
Intel i7 Nehalem
A escolha da arquitetura Nehalem da Intel deve-se ao facto de ser aquela que está na base da criação da UCP Core i7, um bom exemplo do que se espera de uma UCP no presente e que permite vislumbrar o que se pode esperar para o futuro.
Muito haverá a dizer sobre uma UCP de última geração de enorme complexidade como esta. Sobre as alterações que veio introduzir à organização da placa mãe, sobre a solução que trouxe aos principais gargalos que limitavam a eficiência de uma UCP, sobre novos conceitos de ligação à memória com incorporação do controlador de acesso à mesma e sobre muitas mais questões que tentaremos ir referindo ao longo dos diversos Capítulos deste trabalho naquilo desta UCP que lhes disser respeito.
Agora, vamos concentrar-nos em questões relacionadas com a arquitetura interna do núcleo da UCP e a forma como evoluiu para conseguir produzir mais μops por cada ciclo de clock, portanto na paralelização da execução de instruções.
Não se pretende de forma alguma uma descrição exaustiva das funcionalidades e arquitetura desta UCP. Seria muito ambicioso da nossa parte e para o nosso atual nível de conhecimentos um detalhe com algum rigor de uma UCP de tal complexidade.
O que importa reter da descrição que vamos fazer é o que a arquitetura Nehalem trouxe de novo à evolução das UCP e o que se pode esperar das mesmas.
O fluxo de instruções
Vamos seguir a leitura deste parágrafo com o apoio da Figura 42
O conjunto de instruções adotado pela UCP Core i7 Nehalem que iremos abordar é o da arquitetura Intel64, composto por macro instruções CISC (Complex Instruction Set Computer ou Conjunto de Instruções Complexas).
A arquitetura interna desta UCP é composta por um conjunto de micro operações (μops) RISC (Reduced Instruction Set Computer ou Conjunto de Instruções Reduzido).
Vamos então resumir como se processa o fluxo de instruções e dados. A UCP:
- Busca uma série de macro instruções, digamos que um bloco de cache.
- Pré-descodifica estes blocos nas diferentes instruções que o compõem.
- Descodifica cada uma destas instruções em μops e coloca-as em buffers próprios para a Unidade Funcional que as vai tratar.
- Despacha-as para a UF disponível logo que os operandos de que necessitam estão disponíveis.
- Retira as μops completas e guarda o seu resultado
Todo este processo é executado em estágios de um pipeline, concretamente 14 estágios. Para que tenha sempre o pipeline preenchido o Core i7 Nehalem permite que as μops continuem a ser executadas Fora de Ordem. Para isso utiliza:
- o Escalamento Dinâmico de Instruções, cuja função é determinar quais as μops que podem prosseguir mantendo correta a semântica do programa e
- a Busca Especulativa de Instruções que carrega instruções do programa para além do resultado de saltos condicionais, dispondo para isso de uma Unidade de Previsão de Desvios que tenta antecipar com o máximo rigor o resultado dos desvios condicionais do programa.
Uma vez executadas, as μops são retiradas e colocadas com os seus resultados num buffer de reordenação e/ou fornecem os seus resultados para outras μops que estão à espera desses resultados como operandos para serem despachadas para uma UF (Unidade Funcional). Uma vez reordenadas as μops são retiradas do buffer de reordenação e os seus resultados guardados de acordo com a arquitetura do programa.
Todo este complexo Pipeline e Motor de Execução têm como principal objetivo a maior taxa de retirada de μops por ciclo de Clock.
Vamos agora ver com algum pormenor todos estes componentes bem como os buffers intermédios que foram criados com o objetivo de dispor sempre de muitas μops em todos os pontos de despacho. Para isso vamos continuar a acompanhar a Figura 42. As notas (nota x) que vamos designar ao longo da exposição referem-se a essa figura.
Pipeline de Busca e Descodificação ordenada
A Unidade de Busca de Instruções (nota 1) faz a busca na cache L1 e carrega sempre blocos de 16 Bytes de instruções alinhadas. Esta unidade faz a busca de instruções especulativa, i.e. antecipando o carregamento de instruções sem ter ainda definido o caminho do programa.
A execução fora de ordem e antecipada de instruções pode ser toda anulada se entretanto o programa tiver um desvio da sua sequência normal de execução (um salto por exemplo) não previsto. Neste caso todo o trabalho feito por antecipação vai para o lixo com enormes penalizações na performance do pipeline.
Para que da busca especulativa resultem instruções no caminho correto do programa esta unidade apoia-se na Unidade de Previsão de Desvios (nota 2), cuja função é antecipar com a máxima precisão possível desvios na execução do programa antes do resultado de uma instrução de salto condicional ou mesmo antes de desvios diretos provocados por saltos incondicionais ou chamadas serem conhecidos.
O bloco de 16 Bytes de instruções alinhadas obtido é enviado para um Pré-descodificador de Blocos de Instruções (nota 3) cuja função é identificar e separar as instruções individuais do bloco e colocá-las num Buffer de Fila de Instruções (nota 4), que dispõe de 18 entradas onde as instruções aguardam na sua ordem inicial de leitura para serem recebidas pela Unidade de Descodificação (nota 5), que contém 4 descodificadores e tem capacidade de enviar para o Buffer de Fila de μops (nota 6) até 4 μops em cada ciclo de clock.
Execução Fora de Ordem
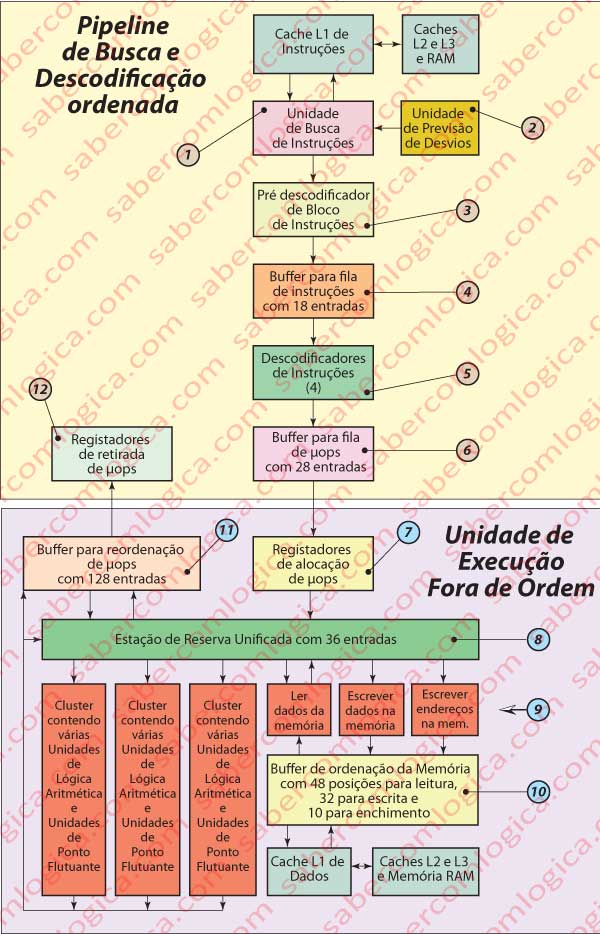
As μops estão agora em ordem de poderem ser executadas. Mas se estivermos à espera de ter todos os elementos necessários à execução de cada uma na sua sequência natural, tratando-se de um pipeline com 14 estágios, vamos certamente ter bolhas com fartura e entrar frequentemente em stall.
Para ultrapassar esta questão a arquitetura Nehalem prevê a execução de μops fora de ordem. Por antecipação, várias μops de fases mais avançadas do programa, sem dependência das μops de instruções anteriores na sequência normal são colocadas em execução, ficando os seus resultados em buffer a aguardar pelos pedidos das μops que vão deles necessitar.
Conseguem-se assim preencher vários estágios do pipeline com μops que se vão executar sem que tenham que esperar pelas que já estão em execução e preparando os dados que vão ser necessários à normal execução do programa numa fase mais adiantada.
Vamos então ver com mais pormenor a composição do motor de execução do Core i7.
As nossas μops ficaram no Buffer de Fila de μops (nota 6), de onde vão ser agora selecionadas para a Unidade de Execução pelos Registadores de Alocação (nota 7) que desempenham tarefas tais como:
- alocar recursos para cada μop (uma entrada nas Estações de Reserva, uma entrada nos Buffers de Acesso à Memória ou uma entrada no Buffer de Reordenação),
- ligar ao canal de despacho apropriado, cada μop,
- preparar a arquitetura interna da UCP para trabalhar os resultados intermédios renomeando os operandos de forma adaptada a registadores internos não visíveis ao código e
- providenciar os operandos que cada μop necessita, quando disponíveis.
De seguida as μops passam para a Estação de Reserva Unificada (nota 8), que pode conter até 36 μops aguardando pelos seus operandos para serem despachadas através de 6 canais para 6 diferentes Unidades de Execução (UE) (nota 9), conseguindo assim despachar 6 μops por ciclo de clock.
Três canais e suas correspondentes UE são destinados a leitura e escrita de dados e endereços na memória e os outros três são compostos por Unidades de Lógica e Aritmética (ULA) em quantidade variável.
Uma UE pode conter várias UF (Unidades Funcionais) (nota 9), concretamente várias ULA para operações com inteiros e/ou Ponto Flutuante. As UF, especialmente as destinadas a operações mais complexas, podem funcionar em pipeline, o que lhes permite, com a devida colocação em buffer de resultados intermédios, conter várias μops em simultâneo e produzir até um resultado por ciclo de clock.
As UF de acesso à memória fazem-no através do Buffer de Ordenação da Memória (nota 10) que, apoiada nos seus buffers de retenção, garante a consistência de escritas e leituras em memória.
Os resultados das μops processadas pela UE podem ser enviados de volta para a Estação de Reserva Unificada como operandos para μops que se encontram em espera ou para o Buffer de Reordenação (nota 11) cuja função, essencial para o sucesso da execução fora de ordem, consiste na retenção das μops e sua libertação exclusivamente na ordem sequencial da arquitetura das macro instruções do programa em execução, enviando-as assim tratadas para os Registadores de Retirada de μops (nota 12), estes já funcionando pela ordem do programa.
As novidades Nehalem
Esta descrição muito pouco exaustiva mas já com alguma profundidade teve por único fim mostrar como o Core i7 com a arquitetura Nehalem representa uma evolução no sentido da paralelização de execução de instruções, neste caso analisada dentro de cada núcleo.
O grande investimento em lógica verifica-se essencialment:
- na Unidade de Previsão de Desvios,
- na maior profundidade de buffers de retenção de μops em curso nas diversas fases de busca e execução fora de ordem,
- na criação de um elevado número de Unidades Funcionais para execução de μops em simultâneo,
- bem como de buffers com lógica que garanta a consistência de todas as μops a serem executadas fora de ordem.
Tudo isto complementado com:
- um acesso direto à Memória Principal por incorporação do Controlador de Memória no chip da UCP e
- um enorme aumento da capacidade da Memória Cache, agora com três níveis em que os dois primeiros são exclusivos de cada núcleo e o terceiro nível é global para os 4 núcleos. Mas este tema da cache vamos deixar para o local próprio, nomeadamente para o Capítulo sobre a Memória Cache.
Quem pretenda informação mais completa sobre estas e outras funcionalidades do Intel Core i7 poderá ler o trabalho que serviu de base para esta pequena síntese, da autoria do Prof . Michael E. Thomadakis da Universidade do Texas:
“The architecture of the Nehalem processor and Nehalem-EP smp platforms” no link http://scholar.google.com/citations?view_op=view_citation&hl=en&user=p7WnungAAAAJ&citation_for_view=p7WnungAAAAJ:d1gkVwhDpl0C
Porquê mais Transístores
Parece que a resposta a esta questão já está em grande parte dada. Vejamos:
- Previsão de desvios de programação.
- Execução antecipada e fora de ordem das μops.
- Garantia de consistência de dados nos acessos desordenados e em paralelo à memória
- Divisão de operações em muitas operações.
- Execução em simultâneo de 6 μops em 6 UE com várias UF diferentes, algumas em pipeline.
- Garantia de reordenação de todo este conjunto de instruções em execução aparentemente desorganizada, produzindo-se um resultado final de instruções executadas na sequência normal do programa.
E outras mais que não é necessário enumerarmos para imaginarmos a enormidade de lógica que suporta tudo isto. Quando dizemos lógica referimo-nos a programação complexa e de elevado nível embebida nos circuitos da UCP. Esta lógica é constituída por circuitos lógicos, que são constituídos por portas lógicas compostas por transístores.
Cá estamos finalmente. Mais transístores dão mais lógica.
Para podermos fazer com que a UCP acelere até à sua máxima frequência, temos que lhe desimpedir as vias.
A forma de a arquitetura Nehalem o tentar fazer é executando as μops em pipeline, 14 estágios de pipeline, criando em seu torno toda a lógica possível com o fim de reduzir as suas bolhas e as suas possibilidades de entrar em stall.
Mas este caminho pela paralelização e pela análise antecipada do que se vai fazer ainda está muito jovem, embora já se perceba que é o caminho a seguir. A arquitetura Nehalem não conseguiu resolver tudo. Ao desbloquear certos gargalos (Bottleneck) outros gargalos surgiram.
A investigação na procura da solução perfeita prossegue, agora procurando o desbloqueio dos novos gargalos, mas todos os passos que se derem no sentido da melhor rentabilização dos recursos de que já dispomos, fazem-se à custa de muitos transístores, muitas dezenas de milhões de transístores. Não esquecendo que estamos a descrever um de 4 ou 6 núcleos de uma UCP.
Conclusão
Por muito que os engenheiros consigam fazer evoluir os algoritmos de paralelização, se não forem os programadores a contribuir com a sua técnica e conhecimentos aplicada da melhor forma para que os seus programas se insiram nos devidos pressupostos, toda essa rentabilização vai falhar.
Por outro lado, na continuação do que vimos dizendo, é também na paralelização de partes dos programas, aquilo a que se chama tarefas ou threads, que está atualmente o maior investimento dos fabricantes de UCP, ao criarem as UCP com múltiplos núcleos e toda a lógica necessária à garantia de consistência das operações desenvolvidas em threads do mesmo programa, que correm em paralelo nos diversos núcleos. Para entendermos como é que o programador pode usar desses artifícios nos seus programas, vamos ter que passar antes pelos Sistemas Operativos. Estes não fazem a gestão da execução por tarefas mas fornecem as ferramentas necessárias para que os programadores façam a sua gestão.
A ligação entre a UCP e a Memória é absoluta. A performance da UCP está ligada à performance do sistema de memória. Por essa mesma razão vamos fazer uma análise de todo o sistema de memória que está por detrás de uma UCP eficiente. A MP (Memória Principal) é o local onde todos os programas em execução têm que ser colocados. Como vimos é na MP, através do endereço dos dados ou instruções que a UCP vai buscar instruções e dados. Mas, tal como os programas a executar são lidos do HDD (disco rígido) para a MP, também as porções desses programas ou blocos de dados que a UCP precise são colocados na Cache, a única memória que a UCP conhece. O conhecimento da forma de funcionar do conjunto dos componentes do sistema de memória e de cada um individualmente é importante para quem queira conhecer o computador e poder fazer uso eficiente dele. Por isso vamos nos próximos Capítulos abordar as várias formas de memória.
Mais adiante iremos abordar os Sistemas Operativos, os atuais verdadeiros comandantes dos computadores, aqueles que estabelecem a relação entre as nossas abstrações e a realidade física de um computador atual. Aí, como veremos, vamos acrescentar mais um conceito de memória que nos vai fazer abstrair da memória real em favor de uma outra criada e gerida pelo Sistema Operativo, a Memória Virtual. Mas lá chegaremos. Primeiro, vamos saber como funciona a real.
A UCP também não seria nada sem os periféricos com que comunica, principalmente aqueles chamados de interface humana como o teclado, o rato, o joystick e o monitor, através dos quais a UCP nos pede os dados com que executa os programas. Não esquecendo todos os outros que atualmente podem ser ligados a um computador de que mencionámos alguns nas primeiras páginas deste trabalho e entre os quais se encontram a Memória Principal e o HDD.
Mas então como é que a UCP comunica com todos estes periféricos e como funciona fisicamente essa comunicação?
É outra pergunta normal neste momento, já que queremos saber como funciona tudo isto na sua base mais elementar e menos complexa, para depois podermos passar à enorme complexidade do que hoje dispomos. A UCP limita-se a dizer o que quer e de quem quer. A gestão de todo este funcionamento pode ser externa à UCP, mas sempre sob o seu comando.
Toda a comunicação da UCP com o mundo que a rodeia e que faz a realidade do computador passa pela Placa Mãe (Motherboard), um circuito impresso onde vão ligar todos os periféricos e onde está presente todo um conjunto de Chips que faz a gestão de todos os periféricos que servem o computador e dele se servem. Todos os componentes do computador ligam e são geridos pela UCP, através da Placa Mãe e dos seus componentes. Entendemos portanto que, antes de abordarmos a memória com mais alguma profundidade, devemos fazer uma breve descrição do que é uma Placa Mãe e de como se compõe.
A simulação de UCP que analisámos até agora serviu só para se entender a lógica de funcionamento de uma UCP. Não tivemos em conta a frequência do clock, que seria muito baixa. Pela mesma razão, a Memória que considerámos era parte integrante do chip da UCP e estava em conexão direta com os circuitos do seu núcleo. Dessa forma, todos os valores procurados pela UCP na memória foram encontrados e utilizados da mesma forma que se executavam as operações internas da UCP.
Claro que tudo isto só acontece no mundo da fantasia e por isso, a partir daqui vamos esquecer a UCP que serviu para a nossa análise e vamos pensar numa UCP real e numa Memória real com todo o seu sistema.
Vamos também fazer as análises sempre pela unidade básica de computação, que é o Byte. Em qualquer UCP comercial é possível o endereço ao Byte ou à Palavra, qualquer que seja a sua dimensão.
Gostaríamos de referir o livro do Prof. Carlos Delgado do Instituto Superior Técnico – “Arquitetura de Computadores” assim como os artigos que o Engº Benito Piropo escreveu nas colunas do ForumPCs sobre “O Computador” em http://www.bpiropo.com.br/es_fpc1.htm que nos serviram de base para muito do que se fez neste Capítulo.