
NTFS – Atributos (continuação 2)
Atributo Residente e com Nome
Cabeçalho de Atributo Residente e com Nome
A estrutura do cabeçalho deste atributo é diferente das analisadas até aqui, pelo que vamos juntar uma tabela tipo para o cabeçalho dos atributos residentes e com nome na figura25.
Atributo $INDEX_ROOT
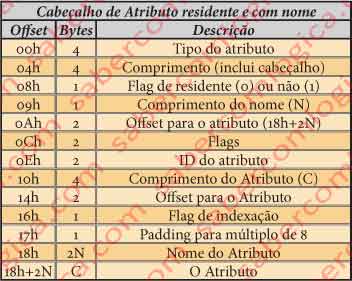
Como nos vamos apoiar no caso concreto do ficheiro de metadados . (ponto) do volume que temos em análise, vamos fazer a análise do cabeçalho dentro do próprio atributo, que refere os valores específicos desse ficheiro. Aproveitamos para referir que o nome deste ficheiro é mesmo um . (ponto). A designação que pomos entre parênteses é unicamente com o fim de não se fazer confusão com os pontos do texto.
$INDEX_ROOT é o nó raiz da árvore binária que implementa um índice e o seu layout é como segue:
- Standard Index Header
- Index Root
- Index Header
- Index Entries
Na figura 26 apresentamos a decomposição do atributo $INDEX_ROOT do ficheiro . (ponto) nos seus diversos componentes e layouts e campos que os compõem, para podermos acompanhar com a leitura da tabela.
Standard Index Header

Pela sua leitura retiramos que:
- O tipo do atributo é 90h ($INDEX_ROOT).
- O comprimento total é de 58h (88 bytes) .
- É residente.
- O comprimento do nome é de 4 carateres.
- O offset para o nome é 18h.
- As flags indicam ficheiro normal.
- Tem o ID =14h.
- O comprimento do atributo é de 38h (56 bytes), portanto o cabeçalho terá 32 bytes.
- O offset para o atributo é 18h+2xN=20h.
Neste caso o offset para o atributo é diferente do offset para o nome, pois o atributo tem nome e o seu comprimento em carateres deve ser adicionado ao início do nome com o número de bytes igual ao dobro dos carateres (a tal história dos pontos).
O nome, está a partir do offset 4540h+18h = 4558h e ocupará 2*N= 2*4=8 bytes. Assim, Os bytes de 4558h a 455Fh correspondem ao Nome. No nosso caso o nome é $I30. O nome $I30 refere um Diretório.
Nos 38h (56) bytes seguintes encontra-se o atributo, que se vai ler de acordo com os layout que vamos indicar.
Index Root
Este é o primeiro layout, que é lido de acordo com a tabela da figura 27. Assim teremos, a partir de 4549h + 20h = 4560h:

Os bytes de 4560h a 4563h – Tipo do atributo.
No nosso caso 30h, que corresponde a um $FILE_NAME, tipo indicativo de que se trata de um diretório.
Os bytes de 4564h a 4567h – Collation Rule.
Collation é a ação de juntar informação escrita de uma forma ordenada, de acordo com uma forma standard ou de acordo com uma regra (rule). No nosso caso a regra é 01 e corresponde à junção da informação ordenada por Filename.
As várias regras de junção ordenada de informação (Collation Rules) em NTFS são:
- 00 – Binárias
- 01 – Filename – Cadeias de Unicode.
- 02 – Unicode – Igual, mas maiúsculas vêm primeiro.
- 10 – ULONG – 32 bits, little endian.
- 11 – SID – Identificador de segurança.
- 12 – Mistura de Segurança – após, faz pelo SID.
- 13 – ULONGS – Conjuntos de 32 bits little endian.
Os bytes 4568h a 456Bh – Tamanho da entrada do índice de alocação. No nosso caso 1000h = 4.096 Bytes (1 Cluster).
O byte 456Ch – Clusters Por Registo de índice. No nosso caso 01.
Os bytes 456Dh a 456Fh – Padding a múltiplo de 8 Bytes.
Index Header
Este é o segundo layout, que é lido de acordo com a tabela da figura 28. Assim:

Os bytes 4570h a 4573h – Offset para a primeira entrada de índice . No nosso caso 10h.
Os bytes 4574h a 4577h – Tamanho total das entradas de índice. No nosso caso 28h (40 bytes) incluindo este layout.
Os bytes 4578h a 457Bh – Tamanho alocado para as entradas de índice. No nosso caso 28h (40 bytes) incluindo este layout.
O byte 457Ch – Flags.
- 00 – Pequeno índice – Cabe no Index Root.
- 01 – Grande índice – É necessário alocação externa.
No nosso caso é 01. Precisa alocação externa.
Os bytes 457Dh a 457Fh – Padding a múltiplo de 8 Bytes.
Index Entries
Passamos agora às entradas de índice, que têm início no offset 4580h.
O campo que se segue só é válido se a última flag não tiver valor estabelecido, mas no nosso caso tem e é 01. Quando tem significa que o índice é alocado externamente e devemos passar à leitura do atributo seguinte.
No entanto vamos ler só para vermos o que diz.
Os bytes 4580h a 4587h – Referência ao ficheiro. No nosso caso é 0 (não existe).
Os bytes 4588h e 4589h – Comprimento da entrada de índice. No nosso caso é 18h, precisamente todo o espaço alocado para as mesmas.
Passemos então à leitura do atributo seguinte, pois é ele que nos vai levar às entradas de índice do Diretório Raiz, o atributo $INDEX_ALLOCATION.
Atributo não residente e com nome
Cabeçalho de Atributo Não Residente e Com Nome
Na figura 30 juntamos uma tabela tipo para este cabeçalho.
Atributo $INDEX_ALLOCATION
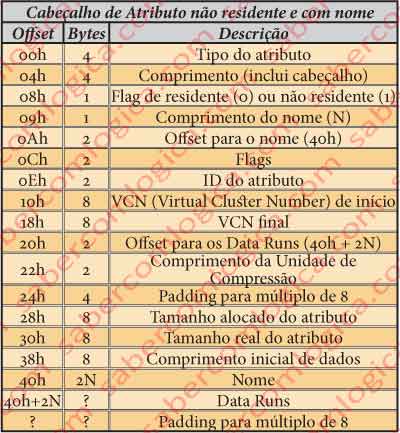
Tal como no caso do atributo anterior, como nos vamos apoiar no caso concreto do ficheiro de metadados . (ponto) do nosso volume, vamos fazer a análise do cabeçalho dentro do próprio atributo, que refere os valores específicos desse ficheiro.
$INDEX_ALLOCATION é a componente base de toda a indexação. É ele que contém todos os subnós da árvore binária. A interpretação do seu cabeçalho diz-nos que:
- Tem o comprimento de 50h = 80 Bytes,
- Não é residente,
- O seu nome tem 4 carateres,
- O offset para o seu início é de 40h, portanto inicia-se no offset 4598h + 40h = 45D8h,
- Tem ID = 16,
- O offset para os data runs é 48h, iniciando-se aqueles portanto no offset 4598h + 48h = 45E0h,
- Os tamanhos real, alocado e da corrente inicial de dados são de 1000h = 4.096 Bytes, 1 cluster.
- O seu nome é $I30, o que indica tratar-se de um diretório,
- Os data runs são 11 01 30 00 …, afinal um só, que nos diz que os dados no exterior ocupam 1 Cluster que se inicia após os primeiros 30h Clusters, ou seja 48 x 512 x 8 = 196.608, ou seja, no offset.

Na figura 29 apresentamos a decomposição do atributo $INDEX_ALLOCATION do ficheiro . (ponto) nos campos que os compõem, para podermos acompanhar com a leitura da tabela.
Viajando para esse offset (30000h), aí encontramos sossegadinho à nossa espera, o diretório raiz do nosso volume.
Mas não vamos ainda mexer-lhe, pois presentemente acabámos de analisar os atributos.
Há mais atributos, mas a sua análise não tem interesse para o nosso objetivo.
Como dissemos antes, os Ficheiros são definidos pelo Descritor de Ficheiro e por Atributos. Completa a análise destes elementos, estamos agora em condições de analisar e entender os ficheiros de metadados.