40ED8h to 41678h are the $SECURITY_DESCRIPTOR attribute, already analyzed in its generic description. Its size is 80h or 128 bytes.
The bytes from 4168h to 41AFh are the $DATA attribute, already analyzed in its generic description. Its size is 48h or 72 bytes.
The 4 Bytes from 41B0h to 41B3h – FF FF FF FF – are the $AttrDef file terminator.
In the table of figure 32, we summarize the $AttrDef file essential composition.
The $MFT File
The header or descriptor of this file, following its descriptive table in figure 7 and its hexadecimal editor representation in figure 34 tells us that:
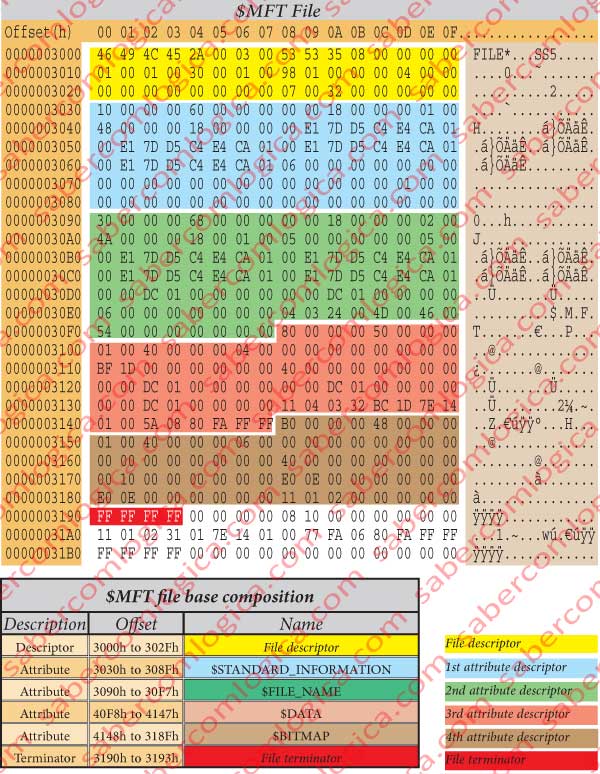
- Its signature is FILE.
- The Offset for the update sequence is 2Ah.
- The update sequence is 3 words length.
- The Log File sequence number is 08535335h.
- Its sequence number is 1.
- The Hard Link count is 1.
- The offset for the 1st attribute is 30h.
- The flags tell that the file is in use.
- The real do file size is 0198h=408 Bytes.
- allocated space for the file is 400h=1024 Bytes.
- This is the base file.
- The next attribute ID is 7.
- The update sequence number is 32 00.
- The update sequence array is 00 00 and 00 00.
- The 1st attribute starts at the offset 3030h.
The 1st attribute is a $STANDARD_INFORMATION, corresponding to the type 10h. According to the tables of figures 10 and 13, respectively for the header and for the attribute and the attribute body values in the frame of figure 34 with the hexadecimal editor representation of the $MFT file which contains it, we get the following information:
- Its length is 60h (96 bytes), the next attribute starting at the offset 3030h + 60h = 3090h.
- It’s resident,
- Its name length is 0.
- The offset for the name is 18h. Thus, no named.
- The attribute ID is 1.
- The attribute data length is 48h (72 bytes)
- The offset for the attribute data is 18h.
- The attribute data give us the date/time for the creation, modification and last reading of the file, for the last MFT modification and some more rules not interesting for our purpose.
The 2nd attribute is a $FILE_NAME, corresponding to the type 30h. Using the tables of figures 10 and 15, respectively for the header and for the attribute and the attribute body values in the frame of figure 34 with the hexadecimal editor representation of the $MFT file which contains it, we get the following information:
- Its length is 68h (104 bytes).
- The next attribute starts at the offset 3090h + 68h = 30F8h.
- It’s resident.
- Its ID is 2.
- References the parent directory, which is at the MFT entry 5, the “.” (dot) file.
- Besides the date/time elements as the previous attribute, it refers the name of the file it belongs to, which is the $MFT file, as we know.
The 3rd attribute is a $DATA, with the type 80h. Using the header descriptor of this non-resident and no named attribute, in figure 20 and the attribute body values in the frame of figure 34 with the hexadecimal editor representation of the $MFT file which contains it, we get the following information:
- Its length are 50h. Thus the next attribute starts at the offset 30F8h + 50h = 3148h.
- It’s non-resident.
- Its ID is 4.
- The initial VCN is 0.
- The final VCN is 1DBFh = 7,615.
- The attribute real size is 01DC0000h=31,195,136 Bytes
- The attribute allocated size is the same
- The initial data chain size is the same too. It was not yet modified.
- The offset for the data runs chain is 40h, meaning that they start at the offset 30F8h + 40h = 3138h, with the value of 11 04 03 32 BC 1D 7E 14 01 00…
To the data of this attribute corresponds the definition, size and localization of the MFT (Master File Table), which we will analyze in detail just now.
The 4th attribute is a $BITMAP, corresponding to the type B0h. This attribute description was done at its generic analysis. Here we highlight that it’s non-resident and that its data occupies 1 Cluster starting at the offset 2000h. This attribute data is the BitMap of the MFT entries, where each bit defines the used or free condition of each entry.
The Master File Table (MFT)
The Master File Table is the basis of the NTFS. Each File, each Index (which is a file for NTFS) has an entry in the MFT, where it is defined and kept if it’s small enough to fit in 1 KB otherwise its location in the disk being designated.
This is major difference in the NTFS. Once found the file entry in the MFT, it’s found the totality of the file in the almost all the cases. And the search in the MFT, as it’s done by a succession of indexations in tree, doesn’t become slower due to the Volume size. But it does as the level of subdivisions into Directories increases.
The data runs chain, starting at the offset 3138h, which give us the MFT location and size
11 04 03 32 BC 1D 7E 14 01 00 …
tell us that we are dealing with 2 data runs, meaning that the MFT is divided into 2 locations. So:
The 1st data run is:
11 04 03
- 1 Byte for the length – 04 Clusters or 16,384 Bytes starting at
- 1 Byte for the Offset – 03 Clusters, thus starting at the offset 3000h.
The 2nd data run is:
32 BC 1D 7E 14 01
- 2 Bytes for the length – 1DBCh = 7,612 Clusters or 31,178,752 Bytes starting at
- 3 Bytes for the offset – 01147E hh = 70,782 Clusters referring the 1st block offset, or 1147E000h+ +3000h = 11481000h.
And there’s no more data runs: The byte coming after the 5 bytes (3+2) coming next the byte 32 is 00, meaning that there’s no more data runs.
Therefore, the MFT is divided into 2 blocks in distinct zones of the Volume:
- The 1st block of data is exactly the location of the $MFT file, the one we are analyzing, starting at the offset 3000h. But it’s too the location where the MFT entries containing the metadata files begins, as we can see in the table of figure 6, where $MFT is the first, the entry 0. This block will have 16 entries, those allowed by its 4 clusters size, where the metadata files (those who start with $) will be, as we can see in the referred figure.
- The 2nd block of data starts at the offset 11481000h and is 7,612 Clusters long. This is the data block where the entries for our files and indexes will be. The referred entries start at the MFT entry 24, what we once again can see at the figure 6.
The sum of the 2 blocks bytes (31,195,136) as the one of their clusters (7,616) corresponds to what we’ve just read at the frame with the attribute header hexadecimal editor representation. The addressing in VCN (Virtual Cluster Number) for this file is made from VCN 0 to VCN 7615, as we could read at the referred frame.
This way we have identified and localized the MFT for this volume file system.
The space allocated for the MFT is designated when the partition where the Operating System resides is formatted. Aside that space another one intended for future MFT expansions is reserved, being this one usually generous, as the worst thing which can happen to a system performance is the MFT fragmentation, for which all the solutions are quite complex.
Just to realize the MFT size, one of the volumes in the PC where we are producing this document, has about 2 million files and folders, what implies one MFT larger than 2 GB in size. This will be the case of all those who use one only volume, the C: one, for all their files.
Let’s go on with our journey and soon we’ll understand why it’s so difficult to defragment the MFT.
The $LogFile File
This file is at the 3rd MFT entry, thus starting at the offset 3000h + 2 x 400h = 3800h. It’s used by the system to quickly and immediately register all the transactions in the HDD.
To these files and to their use we call Journaling. Its job is to ensure the file system consistency.
This file has nothing to do with our purpose, reason why we won’t do its detailed description. But, due to its importance we’ll try briefly describe why it exists and what it does.
The HDD has a SRAM cache for quick access, where the last files accessed and/or modified are kept. This way a better performance in the accesses to the HDD is achieved. The magnetic record of the written or modified data is managed by the disk controller trying not interfere in the accesses who provide the data to the CPU. But that cache, as an SRAM is ethereal, i.e. it has to be powered to work.
So, if a computer crashes with data in cache to be registered, the CPU having been informed about the success of the records it sents to the HDD, the system will be inconsistent, i.e. there are records which should be registered in the HDD which won’t be there, and this can have serious consequences.
So being, every written or modified data must be immediately magnetically recorded in the HDD together with the respective modifications in all the affected positions of the MFT which describe it.
And so it ends the performance improvement provided by the cache.
We must take attention to the huge amount of registrations we have to do in the HDD when a file is recorded or modified. It must record itself, the designation of its size, if it is changed, to rewrite the data runs, to change its description in the Index Buffers if it changed its location, change the BitMap, etc. The HDD heads will do a lot of journeys over the HDD to do the registration of simple file modification. If the CPU has to wait for the confirmation of all this job execution to proceed, the performance will go down.
And if the crash happens during all this registration into the MFT?
That’s another question. Now the problem is not the fact that the CPU is informed about the success of an operation which isn’t really executed. Now the problem is that some parts of the file description into the MFT were actualized and others weren’t. This means that the file system itself will be inconsistent.
How to solve this question?
Well, we must ensure that when CPU is informed about the success it will be completely executed in the HDD. If anything happens before the registration is fully completed we must have the possibility to detect it and reconstruct it. And this is how the Journaling arose. When a file is written or modified it is first written in a simplified manner, as one only record, into the HDD. For that purpose we use the $LogFile. That single and only record contains the file itself and the designation of all the registrations that have to be performed in order to ensure the file system consistency. After this record is written into the $LogFile the success is communicated to the CPU and it remains free for other operations.
Only then the Disk Controller will proceed with the registration such that the system performance is never disturbed. For that purpose it will use the records in the $LogFile, one by one, executing for each of them all the necessary steps into the HDD. Only after each record is fully registered and the system is consistent, it will be deleted from the $LogFile.
This way, if there’s a crash during the registration or even before all files in $LogFile are correctly registered, when the computer boots the OS will verify the existence of records into the $LogFile. Before it proceeds with the boot it will ensure that all those files are correctly registered into the HDD by the Disk Controller, so ensuring the file system consistency for all the files that were considered as registered to the CPU and repeating the registration of any file eventually stopped during the process.
Only after this process is executed the boot proceeds and the $LogFile record is deleted, sure that the file system is consistent.
The $Bitmap File
This file is at the 7th MFT entry, thus at the offset 3000h + 6 x 400h = 4800h.
As with the previous one this file isn’t important for our purpose, reason why we will not describe in detail. But with a brief description we’ll try to make clear what it is and what it does.
The $Bitmap file executes for the HDD the same job that the $BITMAP attribute does to the files of which it is an attribute. Its data is non-resident and is composed by a set of sequential bits (multiple of 8 – 1 byte) equal or higher than the total number of Clusters in the Volume. Each one of those bits represents the cluster whose LCN (Logical Cluster Name) is equal to the order of the bit in the sequence, starting from the lowest order bit.
This way, simply by reading a sequence of bits the system is able to know the free and used Clusters.
. (Dot) File
We are going to analyze this file with the same detail we used for the first ones as the path for our destination begins just here. This file represents the Root Directory, where the beginning of our path is described and its hexadecimal editor representation is shown in figure 35.
Let’s start by analyzing the file descriptor according with the table in figure 7, previously included.

- Its signature is FILE.
- The offset to the update sequence is 2Ah.
- The update sequence length is of 3 words.
- The update sequence number is 21 00.
- The update sequence array, i.e the value of the bytes replaced by the update number at the end of each file sector, is 00 00 and 00 00.
- The use/deletion count has the value 5. It represents the nr of times the file was updated. When the file is deleted this value is reset to 0.
- The hard link count has the value 1. It designates the number of directories referring this file.
- The offset to the 1st attribute is 30h.
- The real file size is 280h = 640 bytes
- The allocated file size is 400h = 1.024 Bytes.
- The next attribute ID is 17h or 23.
Now we are going to analyze each file attribute individually.
The 1st attribute is the $STANDARD INFORMATION, has the type 10h, its length is 48h, its ID is 1 and is resident. The attribute data length is 30h and the offset to them is 18h. Creation date/time is 25/04/10 at 22:15:38. File modification and last access date/time as well as MFT modification is 11/05/10 at 21:48:08.
The 2nd attribute is a $FILE_NAME , has the type 30h, its length is 60h, its ID is 2, its data length is 44h and the offset to them is 18h. The reference to the Parent file is the MFT entry 5, was created in 25/04/10 at 22:15:38, was modified last accessed and MFT modified in 11/05/10 at 21:48:08. Its name length is 1, its namespace is 3 (Win32 and DOS) and its name is “.” (dot).
The 3rd attribute is a $SECURITY_DESCRIPTOR, it has the type 50h, its resident, its length is 68h, its ID is 3, its data length is 50h and the offset to them is 18h. About its data we’re not going to do any reference.
The 4th attribute is an $INDEX_ROOT, it has the type 90h. This attribute was already analyzed in its generic description. What matters here is the value of a flag telling that the index is externally allocated. And that’s why we go to the next attribute.
The 5th attribute is the $INDEX_ALLOCATION, with the type A0h. This attribute too was already analyzed in its generic description. The $INDEX_ALLOCATION does always point to the external index corresponding to the MFT entry referring to it. In this case we are inside the . (dot) file and the pointed index is the Root Directory, which we’ve seen has 1 cluster length starting at the offset 30000h.
And is just to the Root Directory, at the offset 300h that we are going now, in order to start our search for the designated file.