
NTFS – Generalidades e Entrada
Antes de começarmos a entrar nos pormenores do sistema de ficheiros, vamos ter que dar umas dicas sobre a forma como vamos organizar esta análise.
O NTFS é de descrição muito complexa e que facilmente se pode tornar confusa, pois é frequente que o entendimento de algumas etapas exija o entendimento da etapa que a explica. É precisamente esse o risco que queremos evitar. Para que se consiga entender cada um dos passos por que vamos evoluir, vamos definir primeiramente o objetivo que nos propomos concretizar como forma de dar a entender como funciona o NTFS.
Objetivo do trabalho:
Encontrar no HDD, através de um editor hexadecimal, o ficheiro cujo caminho é:
G:\Todas as Imagens\Diversos Pessoais\Diversos 1\Diversos 1999\Picture4.jpg
Todas as ações do NTFS que não tenham ligação direta com este objetivo não serão analisadas. Para algumas poderemos fazer uma descrição genérica desse tipo de ação, mas não entrando em pormenor. A descrição já vai ser longa. Se assim não fizéssemos, todo o livro não chegaria.
Porque não é possível estabelecer uma sequência lógica vamos ter que frequentemente fazer referência a figuras que estão em artigos já passados ou outros ainda por vir. Por essa razão, neste Capítulo, as figuras vão ter uma numeração sequencial relativa ao Capítulo e não aos artigos.
Agora vamos deixar de uma forma resumida o método que usámos e que portanto deve ser usado por quem leia este trabalho.
O ficheiro é o centro de atenções de um sistema de ficheiros. No NTFS, um ficheiro é definido por um cabeçalho ou descritor e por um conjunto de atributos.
Por esta razão, antes de fazermos a análise de qualquer ficheiro, vamos verificar como se lê um descritor de ficheiro e como se lêem e quais são os atributos importantes para a leitura dos ficheiros de que precisamos.
Conhecidos estes, estamos em condições de ler a definição de ficheiros.
Há dois tipos de ficheiros em NTFS. Os nossos ficheiros, aqueles para quem o sistema de ficheiros foi criado e os ficheiros de metadados, que contêm toda a informação necessária para conseguirmos chegar aos primeiros. Vamos por isso começar a análise pelos ficheiros de metadados que nos vão permitir chegar ao ponto de partida e ensinar como progredir. Só então iremos percorrer o caminho desde o ponto de partida até ao objetivo.
Toda a informação sobre os nossos ficheiros está concentrada numa tabela mestre, a MFT (Master File Table), cujo modo de organização nos vai ser indicado por um ficheiro de metadados.
Para chegarmos aos ficheiros vamos ter que seguir uma rede de índices em árvore, definida por ficheiros tipo Index, com os quais também serão ficheiros de metadados que nos ensinarão a trabalhar.
No percurso, vão muitas vezes ter necessidade de voltar atrás para, através de uma tabela de leitura já vista, conseguir perceber a interpretação do conteúdo de um ficheiro.
Vamos então prosseguir. Relembramos que acabámos um processo de Boot que foi agora entregue ao SO residente. Portanto, tudo o que se vai passar a partir de agora já tem relação com esse SO e o seu Sistema de Ficheiros, o NTFS.
PBS (Partition Boot Sector)
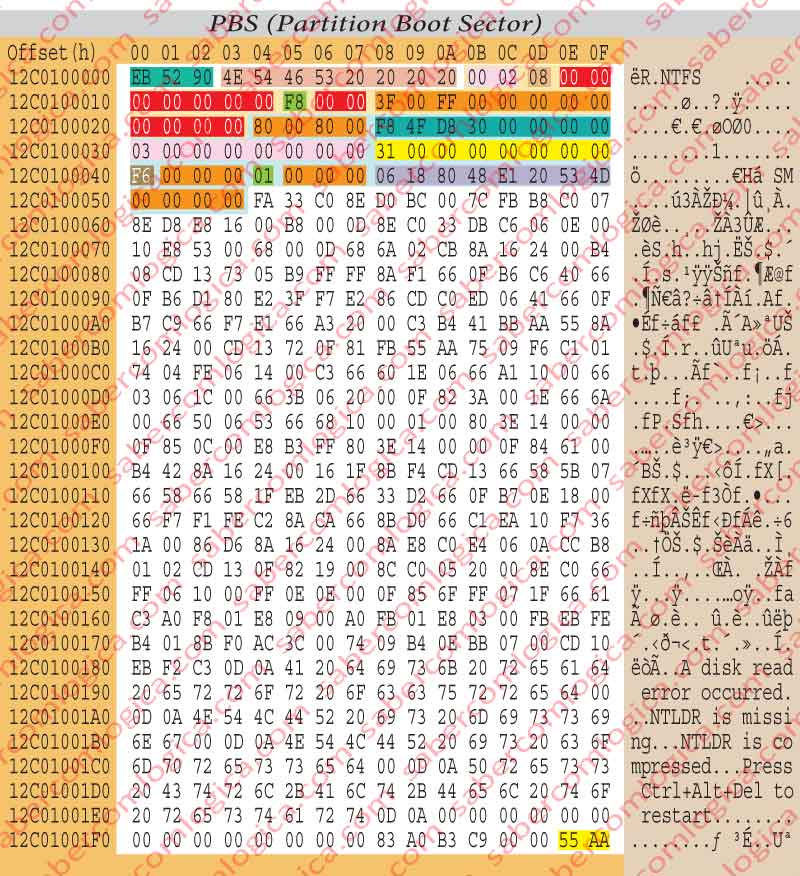
Depois de curta navegação, cá estamos no offset 12C0100000h. Tal como era esperado, aí encontramos o setor de boot da partição 2, que vamos representar com um editor hexadecimal, na figura 4.
A partir daqui, a partição passa a ser tratada como um disco (volume) e o setor de boot desse volume está no primeiro setor, portanto no offset 0000h. Todas as referências de offset são relativas ao zero da partição.
Os 3 bytes desde o offset 0000hm ao 0002h são uma instrução de salto.
Os 8 bytes desde o offset 0003h ao 0009h correspondem ao OEM ID (Original Equipment Manufacturer IDentification), que identificam o nome e a versão do SO que formatou o volume.
Os 25 bytes desde o offset 000Bh ao 0023h (sombreado inferior) correspondem ao BPB (Bios Parameter Block), que vamos descrever em pormenor já de seguida.
Os 48 bytes desde o offset 0024h ao 0053h (sombreado inferior) correspondem à extensão do BPB (Bios Parameter Block).
Os 426 Bytes desde o offset 0054h a 01FD correspondem ao código de boot que, nas partições bootable vai carregar o SO em memória e entregar-lhe o controlo das operações.
Os 2 últimos bytes são a assinatura do setor de boot.
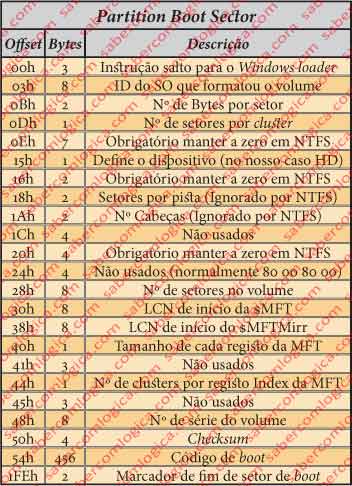
BPB (Bios Parameter Block)
Na Figura 4a destacamos o BPB do PBS com vista a uma melhor análise.
Os 2 bytes 000Bh e 000Ch identificam o número de bytes por setor. No nosso caso serão 02 00 = 512 B, que aliás corresponde ao valor standard.
O byte em 000Dh indica o número de setores por cluster. No nosso caso são 8. Portanto cada cluster tem 4 Kb, que é também o valor habitualmente atribuído pelo NTFS.
Os bytes desde 000Eh a 0014h, de 0016h a 0017h e de 0020h a 0023 h, devem ser sempre mantidos a zero, pois os campos que definem, não estando a zero, provocam a falha de montagem do volume pelo NTFS.
O byte 0015h define o tipo de dispositivo onde esta partição está instalada. O valor de F8 do nosso caso corresponde ao HDD.
Os bytes de 0018h a 001Fh, de 0024h a 0027h, de 0041h a 0043h, de 0045h a 0047h e de 0050h a 0053h não são usados pelo sistema NTFS, pelo que não importa o que esteja inscrito neles.

Os 8 bytes de 0028h a 002Fh identificam o número de setores do volume. No nosso caso serão 30D84FF8h ou 819.482.616 setores.
Os 8 bytes de 0030h a 0037h identificam o LCN (Logical Cluster Number) onde se inicia o ficheiro $MFT. No nosso caso inicia-se no cluster 3, ou seja, o seu offset é de 24 setores (3000h), relativo ao início da partição.
Os 8 bytes de 0038h a 003Fh identificam o LCN onde se inicia o ficheiro $MFT MIRR. No nosso caso inicia-se no cluster 31h, ou 49 em decimal, tendo portanto 392 setores antes, correspondendo-lhe o offset 31000h relativo ao início da partição.
O byte em 0040h indica a dimensão de cada registo da MFT.
- Se este valor, quando lido em complemento para dois for positivo, de 00h até 7Fh (0000 0000 a 0111 1111), corresponde ao efetivo número de clusters por registo.
- Se este valor, quando lido em complemento para dois for negativo, de 80h a FFh (1000 0000 a 1111 1111), a dimensão em bytes de cada registo corresponde a 2 elevado à potência do valor absoluto do byte.
No nosso caso tem o valor de F6, que convertido em binário dá 1111 0110, um valor negativo. O seu simétrico é 00001001 + 1 = 00001010 ou, em decimal, 10. Portanto, como 210 = 1024 bytes ou 1 KB, essa é a dimensão de cada registo da MFT.
O byte em 0044h representa o número de clusters por cada Index Buffer.
- Tal como no caso anterior, se for positivo (até 7F) corresponde ao número efetivo de clusters.
- Se for negativo o seu tamanho é o resultante de 2 elevado à potência do valor absoluto do byte.
No nosso caso é positivo e é 1. Portanto, cada index buffer tem 1 cluster.
Os 8 bytes de 0048h a 004Fh indicam o número de série do volume.
Juntamos na figura 5, uma tabela de síntese de toda a informação sobre o PBS até agora analisada.
Muita da informação que vamos fornecer a partir daqui terá os seus nomes em Inglês, sem que se possam traduzir. Consequência da influência do Inglês na Ciência da Computação. Também se entende. Toda a sua evolução tem estado nas mãos dos que falam a língua do Tio Sam.
MFT ( Master File Table)
Já usámos por várias vezes o termo de MFT (Master File Table), que é a tabela onde o NTFS guarda um registo ou entrada por cada ficheiro existente.
Comecemos por entender a diferença entre os dois tipos de ficheiros existentes numa MFT:
- Ficheiros Normais, que são aqueles que contém informação sobre os nossos dados.
- Ficheiros de Metadados, que são aqueles que contém informação sobre o Volume e os Ficheiros Normais. O nome destes ficheiros começa sempre pelo sinal $.
Todas as entradas de uma MFT são ficheiros. Sejam entradas correspondentes a Ficheiros Normais, a Ficheiros de Metadados ($) ou a Index Buffers (Diretórios).
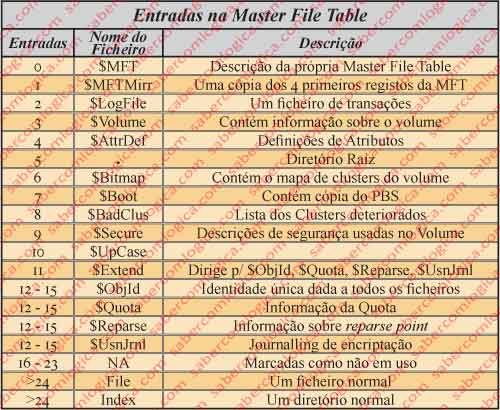
As primeiras entradas da MFT são, como podemos ver na tabela da figura 68, ficheiros de Metadados.
Até à entrada 11 estão os ficheiros de metadados ($), que ensinam a trabalhar com o sistema de ficheiros. A partir da entrada 24 estão os ficheiros e os diretórios propriamente ditos.
Começa na descrição destes ficheiros a adensar-se a complexidade do NTFS. Vamos ter ficheiros de Metadados que apontam para si próprios, como é o caso do $MFT.
Vamos agora introduzir alguns conceitos que vão ser referidos já de seguida ao longo das análises que vamos fazer neste capítulo.
Update Sequence e Update Sequence Number
Um Ficheiro está contido em pelo menos 2 setores (1024 bytes ou 1KB) e um Ficheiro Index em pelo menos 8 setores (4KB ou 1 Cluster). Mas ambos podem ocupar mais setores se tiverem extensões.
Devido a esta possibilidade de dispersão de um ficheiro por múltiplos setores, o NTFS coloca, nos 2 últimos Bytes de cada setor de um ficheiro, o Update sequence number definido para o mesmo, num processo designado por FIXUP. Desta forma, o sistema pode obter a confirmação de que um setor pertence à sequência de setores de um ficheiro.
Mas assim vai-se perder a informação que lá estava?
Não, porque o NTFS guarda na update sequence, por ordem, os bytes substituídos em todos os setores alterados. A update sequence terá tantas palavras (2 bytes ou 16 bits) quantos os setores do ficheiro mais uma, a primeira, que corresponde precisamente ao update sequence number. E é aí que o NTFS vai buscar a informação necessária quando ler os bytes substituídos.
De cada vez que o ficheiro for atualizado o update sequence number é incrementado, para que não fique a apontar para ficheiros fora de uso (antigas extensões). Talvez seja mais fácil de entender isto se pensarmos nas consequências de uma desfragmentação do disco. Na sequência desta, o atributo que definia as posições dos vários pedaços de um determinado ficheiro muito fragmentado que devido à sua dimensão ocupava uma extensão, foi bastante reduzido, passando a caber no ficheiro base. Então, no setor da ex-extensão é alterado o byte que define o estado de uso do setor e no ficheiro base é incrementado o update sequence number, pelo que o setor desocupado deixa de indicar este ficheiro.
Hard Link
São assim designados todos os links, caminhos ou pathnames que apontam para um ficheiro.
Os utilizadores do Windows 7 ou superiores entendem melhor o seu significado se lhes referirmos os diretórios do Explorer a que não têm acesso e que têm uma seta sobre eles. Esses diretórios referem nomes de caminhos em versões anteriores ao Windows 7, que definiu caminhos diferentes para chegar aos mesmos sítios.
Por exemplo o atual AppData era Application Data.
Se esta compatibilização não existisse, os programas desenvolvidos para os caminhos anteriores perdiam-se e deixavam de funcionar. Eles apontam para o mesmo local que os novos caminhos, mas não têm conteúdo e só o sistema deve ter acesso a eles. São Hard Links.
Reparse Point
Um reparse point é um pequeno pedaço de código num ficheiro, que inclui uma referência para um filtro do sistema de ficheiros a ser usado para a sua interpretação.
Ao ser detetado durante a leitura a existência de um reparse point, o sistema faz apelo ao dito filtro para que cumpra a sua função predefinida. Agora em linguagem prática: estão a ver os Icons do ambiente de trabalho em que se clica para abrir um programa? Chamamos-lhes shortcuts, ou caminhos rápidos para um determinado programa, ou ficheiro. Lembremos que no disco tudo são ficheiros. E o tal Icon não é mais do que um pequeno ficheiro com um reparse point que, ao ser detetado, aciona um filtro do sistema que o interpreta e executa, abrindo o ficheiro que se pretende e que por ele é apontado. Da mesma forma, os tais diretórios do Windows 7 de que há pouco falámos, que garantem compatibilidade com sistemas anteriores, contêm reparse point que, de uma forma transparente para o utilizador, enviam o que lhes é destinado para o endereço por eles apontado.
Ficheiro Esparso
Um ficheiro esparso é um ficheiro que contém grandes espaços com zeros intercalados entre pequenos espaços com dados significativos.
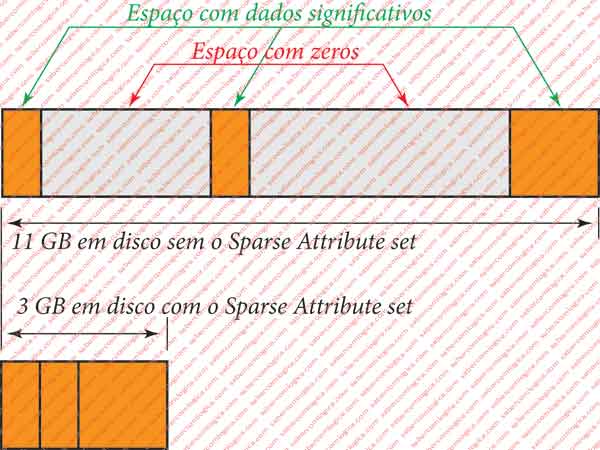
Para poupar espaço em disco, só os dados significativos são guardados sendo que o sistema mantém guardada uma referência aos espaços de zeros e à sua quantidade. Ver figura 17.
Ao ser lido, a parte guardada em disco é preenchida com os dados que de lá são lidos e a parte não guardada, que o sistema de ficheiros conhece, é preenchida com zeros.
Não são muitos os sistemas de ficheiros que suportam ficheiros esparsos. O NTFS suporta esta funcionalidade.
Os ficheiros esparsos fragmentam-se muito e rapidamente. Quando é feita uma cópia de um ficheiro esparso para outro sistema que não suporte esta funcionalidade, ele é reconstruído e guardado com toda a sua dimensão.
Namespace
O Namespace de um ficheiro indica o espaço de definição de nomes em que ele se insere. Esses espaços são os seguintes:
- POSIX – 255 carateres e Unicode, sensível a maiúsculas ou minúsculas.
- Win32 – 255 carateres e Unicode (difere do anterior na limitação de carateres aceites).
- DOS – 8 carateres em maiúsculas seguidos de ponto e mais 3 carateres.
- Win32 e DOS – Quer dizer que o nome foi escrito de forma a que se pode inserir nos dois espaços, restando-lhe assim uma só descrição.
O NTFS, por questões de compatibilidade, descreve os ficheiros que se inserem no namespace 2, repetidamente com o namespace 3, isto é, os ficheiros que têm um nome com mais de 8 carateres são descritos no namespace 2 e convertidos a 8 carateres, para serem descritos no namespace 3 também.
No nosso caso, o nome do ficheiro tem 8 carateres, portanto pode ser descrito no namespace 3, o DOS. Os nomes em DOS podem ter até 8 carateres mais 3 carateres para a extensão. O nosso nome tem 8 carateres e não tem extensão. Não esqueçamos que o nome do ficheiro que estamos a analisar é $AttrDef. Apesar de já termos falado de uma série de outros nomes, referimo-nos a nomes de atributos que definem o ficheiro. Apesar de a exposição já ir longa, o ficheiro ainda é o mesmo.
A forma como é descrito o nome pode ver-se na figura 18, onde na parte de cima aparece a edição hexadecimal dessa zona, agora com o texto que o editor nos apresenta. Na parte de baixo da figura está representada carater a carater a reapresentação do nome nos 11 carateres que o DOS permite.
Mas porque têm todos um ponto a seguir?
Como já se disse, os carateres do nome são representados em Unicode. O Unicode dispõe de 16 bits para representar todos os carateres de todas as línguas e escritas do mundo, mais muitos carateres especiais e ainda lhe sobra muito espaço.
O byte de menor ordem (não esquecer que aqui estão por ordem inversa) contém a parte do código ASCII estendido (ANSI), que é representada em 8 bits. O byte de maior ordem complementa estes para formar o Unicode. Mas no editor de texto os bytes são interpretados um a um pelo código ANSI (ASCII estendido) e então 00 é lido como ponto. Em Unicode, o conjunto dos 2 bytes é lido pelo mesmo valor que ANSI lê o byte de menor ordem.
E então os 3 carateres da extensão?
Este ficheiro, como se vê no nome, não tem extensão. A extensão serve para ficheiros como .txt, .jpg, .doc, etc.
Só por curiosidade: A extensão não compromete o conteúdo do ficheiro nem a sua operação.. É apenas um indicador para o SO saber o tipo de porgrama que deve usar para ler aquele ficheiro. Se pusermos uma extensão .jpg na frente de um documento do Word, o que acontece se o tentarmos abrir é que o SO vai utilizar um editor de imagem para o fazer e vai dar um erro. Mas se abrirmos o Word e a partir daí mandarmos abrir o tal ficheiro word com extensão .jpg, tudo vai correr normalmente e o documento word vai abrir.
Pronto! Já chega de introdução de conceitos e vamos prosseguir com a análise do Ficheiro começando pelo seu descritor e passando aos seus atributos.
Descritor de ficheiro
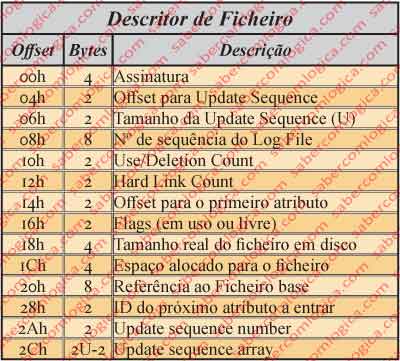
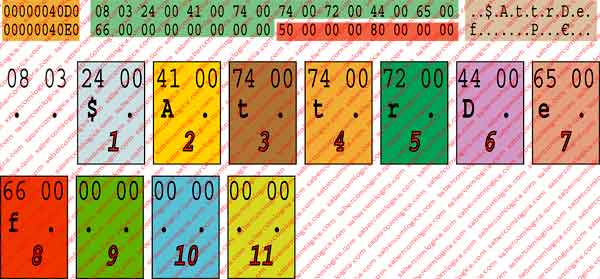
O descritor de um ficheiro deve ser lido de acordo com a tabela da figura 7 que de seguida se analisa em pormenor. Vamos usar a imagem do editor hexadecimal do ficheiro $AttrDef que usaremos mais para a frente, conforme podemos ver na figure 32.
O descritor do ficheiro $AttrDef, assinalado a amarelo, está de seguida decomposto nos seus vários campos conforme se pode ver na figura 8, a qual vamos utilizar na comparação do nosso caso real com a tabela da figura 7.
Os 4 bytes de 4000h a 4003h correspondem à Assinatura. No nosso caso é FILE.
Os 2 bytes em 4004h e 4005h definem o Offset para Update sequence. No nosso caso 2Ah .
Os 2 bytes em 4006h e 4007h definem o tamanho da update sequence em words. No nosso caso 03h (3 words ou 6 Bytes) .
Os 8 bytes de 4008h a 400Fh correspondem ao Log File sequence number – 02002783h. Este número muda de cada vez que o registo é alterado.
Os 2 bytes em 4010h e 4011h representam o use/deletion count – 04h no nosso caso. Representa o número de vezes que este espaço de registo foi reutilizado. É incrementado de cada vez que o registo nele contido é apagado.
Os 2 bytes em 4012h e 4013h definem o Hard Link count – 01 no nosso caso. Representa o número de entradas de diretório que referem este ficheiro.
Os 2 bytes em 4014h e 4015h definem o offset para o primeiro atributo, 30h no nosso caso. É o local onde se inicia a descrição do 1º atributo para este ficheiro. Este offset pode variar de acordo com a dimensão da update sequence, que já verificámos que tem tamanho variável consoante o número de setores ocupados pelo ficheiro.

Os 2 bytes em 4016h e 4017h são as Flags – 01 no nosso caso, o que significa que este espaço de registo está em uso.
- 00 – Espaço de registo livre.
- 01 – Registo em uso.
- 02 – O registo é um diretório.
Os 4 bytes de 4018h a 401Bh indicam o tamanho real do ficheiro – no nosso caso 416 Bytes. Representa o número de Bytes realmente utilizado pelo ficheiro acrescido de um padding ao múltiplo de 8 bytes mais próximo. Aqui o padding faz acerto a 8 bytes, os seja meia linha da tabela.
Os 4 bytes de 401Ch a 401Fh indicam o tamanho alocado do ficheiro, que no nosso caso é 1024 Bytes. Representa o espaço que qualquer ficheiro ocupa na MFT e que é 1 KB (2 setores) ou múltiplos se tiver extensões.
Os 8 bytes de 4020h a 4027h referem o registo base – 0 no nosso caso. Quando é zero é porque se trata do registo base do ficheiro na MFT. Se for diferente de zero, aponta para o registo do ficheiro base na MFT, de que é extensão.
Os 2 bytes em 4028h e 4029h – Id do próximo atributo – 6, o que significa que o próximo atributo a entrar para este ficheiro terá o ID=6.
Os 2 bytes em 402Ah e 402Bh correspondem ao Update sequence number e constituem a primeira das 3 palavras da update sequence.
Os 4 bytes de 402Ch a 402Fh correspondem às restantes palavras da update sequence, que contém o valor dos dois últimos bytes de cada um dos setores do ficheiro ou extensões substituídos pelo update sequence number.
Porque pode ser confuso vamos aproveitar este caso concreto para clarificar o que são a Update Sequence e o Update Sequence Number. Como vimos, o nosso ficheiro ocupa 2 setores (1 KB). Então a Update Sequence é definida por 3 palavras:
- A primeira indica o Update Sequence Number, aquele que vai estar no final de cada um dos 2 setores do ficheiro, que é 17 00.
- As duas seguintes indicam o valor que estava na última palavra de cada um dos 2 setores do ficheiro, que foram substituídas pelo Update Sequence Number e que são 00 00 e 00 00.
Vamos agora começar a análise dos Atributos dos Ficheiros, o que deixamos para o artigo seguinte.