
NTFS – Atributos de Ficheiros
Para podermos fazer esta análise vamos apoiar-nos nas imagens hexadecimais de vários Ficheiros de Metadados do Volume que estamos a analisar, imagens essas que iremos referenciando ao longo da exposição, apresentando sempre no local o detalhe da parte desses ficheiros em análise.
Esses Ficheiros de Metadados serão descritos de seguida, como se encontram, como se interpretam e como nos podem ajudar no nosso objetivo.
Mas antes vamos ter que definir os atributos de ficheiros, os seus formatos e a forma como se leem. Porque os ficheiros de metadados, para além de terem um descritor de ficheiro (que também são) que se analisa de acordo com o que descrevemos, também têm atributos próprios, que os definem como ficheiros.
Portanto, para os analisar, primeiramente precisamos de saber como e por isso vamos começar pelos atributos.
Os Atributos de Ficheiros são, como o nome diz, os atributos que caracterizam cada ficheiro. É através deles que se encontra o seu caminho, que se define a sua segurança, que se garante a sua consistência, enfim, que o NTFS define tudo o que a um ficheiro interessa, no que lhe diz respeito.
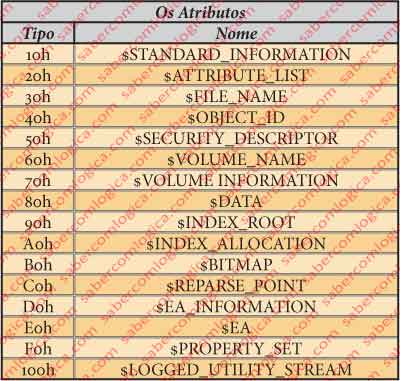
Realmente, a organização deste trabalho neste Capítulo é verdadeiramente complexa. Vamos ter que partir de uma lista dos Atributos que vamos já colocar na tabela da figura 9. Para já vamos ter que acreditar que são esses.
Como é que se lá chega?
Pois, precisamente pela análise de um dos tais ficheiros de metadados e por um dos seus atributos. Para já é assim. Quando analisarmos esse ficheiro $AttrDef, o que define os atributos, ficaremos a perceber tudo. Para ajudar a compreensão das nomeações que vou fazer, junto de seguida uma tabela dos tipos e nomes dos diferentes atributos.
Os atributos dividem-se por 4 diferentes classificações, conforme são ou não residentes e têm ou não nome.
Por residente ou não, entenda-se o facto de os dados do Atributo estarem incluídos na sua descrição na MFT, ou em outro local externo à MFT devidamente indexado.
Por ter ou não nome, entenda-se não o nome de atributo, que todos têm com o acabámos de indicar na sua lista, mas um nome próprio que lhe seja atribuído, como o nome de um qualquer ficheiro normal.
Os atributos também são ficheiros e como tal, também têm um cabeçalho ou descritor e um corpo.
Os cabeçalhos dos atributos diferem consoante esta classificação que agora definimos, pelo que vamos fazer a sua descrição dividida por estas categorias, começando sempre pelo cabeçalho tipo em cada uma delas.
Vamos continuar a usar a mesma imagem hexadecimal do ficheiro $AttrDef , na figura 32 para continuação do nosso trabalho.
De acordo com o que lemos no descritor do ficheiro, o primeiro atributo começa no offset 4030h. É um atributo do tipo $STANDARD_INFORMATION (acreditem que é). que é um atributo residente e sem nome, como vamos ver, e que se encontra representado sobre fundo azul na figura referida.
Atributos Residentes e sem nome
Cabeçalho Tipo de Atributos Residentes e Sem Nome
Juntamos a tabela dos diferentes campos deste cabeçalho na figura 10, sua dimensão em bytes e o seu offset, que devemos seguir na identificação e comparação com os mesmos campos na imagem hexadecimal do ficheiro em análise, que se apresenta na figura 11.

Os 4 bytes de 4030h a 4033h representam o tipo de Atributo. No nosso caso 10h, o que identifica o atributo $STANDARD_INFORMATION, conforme se pode ver na tabela dos atributos.
Os 4 bytes de 4034h a 4037h indicam o comprimento deste atributo. No nosso caso 48h, o que significa que o próximo atributo se inicia no offset 4030h + 48h = 4078h.
O byte em 4038h é a Flag que determina se o atributo é ou não residente, isto é, se os seus dados estão ou não incluídos neste ficheiro, que assume o valor 1 quando é não residente ou o valor 0 quando é residente. No nosso caso é 0, logo residente.
O byte em 4039h indica o comprimento do nome. No nosso caso 00, pois não tem nome.
Os 2 bytes de 403Ah a 403Bh indicam o offset do nome. No nosso caso 18h, o que significa que a descrição do nome deveria começar no offset 4048h, se o tivesse.

Os 2 bytes de 403Ch a 403Dh também são Flags agora com o significado:
- 0001h – Comprimido.
- 4000h – Encriptado.
- 8000h – Esparso.
Só os dados do atributo podem ser comprimidos ou esparsos e só quando não são residentes.
Os 2 bytes em 403Eh e 403Fh indicam o ID do Atributo. Este valor é exclusivo para cada atributo. No nosso caso ID = 1.
Os 4 bytes de 4040h a 4043h representam o comprimento dos dados do Atributo. No nosso caso é 30h, ou seja, 48 Bytes.
Os 2 bytes em 4044h e 4045h representam o offset dos dados do atributo. No nosso caso 18h em relação ao início do atributo, o que significa que os dados deste atributo se iniciam em 4030h + 18h = 4048h e que o atributo seguinte se inicia em 4048h + 30h = 4078h, como já tínhamos verificado atrás.
O byte em 4046h é a Flag indexada. No nosso caso 00.
O byte em 4047h é o Padding de acerto das designações a um múltiplo de 8 bytes mais próximo. No nosso caso é 1 Byte, precisamente aquele em que se encontra. Um caso em que o padding serve para acertar a meio de linha da tabela hexadecimal e o seu valor é sempre 00h.
Terminamos aqui a descrição do cabeçalho tipo de um Atributo, residente e sem nome.
Atributo $STANDARD_INFORMATION
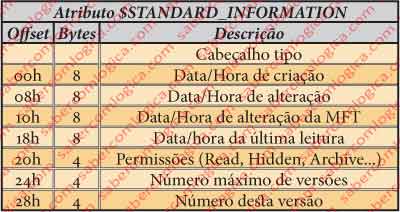
Juntamos a tabela dos diferentes campos deste atributo na figura 13, sua dimensão em bytes e o seu offset, que devemos seguir na identificação e comparação com os mesmos campos na imagem hexadecimal do ficheiro em análise, que se apresenta na figura 12. A parte com fundo em castanho representa o cabeçalho, que acabámos de analisar. Os 48 Bytes do seu tamanho, de que fomos informados pela leitura do cabeçalho vêm a seguir, decompostos em várias cores pelos diversos campos. O corpo deste atributo começa no offset 4048h, o que resulta da soma do comprimento do cabeçalho ao offset inicial do atributo 4030h + 18h = 4048h.
Os 8 Bytes de 4048h a 404Fh – Data/hora da criação do ficheiro. No nosso caso é 00 E1 7D D5 C4 E4 CA 01h, o que significa 25-04-2010 às 22:15:38 (esqueçam e não tentem fazer isto em casa sozinhos, porque foi o editor hexadecimal que nos deu esta informação).

Os 8 Bytes de 4050h a 4057h – Data/hora da alteração do ficheiro. No nosso caso 25-04-2010 às 22:15:38.
Os 8 Bytes de 4058h a 405Fh – Data/hora de alteração da MFT. No nosso caso 25-04-2010 às 22:15:38.
Os 8 Bytes de 4060h a 4067h – Data/hora da leitura do ficheiro. No nosso caso 25-04-2010 às 22:15:38.
Os 4 Bytes de 4068h a 406Bh – Permissões do ficheiro. No nosso caso é a flag 6. Não se aplica a este tipo de ficheiro, criado e usado pelo sistema.
Os 4 Bytes de 406Ch a 406Fh – Máximo nº de versões permitidas para o ficheiro. No nosso caso é 0, o que significa que a numeração de versões está desativada.
Os 8 Bytes de 4070h a 4077h – Número da Versão. Este valor é zero se o anterior o for, o que é o nosso caso.
Concluída a análise deste atributo, vamos iniciar a do atributo seguinte, $FILE_NAME.
Atributo $FILE_NAME
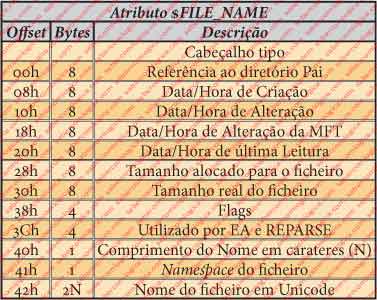
Juntamos a tabela dos diferentes campos deste atributo na figura 15, sua dimensão em bytes e o seu offset, que devemos seguir na identificação e comparação com os mesmos campos na imagem hexadecimal do ficheiro em análise, que se apresenta na figura 14. Este atributo, como foi definido no cabeçalho do atributo anterior, começa no offset 4078h. Na figura 32 do ficheiro $AttrDef, este atributo está sobre fundo verde. Também é um atributo residente e sem nome, pelo que o cabeçalho tem o mesmo tipo do anterior. Para analisar o cabeçalho do atributo vamos utilizar a sua tabela tipo na figura 10 atrás e os campos sobre fundo castanho do pormenor do atributo, na figura 14.
- É do tipo 30h, ou seja, é um atributo $FILE_NAME.
- O seu comprimento é de 70h (118 bytes), começando o próximo atributo no offset 4078h+70h=40E8h.
- É um atributo residente.
- O ID do Atributo é 2.
- O comprimento dos dados é de 52h (80 bytes).
- O Offset dos dados é 18h.
- A flag indexada é 1.

Vamos passar agora à leitura do corpo do atributo propriamente dito, a partir do offset 4090h (4078h + 18h = 4090h). O pormenor da edição hexadecimal deste atributo está na figura 12-14 onde o cabeçalho, tal como no caso anterior, está sobre fundo castanho.
Os 8 bytes de 4090h a 4097h referem a entrada na MFT do diretório Pai.
Os 8 bytes de 4098h a 409Fh indicam a data/hora da criação do ficheiro. No nosso caso 25-04-2010 às 22:15:38.
Os 8 bytes de 40A0h a 40A7h indicam a data/hora da alteração do ficheiro. No nosso caso é igual ao anterior.
Os 8 bytes de 40A8h a 40AFh indicam a data/hora de alteração da MFT. No nosso caso é igual ao anterior.
Os 8 bytes de 40B0h a 40B7h indicam a data/hora da leitura do ficheiro. No nosso caso é igual ao anterior.
Os 8 bytes de 40B8h a 40BFh determinam o espaço alocado ao ficheiro. No nosso caso é 1000h, ou 4096 Bytes, ou 8 setores, ou 1 cluster.
Os 8 bytes de 40C0h a 40C7h indicam o tamanho real do ficheiro. No nosso caso 0A00h, ou 2561 Bytes.
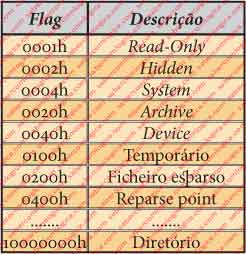
Os 4 bytes de 40C8h a 40CBh descrevem as flags. No nosso caso 0006h. Não estamos a descrever nenhum tipo de ficheiro mas sim o próprio ficheiro de metadados que é hidden e de system.
Estas flags identificam o tipo do ficheiro e algumas das suas propriedades conforme a tabela da figura 16 que descreve algumas flags e as correspondentes propriedades dos ficheiros. Certamente já viram algumas na caixa de propriedades dos ficheiros.
Os 4 bytes de 40CCh a 40CFh – Espaço usado por EA e Reparse. Se o ficheiro tiver Extended Attributes (EA), então o campo EA terá o tamanho do buffer necessário. Se o ficheiro for um Reparse Point então o campo Reparse dará o seu tipo.
O byte em 40D0h –Tamanho do nome em carateres (N). No nosso caso serão 8 carateres ($AttrDef).
O byte em 40D1h indica o Namespace em que o nome do ficheiro é indicado. No nosso caso é o namespace 3, que corresponde ao namespace DOS.
Os 2xN bytes seguintes, no nosso caso 2×8=16 carateres ou 16 bytes de 40D2h a 40E1h, representam o nome do ficheiro em Unicode ($.A.t.t.r.D.e.f.). Em Unicode cada carater ocupa 2 Bytes. Veja-se a figura 17, apresentada em generalidades quando definimos Namespaces.
Os 6 bytes de 40D2h a 40D7h – Padding a 8 Bytes.
Atributo $SECURITY_DESCRIPTOR
O atributo que se segue no ficheiro $AttrDef é o $Security_Descriptor que, como foi definido no cabeçalho do atributo anterior, começa no offset 40E8h. Na figura 32 do ficheiro $AttrDef este atributo está sobre fundo vermelho. Aqui vamos incluí-lo em pormenor na figura 19. Também é um atributo residente e sem nome, pelo que o cabeçalho tem o mesmo tipo do anterior.

- O atributo é do tipo 50h, o que corresponde a um Atributo $SECURITY_DESCRIPTOR.
- O comprimento do atributo, incluindo cabeçalho, é de 80h (128 bytes), começando o próximo atributo em 40E8h + 80h = 4168h.
- O atributo é residente.
- O ID do atributo é 3.
- O comprimento dos dados é 68h (104 bytes).
- O offset para o atributo em si é 18h, começando portanto no offset 40E8h +18h = 4100h.
- Chegamos assim ao offset 4100h, onde começa a leitura do atributo.
Uma análise em pormenor deste atributo não é útil ao nosso objetivo – Mostrar a lógica seguida pelo NTFS na procura de um ficheiro – e seria extremamente penalizante, pois a sua análise é bastante complexa e longa. Não pretendemos adensar exageradamente a informação fornecida. Será este o princípio que vamos seguir, já enunciado no início. Isso não nos impede no entanto de descrever as principais características e funcionalidades dos mesmos.
Sucintamente, os dados deste atributo dispõem de um cabeçalho com flags que indexam os vários blocos de informação em que se divide, como flags e Access Control Lists. São estes que definem os valores das permissões individuais e de grupo, heranças, propagações e outros que definem aquilo que podemos ver de uma forma gráfica interessante nas várias janelas de definição de segurança dos ficheiros (propriedades/segurança) onde estão definidos os utilizadores, os grupos e as suas permissões.
O que este atributo regula são as condições de segurança do acesso a ficheiros e/ou diretórios pela parte de todos os possíveis utilizadores do sistema, tanto individualmente como no grupo em que estão inseridos. Cada individuo e/ou cada grupo podem ter permissões diferentes e essas permissões dizem não só respeito ao acesso a cada ficheiro individualmente, como também às várias formas de intervenção nesse ficheiro. Para isso este atributo tem que criar vários blocos onde define o tipo de permissões, terá que criar indexações a tabelas de utilizadores e grupos e interligar tudo isto a nível de cada ficheiro. E ainda faz a gestão da propagação ou herança entre nós Pai e nós Filhos (Diretório → Ficheiro e Diretório → Diretório Pai).
Passemos então ao atributo seguinte que, como já vimos, começa no offset 4168h. É o atributo $DATA. Mas este já é um atributo não residente e sem nome, pelo que vamos passar a sua descrição para o artigo seguinte.