
Mapeamento da Cache
Quando a CPU acede à memória, fá-lo através de um endereço que indica a posição do registo que pretende na MP. Não na Cache, como é evidente.
Para a CPU a Cache é uma transparência. A Cache é organizada por Blocos de vários bytes (as linhas de cache). As localizações na Cache não têm qualquer relação com as localizações na MP.
Então temos que procurar na Cache pelo endereço do byte na MP.
Mas procurar como? Rebuscando? Indo de um em um?
Bom, para isso seria melhor que a cache nunca tivesse existido. Seria certamente mais demorado do que ir à MP. É preciso que o dado seja fornecido de imediato, por acesso direto e simultâneo a todos os blocos, com base nos elementos do endereço.
Para isso, a Cache tem várias formas possíveis de organização, conforme o método escolhido para acesso à mesma. Resumindo, a cache vai ter que ser mapeada, isto é, vamos ter que elaborar um mapa onde constem os registos que lá estão e onde. Era como fazia o nosso amigo responsável do arquivo. Colocava por sala e estante, o endereço no arquivo. E depois escrevia à parte que registos tinha em cada separador, senão teria que os procurar um a um dentro do separador.
Vamos juntar uns esquemas que só pretendem mostrar como se processam os vários métodos de acesso. São meramente ilustrativos, não tendo nada a ver com a memória para que vimos criando circuitos.
Nestes esquemas a Cache tem 8 linhas com 8 Bytes por linha. De seguida e noutros quadros veremos como se processa em pormenor o acesso à Cache. A procura de um byte tem que ser feita em hardware, de forma direta, imediata e à primeira busca, em qualquer das situações.
Devido à reduzida dimensão que dispomos nestes gráficos, os valores 1 e 0 dos bits serão representados por círculos vermelhos ou cinzentos, respetivamente.
O endereço enviado pela CPU é decomposto em várias partes:
Dos bits de menor peso, são retirados os necessários para identificar o deslocamento dos bytes na linha ou bloco.
A linha tem 8 bytes. Então precisamos de 3 bits para definir a posição do byte no bloco, isto é, o deslocamento do byte.
Numa mesma linha com 8 bytes, os 3 bits em que o endereço de cada byte acaba vai desde 000 até 111. É a este valor que chamamos deslocamento, ou distância em relação ao início da linha.
Dos bits seguintes retira-se o número suficiente de bits para representar o número de linhas da cache. Neste caso serão também 3 bits (8 linhas). Chama-se a este conjunto o índice e define a posição do bloco (linha) que todos os registos que tenham estes 3 bits ocupam na Cache, sendo organizados de forma sequencial.
Assim, um endereço que tenha como valor dos últimos 6 bits 010 100, estará sempre na 3ª linha (índice=010) a contar de baixo e será o 5º (deslocamento=100) nessa linha, a contar da direita. Estamos a organizar a Cache de baixo para cima e da esquerda para a direita.
Encontrada a linha e a coluna de uma forma imediata e direta, só falta comparar a etiqueta da linha com os mesmos bits do endereço (os restantes bits) e verificar se coincidem.
Se assim for teremos um Cache Hit e o valor do byte é lido.
Se olharmos para o quadro respetivo, representado na Figura 4 (à esquerda), vemos que:
- No percurso indicado com 1 é feita a seleção da linha com a posição correspondente ao valor do índice no endereço do byte a ler.
- No percurso indicado com 4 é feita a seleção da coluna do byte a ler, cuja posição é correspondente ao valor do deslocamento no endereço do byte a ler.
- No percurso indicado com 2 é feita a comparação do valor da etiqueta dessa linha com os correspondentes bytes no endereço do byte a ler.
- No percurso indicado com 3, em caso de Cache Hit, é feita a seleção do Byte na posição da Cache assim encontrada, pois ele é o mesmo que se encontra nesse endereço da MP.
Nada mais simples e direto. Mas como em tudo o mais, não há bela sem senão.
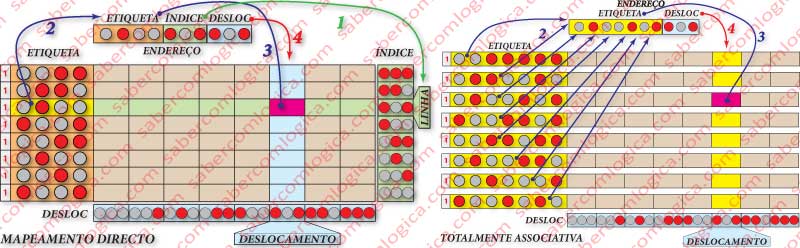
Todos os endereços com os mesmos 3 bits de índice vão sempre para a mesma linha. Isto significa que, mesmo que esta linha de cache contenha uma série de registos que venham a ser necessários de imediato, se um salto obrigar a ir buscar outro endereço que contenha os mesmo 3 bits de índice, esse novo Bloco é colocado na mesma linha, substituindo o que lá se encontra.
Pelo mesmo motivo, podemos chegar ao fim de um programa com uma série de linhas de cache por ocupar. Basta que nunca sejam acedidos endereços que contenham certa combinação dos bits do índice. E quanto mais linhas tiver a cache, mais provável é que isto aconteça.
Assim, com este mapeamento baixa substancialmente a taxa de sucesso. Um mapeamento simples, com pouco hardware mas com várias limitações.
Mapeamento Totalmente Associativo
Neste mapeamento, ilustrado na Figura 4 (à direita), qualquer linha pode ocupar qualquer posição, podendo inclusive coexistir em cache vários Blocos que no método anterior teriam que estar sempre na mesma linha. Teremos simplesmente a etiqueta e o deslocamento. Não há índice.
Mas assim vamos ter de correr todas as linhas à procura da etiqueta que queremos?
É evidente que não. Isso demoraria tempos infindos e pretende-se uma solução direta, com resposta imediata e sem procura. Na cache, qualquer procura é feita por hardware e de forma imediata.
Então, para que assim seja, temos que usar um comparador por cada linha de cache, sendo introduzido em cada um e em simultâneo o valor dos bits do endereço correspondentes à etiqueta dessa linha com que é feita a comparação.
Assim, se existir em cache o endereço que procuramos, a resposta será imediata e a identificação da linha também. A coluna é identificada da mesma forma que no método anterior, pelo deslocamento.
Portanto, a solução também é direta, mas tem a desvantagem de utilizar muito hardware, isto é, uma enormidade de transístores por cada comparador e linha de cache, o que vai diminuir o espaço para as células de memória.
No caso da nossa míni Cache seria o ideal. Mas se estivermos a falar de uma cache de 8 MB (8 milhões de bytes) a conversa já não será a mesma.
O Mapeamento Totalmente Associativo é um mapeamento associativo por conjuntos de n Vias, em que n representa o números de linhas ou blocos da Cache.
Na nossa pequena Cache, um Mapeamento totalmente Associativo seria um mapeamento a 8 vias, tantas quantas as suas linhas. Uma linha por conjunto.
Mapeamento Associativo por Conjuntos
Este mapeamento é obtido pela junção dos anteriores. Cada conjunto internamente é mapeado em mapeamento direto e os conjuntos são mapeados em mapeamento associativo.
Em cada conjunto qualquer bloco a que corresponda o conjunto de bits do endereço que identifica o índice, tem que estar sempre na mesma linha. No caso de mapeamento associativo a 2 Vias teremos sempre 2 linhas que satisfazem a procura e cuja etiqueta é selecionada para um comparador, onde é verificado se o seu conteúdo confere com o do endereço do byte.
Na nossa pequena Cache, a 2 vias correspondem portanto dois comparadores e 4 linhas por via em mapeamento direto. Na Figura 5 (à esquerda) podemos ver o gráfico ilustrativo deste tipo e associatividade.
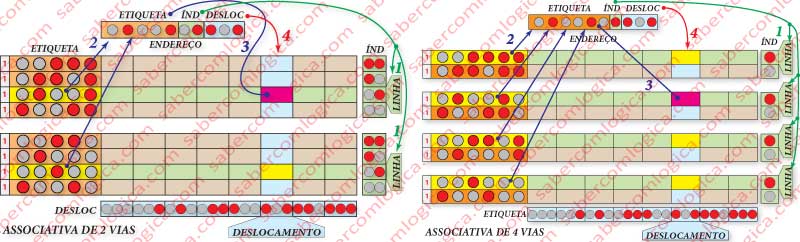
Se passarmos para um mapeamento associativo de 4 vias, teremos sempre 4 linhas que satisfazem a procura pelo índice e cuja etiqueta é selecionada para um comparador, onde é verificado se o seu conteúdo confere com o do endereço do byte.
Temos 4 conjuntos de mapeamento direto que por sua vez são acedidos em mapeamento associativo.
Na nossa pequena Cache, a 4 vias correspondem 2 comparadores e 4 linhas por via em mapeamento direto.
Conforme se pode visualizar na Figura 5 (à direita), teremos 4 grupos de 2 linhas, sendo então o índice de 1 bit (com 1 bit representam-se duas linhas). A cada procura 4 etiquetas (1) são selecionadas ( as que têm fundo a amarelo), que são comparadas em simultâneo, em 4 comparadores diferentes, com os correspondentes bits do endereço (2), daí saindo o resultado de cache hit ou cache miss. Em caso de cache hit, será escolhido o byte da coluna correspondente ao deslocamento (3).
O Mapeamento Associativo por Conjuntos é utilizado nas Caches de CPU com tecnologia de ponta, incorporadas no seu próprio chip, como veremos adiante no caso de estudo.
Métodos de substituição de Blocos em cache
Para a substituição de Blocos em cache destacamos 3 métodos:
- O FIFO (First In First Out) ou o primeiro a entrar é o primeiro a sair. Sai sempre o bloco que está há mais tempo na cache.
- O LRU (Least Recently Used) ou menos usado recentemente.
- O Aleatório, isto é, o computador escolhe aleatoriamente, como o nome diz.
Na Cache com mapeamento direto, o método de substituição é da mais elementar simplicidade. Cada bloco que tenha que entrar só tem um lugar onde pode ser colocado. É no lugar onde se encontra o bloco definido pelos mesmos bits de índice e deslocamento.
É na Cache Associativa que a questão de qual bloco substituir se coloca.
Na Totalmente Associativa há que escolher entre todos os blocos, qual substituir.
Na Associativa por Conjuntos há que escolher entre os blocos com o mesmo índice nos vários conjuntos, qual substituir. Como dentro dos conjuntos o mapeamento é direto, não há escolha a fazer.
Devido à atual dimensão da Cache em qualquer CPU, é a Cache Associativa por Conjuntos, que constitui a opção mais corrente.
Caso entre os blocos a escolher existam alguns com o bit de validade a zero, então a escolha para substituição é feita aleatoriamente por um desses.
O FIFO parece um método de solução aparentemente eficiente, mas não resultará em muitos casos, pois um bloco pode estar há muito tempo na cache e ser um dos mais utilizados, pelo que deitá-lo fora é um desperdício e perda de tempo, uma vez que muito provavelmente se tem que ir buscar logo de seguida.
A sua implementação é de relativa simplicidade em hardware. Basta que os blocos com o mesmo índice sejam guardados em conjuntos com uma determinada sequência, crescente por exemplo e ter um ponteiro que para cada conjunto define o próximo a ser substituído.
Veja-se no gráfico da Figura 8( à direita) uma hipótese de implementação. Os blocos são sempre escritos nos conjuntos de forma crescente de baixo para cima. Um bit a 1 é sempre colocado no bloco a escrever (começa no primeiro). Por cada escrita o bit a 1 passa ao bloco seguinte e o anterior é reposto a 0. Ao chegar ao último, volta ao primeiro. Desta forma o bit a 1 funciona como um ponteiro que aponta sempre para o bloco a escrever, que é o mais antigo.
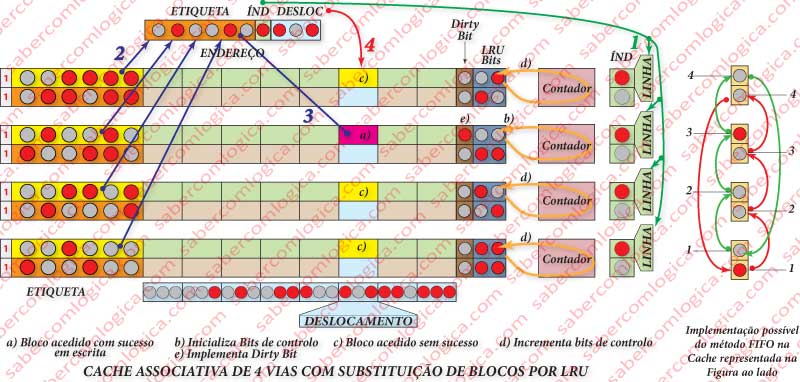
O LRU já levanta questões mais complexas que, conforme o grau de rigor com que se pretenda implementar, pode exigir grandes quantidades de lógica de suporte. A lógica de suporte a implementar pode ir desde uma solução bastante leve, mas com grau mais baixo de rigor na escolha até uma solução de rigor máximo, com envolvimento de muita lógica, portanto muitos transístores.
A Solução mais simples, mas evidentemente com muito menos controlo e rigor, consiste em utilizar um bit de controlo que, sempre que o bloco é acedido, é posto a 0. Periodicamente, num intervalo de um determinado número de ciclos de clock, existirá um mecanismo que colocará todos os bits a 1. Quando for preciso fazer a substituição, a escolha será aleatória sobre aqueles que ainda tiverem o bit a 1.
A Solução mais complexa, mas que permite maior rigor na escolha, consiste na criação de um contador binário por conjunto. Acrescentam-se ao bloco de cache os bits necessários para representar todas as vias, por exemplo 2 bits para 4 vias como na Figura 8 e ligam-se esses bits ao contador do conjunto.
Por cada acesso à cache, de cada vez que o bloco dessa via não é acedido, o conjunto de bits de controlo é incrementado e o conjunto de bits do bloco da via que é acedida é reiniciado a zero. Assim, os blocos acedidos mais frequentemente têm contagens inferiores, mesmo que sejam os mais antigos na cache. Claro que esta solução tem que dispor de um mecanismo de bloqueio do contador quando a contagem chega ao máximo. Como se sabe os contadores são rotativos e então voltariam a 0, deturpando o rigor.
Também tem de dispor de um apontador que indique a cada momento qual o bloco que reúne as condições de substituição. É preciso não esquecer que na Cache tudo tem que ser resolvido em hardware e numa só busca encontrar o que se quer. Não são admitidas procuras cíclicas.
Entre vários blocos com a mesma contagem o apontador deve indicar aleatoriamente um deles.
Claro que o rigor da escolha aumenta consoante o número de bits do contador e daqueles que por bloco lhe são dedicados, aumentar. Como é evidente também o custo aumentará exponencialmente.
Política de escrita em Cache
Há dois métodos possíveis para escrita de valores em Cache na MP quando necessário:
- Write Through, que consiste na escrita do valor em Cache e na MP em simultâneo.
- Write Back, que consiste na escrita em Cache, guardando a escrita em MP para quando o bloco em questão tiver que sair da cache.
Para este último método a cache deverá possuir mais um bit de informação a que se chama Dirty Bit (bit sujo) como na Figura 8( à esquerda), que dá indicação, quando colocado a 1, que os valores do bloco foram alterados e deverão ser escritos em MP.
Este último processo pode provocar problemas complicados de inconsistência de cache, devido à existência de DMA (Direct Memory Access) ou acesso direto à memória, que é proporcionada a certos periféricos, como o Disco Principal e que consiste na possibilidade de esses periféricos acederem diretamente à MP sem passarem pela CPU.
Pode por isso acontecer que um determinado dado de um Bloco que se encontre em cache seja alterado na MP. Quando se efetuar a escrita desse Bloco na MP a atualização anterior desaparecerá, a não ser que por cada acesso de DMA se faça uma consulta e atualização de todos os Blocos que contenham o dirty bit a 1. É evidente que tal processo é moroso.
A CPU é libertada mal o valor é escrito em cache, sendo o restante trabalho efetuado pela MMU, que recebe todos os valores que são escritos em cache com os respetivos endereços e se encarrega do seu registo na MP.
Para esse efeito já estão previstos nas caches que utilizam este método, buffers de retenção com fila de espera. Assim, é possível que a MMU vá guardando valores a escrever e que os vá atualizando conforme dispõe de tempo de acesso à memória.
Quando há qualquer pedido de acesso DMA, antes de o mesmo ser autorizado é garantido o esvaziamento do buffer de elementos a registar, para ficar sempre garantida a consistência da MP.
A escrita em cache, em caso de Cache Miss, deverá ter sempre o mesmo tratamento que para uma operação de leitura. O Bloco deverá ser carregado em cache para ser escrito o valor pretendido seguindo-se depois todo o procedimento já descrito.