
NTFS – Attributes (continuation 2)
Resident and Named Attribute
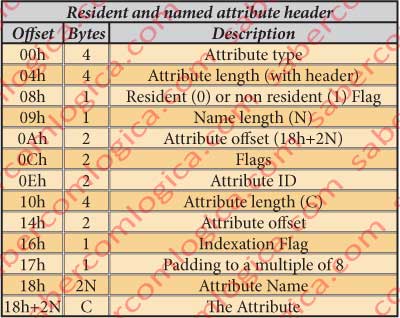
Resident and Named Attribute Header
The header structure from this attributes type is different from the ones we used till now, reason why we put here together the table for this attribute type header fields description, size and offset in figure 25.
$INDEX_ROOT Attribute
As we are going to base our analysis in the . (dot) metadata file of the volume that we are following, we’ll analyze the header inside the attribute, which refers to the specific values of that file. The name of this file is indeed a “.” (dot). The designation we put in brackets is for the sole purpose of not to mess it with the text dots.
$INDEX_ROOT is the root node for the binary tree which implements an Index and its layout is as follows:
- Standard Attribute Header
- Index Root
- Index Header
- Index Entry
In figure26 we present the hexadecimal editor representation for the . (dot) file $INDEX_ROOT attribute. We decomposed the attribute into its several layouts and each layout into its different fields, each shadowed in a different color. Each one must be read following the table referring each layout.
Standard Index Header

Reading it, using the table of figure 25 and the decomposition in figure 26, we can conclude that:
- The attribute type is 90h ($INDEX_ROOT).
- Its total length is 58h (88 bytes) .
- It’s resident.
- The name length is 4 characters.
- The name offset is 18h.
- The flags designate a normal file.
- Its ID is 14h.
- The attribute length is 38h (56 bytes), thus the header will have 32 bytes.
- The attribute offset is 18h+2xN=20h.
In this case the attribute offset is different from the name offset, as the attribute is named and its length in characters must be added to the beginning of the name, thus a number of bytes equal to the double of the characters (the question we’ve mentioned about the characters representation – Unicode, i.e. 2 bytes per character).
The name begins at the offset 4540h+18h = 4558h and will use 2*N= 2*4=8 bytes. So:
Bytes from 4558h to 455Fh refer the Name. In our case is $I30. The name $I30 refers a Directory.
In the 38h (56) next bytes is the attribute, which will be read according to the layouts we’ll designate.
Index Root
This is the first layout, which is read according with the table in figure 27. So, starting at 4549h + 20h = 4560h we’ll have:

The bytes from 4560h to 4563h – Attribute type. In our case 30h, corresponding to a $FILE_NAME, indicating that we are dealing with a directory.
The bytes from 4564h to 4567h – Collation Rule. Collation is the action of putting together some set of information ordered in a given rule. In our case the rule is 01 what means that the ordering rule will be the FileName.
The different Collation Rules in NTFS are:
- 00 – Binary
- 01 – Filename – Unicode chains.
- 02 – Unicode – Equal, but uppercase coming first.
- 10 – ULONG – 32 bits, little endian.
- 11 – SID – Security Identifier.
- 12 – Security mix – afterwards, it does it through SID.
- 13 – ULONGS – Sets of little endian 32 bits.
The bytes 4568h to 456Bh – Allocation Index entry size. In our case 1000h = 4.096 Bytes (1 Cluster)
The byte 456Ch – Clusters per index record. In our case 01.
The bytes 456Dh from 456Fh – Padding to a multiple of 8 Bytes
Index Header
This is the second layout which is read according to the table in figure 12-28. So,

The 4 bytes from 4570h to 4573h – Offset for the first index entry. In our case 10h.
The 4 bytes from 4574h to 4577h – Index entries total size. In our case 28h (40 bytes) including this layout.
The 4 bytes from 4578h to 457Bh – Index entries allocated size. In our case 28h (40 bytes) including this layout.
The byte 457Ch – Flags.
- 00 – Little Index – It fits inside the Index Root
- 01 – Great Index – External allocation is needed.
In our case is 01. External allocation is needed.
The bytes from 457Dh to 457Fh – Padding to a multiple of 8 Bytes
Index Entries
We are now going to read the Index Entries, which begin at the offset 4580h.
This field will only be valid if the last flag we’ve seen will not have a value set. In our case it has the value 01. When it has a value set it means that the Index has an external allocation and we must go to the next attribute and read it.
Just for the sake of curiosity and to see what it says, we are going to read the content of this attribute index entries. So:
The 8 bytes from 4580h to 4587h – File reference. In our case is 0 (It doesn’t exist).
The 2 bytes 4588h and 4589h – Index entry size. In our case is 18h, precisely all the space allocated for them.
So, let’s now read the next attribute, the one which will take us to the Root Directory index entries, the $INDEX_ALLOCATION attribute.
Non-Resident and Named Attribute
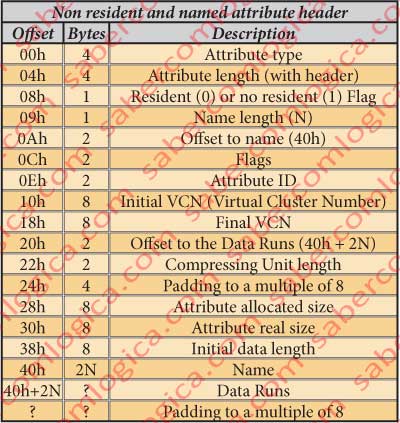
Non-Resident and Named Attribute Header
In figure 12-30 we have the table for this attribute type header.
Just like in the case of the previous attribute, as we are going to base the analysis in the “.” (dot) metadata file of the volume that we are following, we’ll do the analysis of this header inside the attribute itself which refers the specific values for that file.
$INDEX_ALLOCATION Attribute
Just like in the case of the previous attribute, as we are going to base the analysis in the . (dot) metadata file of the volume that we are following, we’ll do the analysis of this header inside the attribute itself which refers the specific values for that file.
$INDEX_ALLOCATION is the base component of all the indexation. It contains all the sub nodes of the binary tree. Its header tells us that:
- Its length are 50h = 80 Bytes,
- It’s non-resident,
- Its name has 4 characters,
- The offset for its beginning is of 40h. Therefore it starts at the offset 4598h + 40h = 45D8h,
- Its ID is 16,
- The offset for the data runs chain is 48h. Therefore it starts at the offset 4598h + 48h = 45E0h,
- The real, allocated and initial data chain sizes have the same value 1000h = 4.096 Bytes, 1 cluster.
- Its name is $I30, meaning it’s a directory.
- The data runs chain is 11 01 30 00 …, in short one only data run telling us that the external data occupies 1 Cluster and starts after the first 30h Clusters, or 48 x 512 x 8 = 196.608, or at the offset

In figure 29 we present the file . (dot) $INDEX_ALLOCATION attribute decomposition into the fields that compose it, in order to turn easier the table In figure 30 comprehension.
Going to that offset (30000h), we find there quietly waiting for us, our volume root directory.
But we won’t touch it yet. We’ve just finished here the attributes analysis. There are more attributes but they don’t matter for our purpose.
As we said before, OS Files are defined by the File Descriptor and by the Attributes. Since the analysis of this elements is now complete, we can analyze the metadata files.