
Memória Virtual
Mas então, se um programa pode estar em execução em simultâneo com outros, como é que o programador ou o compilador fazem para atribuir locais de memória para as instruções e dados do seu programa, que saibam não ser coincidentes com as dos outros?
Pois é. Aí correm o risco de colocar programas diferentes a concorrerem para os mesmos espaços de memória, pelo que o programa retirado da UCP, quando lá voltasse tinha tudo baralhado.
Por isso mesmo os programadores devem realizar convénios frequentes entre eles para combinarem entre si os espaços de memória que cada um vai utilizar. De preferência em bons hotéis e em regiões turísticas famosas, para compensar o enfadonho que será estar a assistir à discussão do sexo dos anjos perante uma confusão indescritível da qual nunca sairia qualquer solução.
Acontece ainda que o espaço da memória física de um computador nunca seria suficiente para a atribuição de espaços separados a todos os programadores. Nem sequer, na maioria das situações, para acolher todos os programas em execução em simultâneo num computador que, como já vimos, tem que ter em memória tudo o que a UCP executa.
Como solução para esta questão, o SO tomou o lugar desses espaços de convívio e imaginou uma coisa a que chamou Memória Virtual, que dispõe de um espaço de endereçamento da dimensão dos registadores da UCP:
- Para UCP de 32 bits e SO de 32 bits o espaço virtual de endereçamento está limitado aos 32 bits e corresponde a 4 GB.
- Para UCP de 64 bits e SO de 64 bits o espaço virtual de endereçamento está confinado aos 64 bits (16 Exabytes), embora os diversos SO possam impor limitações inferiores.
Dentro destes espaços, os programas podem escolher qualquer um, não havendo mesmo problemas que vários escolham espaços coincidentes. Até podem todos escolher espaços coincidentes.
Mas então voltamos a ter o mesmo problema!
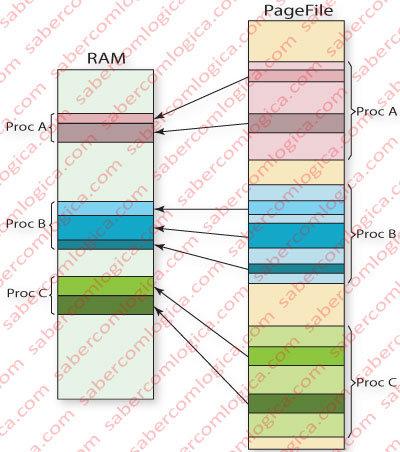
É aqui que surge a intervenção do SO que, com suporte em estruturas próprias de hardware, atribui espaços reais de endereçamento diferentes a cada processo criado. Chama-se o Espaço de Endereçamento do Processo e cada processo tem um espaço diferente (Figura 1).
Mas então, se os espaços de endereçamento do processo não são os mesmos que foram gerados pelo compilador para o programa, como é que a cada instrução a UCP se dirige ao endereço correto?
A cada requisição de endereço feita pela UCP, o SO executa um mecanismo de tradução que converte o endereço virtual (o requisitado) no endereço físico que lhe corresponde. E faz isso através de tabelas de correspondência entre endereços virtuais e físicos. Claro que se essa tabela tivesse correspondência para cada um dos endereços virtuais, o espaço ocupado em memória seria gigantesco.
Para um processador de 32 bits seria uma tabela com 4.294.967.296 linhas e 32 bits por linha, o que daria uns módicos 17 GB. Ora, não podendo estar em memória tal tabela, a performance desceria para valores totalmente inaceitáveis. Era preciso encontrar outra solução.
Resolveram então que os endereços seriam acumulados em blocos de endereços contíguos. Esses blocos podem tomar vários nomes, como páginas ou segmentos e a divisão da memória nos mesmos, paginação, segmentação ou segmentação paginada. Vamos abordar neste trabalho simplesmente o caso das Páginas, ou Paginação de Memória.
Os tais blocos de endereços contíguos, ou Páginas, podem ter qualquer dimensão, mas para a determinar havia que ter em conta que:
- Páginas mais pequenas davam um melhor controlo sobre que endereços se carregavam em memória, mas consequentemente aumentavam a dimensão da tabela.
- Páginas maiores dão um menor controlo sobre que endereços se carregam em memória (não esquecer que quando um endereço é necessário se carrega toda uma página) , mas diminuem a dimensão da tabela.
O valor da dimensão da página faz parte da arquitetura da máquina e não pode ser alterado, sendo presentemente o valor mais correntemente adotado de 4 KB.
A correspondência deste valor com o valor do Cluster mais habitual para um Disco Rígido não é certamente inocente. Como vimos, o menor valor que pode ser movimentado entre a Memória e o HD é de um Cluster, que no caso mais corrente são 8 Setores ou 4 KB.
Portanto, vamos tomar como pressuposto que o tamanho das páginas é de 4KB. Precisamos então de 12 bits para representar o conteúdo de cada página (212 = 4.096).
A correspondência de endereços passa então a fazer-se por páginas. Portanto um endereço virtual de 32 bits, tem uma primeira parte com 20 bits que representa as páginas e uma segunda parte com 12 bits que representa o deslocamento dentro da página, sendo que o deslocamento dentro do endereço virtual corresponderá ao deslocamento dentro do endereço físico (0 a 0, 1 a 1, 2 a 2,…, e 4.095 a 4.095).
Surge assim um novo conceito, a Tabela de Páginas (TP) que indexa para cada uma das 220 diferentes ETP (Entradas de Tabela de Páginas) a correspondente Página Física.

Acompanhemos esta descrição pela Figura 2, na qual vamos mapear o endereço virtual 0000 1100 0011 1001 1110 0011 0011 0111 ou 205.120.311 em decimal ao endereço físico 0011 0011 0111 0010 1111 0011 0011 0111 ou 863.171.383 em decimal.
Os primeiros 20 bits do endereço virtual 0000 1100 0011 1001 1110 ou 50.078, indicam a entrada da tabela de páginas onde se encontra registado o endereço base da página física que contém o endereço a mapear. Nessa ETP nº 50.078 está o valor 0011 0011 0111 0010 1111 que adicionado ao offset do endereço base da página física, isto é 0000 0000 0000, dará o endereço base da página física que pretendemos 0011 0011 0111 0010 1111 0000 0000 0000 ou seja 863.170.560 em decimal.
Se adicionarmos o offset da página no endereço virtual, isto é o valor dos seus últimos 12 bits, 0011 0011 0111 obteremos o endereço pretendido dentro da página já encontrada
0011 0011 0111 0010 1111 0011 0011 0111
ou seja 863.171.383 em decimal.
Então, a Tabela de Páginas terá 220 = 1.048.576 linhas e cada linha deverá ter 20 bits, correspondente à informação que contém relativa à localização da Página Física. Para que assim possa ser as páginas físicas são sempre colocadas em memória com início num qualquer endereço em que os 12 últimos bits sejam 0, conseguindo-se assim qualquer endereço da Página Física concatenando o valor dos primeiros 20 bits com os 12 do offset, no nosso caso 0011 0011 0111.
Resulta assim uma dimensão de 220 x 20 / 8= 2.621.440 Bytes ou 2,6 MB para a Tabela de Páginas.
Ligeiramente diferente da primeira situação, não?
Já vimos que a Tabela de Páginas tem que estar presente em memória para que da sua consulta não resulte uma quebra de performance inaceitável. Desta forma, tal já é possível sem que seja muito significativo o espaço de memória ocupado.
Mas vamos falar mais um pouco sobre a Memória Virtual, que não se resume apenas a endereços virtuais.
Quando um programa é executado, passando a constituir um processo, todos os elementos relativos ao mesmo e necessários ao seu processamento têm que estar em memória. Só que, a memória RAM nem sempre é suficiente para conter a totalidade de informação relativa a todos os processos em curso, digamos mesmo que normalmente não é.
Devido a este facto, a execução de um programa começa pelo mapeamento das suas instruções e dados em disco, em blocos virtuais, que farão parte de um ficheiro a que se dá o nome de Swapfile ou ainda Pagefile, que contém ou refere os objetos em disco que fazem parte do referido mapeamento. Como o nome diz, é um ficheiro de trocas (swap) de páginas (page), onde as páginas constituintes de cada processo são colocadas durante a sua criação. A este procedimento chama-se Paginação, pelo que passaremos a designar o referido ficheiro por Pagefile.
É evidente que o SO não tem forma de determinar quais destas páginas serão de imediato necessárias ao processo. Assim, a Tabela de Páginas é preenchida com índices que referem entradas numa Tabela de Swap (tabela de troca) que por sua vez indexa a localização exata das páginas em disco e com a indicação de que não se encontram em memória, o que é feito através de um bit de controlo (V) em cada entrada da Tabela de Páginas que indica se a Página está em memória ou em disco, isto é, se é física ou virtual.
O código, porque já se encontra no ficheiro executável organizado pela forma que vai ser chamado, é normalmente paginado no local do próprio ficheiro executável. O SO abre o ficheiro, pagina-o, preenche a tabela de páginas com V=0 e com um valor indexante para a tabela de swap, que indicará a sua posição em disco.
Por cada vez que a UCP solicita uma página que não está em memória, então a mesma é lida do Pagefile e colocada em memória. A este método chama-se paginação por necessidade (on demand).
Alternativamente, o SO pode, de cada vez que é detetada uma falta de página (page fault) deslocar para a memória física uma série de páginas a mais que se encontrem na proximidade dessa, de acordo com o princípio da localidade, pois quando é feita uma consulta de um endereço na memória é muito provável que os próximos acessos sejam acedidos de seguida. A este método chama-se paginação por antecipação (prefetching).
Já que falámos de bits de controlo, vamos referir três de entre eles que serão usados neste trabalho e que se encontram em cada entrada da Tabela de Páginas:
- V – Valid bit – Quando V=1 o endereço é válido para a tradução em página física. Se V=0 a página encontra-se no Pagefile.
- A – Page Accessed – Este bit tem por função determinar se a página foi acedida, informação que o SO vai utilizar na política de substituição de páginas que veremos a seguir. Se A=1 foi acedida, se A=0 não
- D – Page Dirty – Este bit indica ao SO se esta página foi acedida em escrita e portanto se algum dos seus elementos foi alterado. Se D=1 algum endereço pertencente à Página foi alterado se D=0 não.
Há vários bits de controlo mais em cada entrada da Tabela de Páginas, que referem outras características das mesmas, fundamentalmente questões de segurança:
- R se for só de leitura ou escrita e leitura.
- U conforme for acessível no modo utilizador ou no modo núcleo.
- E conforme o modo de escrita for write through ou write back.
- CE conforme o conteúdo for ou não colocável em cache (cacheable).
- P conforme se tratar de uma página pequena ou grande (só usado no diretório de nível 1).
- C se esta página for ou não removível da TLB nas situações em que a comutação de processos der lugar à anulação de todos os registos da TLB.
Não iremos agora abordar estes últimos bits de controlo. Eles têm significados diferentes conforme o nível da tabela onde se encontram: se estiverem nas entradas dos diretórios de tabelas, referem-se às propriedades das páginas filhas; se estiverem nas entradas da tabela de páginas, referem-se às propriedades da página física.
Ainda restam alguns bits livres (para uma entrada de 32 bits por exemplo) que serão utilizados em implementações mais rigorosas do algoritmo de substituição LRU, por exemplo.
Adiante.
Quando um pedido da UCP não encontra o dado pretendido na memória física, o bit V está a 0, dá-se uma Page Fault e é desencadeado um acesso ao disco que vai buscar a Página Virtual indexada, colocá-la na memória física e atualizar a Tabela de Páginas.
Um ou mais processos podem ter endereços virtuais coincidentes, pois vão ser traduzidos em endereços físicos diferentes que fazem parte do espaço de endereçamento de cada processo.
Se podem existir, em diferentes processos endereços virtuais iguais, vão existir diversos valores, como correspondentes endereços físicos para a mesma Entrada da Tabela de Páginas (ETP).
É precisamente essa a razão por que cada processo tem uma Tabela de Páginas (TP), isto é, a Tabela de Páginas faz parte do contexto do processo, devendo por isso estar localizada no seu espaço de endereçamento.
E como encontramos a Tabela de Páginas nesse espaço, isto é, como é que o SO, com base num endereço virtual, endereça a mesma?
Para esse fim existem dois registadores na UCP que têm por função guardar dois valores que para isso contribuem:
- O endereço do limite inferior ou da Base da Tabela de Páginas (BTP) e
- O seu tamanho ou Limite da Tabela de Páginas (LTP).
Sempre que a UCP é retirada a um processo estes registadores fazem parte do contexto desse processo e são guardados, em conjunto com todos os outros, na pilha do núcleo do SO criada para esse efeito, como atrás foi mencionado.
Quando a UCP lê um endereço virtual, soma o valor dos 20 bits de maior ordem desse endereço ao valor da Base de Tabela de Páginas e terá como resultado a Entrada de Tabela de Páginas pretendida.
É fácil de entender se tivermos percebido que os 20 bits de maior ordem de um endereço virtual constituem o deslocamento da Entrada de Tabela de Páginas dentro da mesma. Se for 0, corresponderá à base de Tabela de Páginas ou à primeira Entrada de Tabela de Páginas. Se for 1, corresponderá à segunda entrada de Tabela de Páginas. Se for 1.048.576 corresponderá à última entrada de Tabela de Páginas.
Neste momento já concluímos que afinal existem em memória tantas Tabelas de Páginas quantos os processos que estão em curso e que as Tabelas de Páginas têm mais de 20 bits por entrada, devido aos bits de controlo. Vamos admitir que a dimensão de cada linha num processador de 32 bits será de 32 bits.
Então a dimensão das Tabelas de Páginas aumenta consideravelmente para cerca dos 4,2 MB. Se estiverem em curso 50 processos, o espaço ocupado pelas Tabelas de Páginas será cerca de 210 MB, o que já é significativo e dá para alocar muitas páginas referentes aos processos em curso, aumentando a sua performance. Não esqueçamos que para um processador de 32 bits o espaço de memória endereçável é de 4 GB, reservando o SO para si, entre 1 e 2 GB desse espaço.
Para reduzir este espaço foi criado o procedimento de Tabelas de Páginas Multinível, isto é, vários níveis de Tabelas de Páginas em que cada uma endereça a localização da Tabela de Páginas de nível seguinte (em disco ou em memória conforme o valor de V) e só o último nível endereça a página física correspondente.
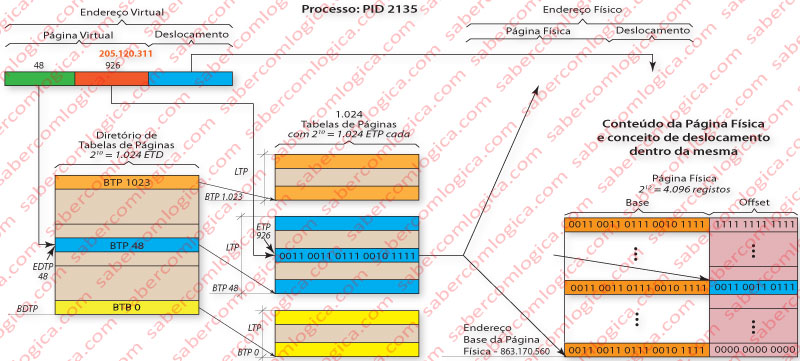
Para melhor entendermos o que são Tabelas de Páginas Multinível, vamos acompanhar pela Figura 3, onde ilustramos o mapeamento do endereço virtual 0000 1100 0011 1001 1110 0011 0011 0111 ou 205.120.311 em decimal ao endereço físico 0011 0011 0111 0010 1111 0011 0011 0111 ou 863.171.383 em decimal, através de uma Tabela de Páginas de 2 níveis. Nesta situação, os 20 bits de maior nível são divididos em dois conjuntos de 10 bits cada.
- O conjunto dos 10 bits de maior ordem passa a referir a entrada de uma Tabela que contém exclusivamente Tabelas de Páginas, pelo que se vai chamar Diretório de Tabela de Páginas (DTP) de Nível 1 (aliás o único nível de diretório no nosso caso). O valor desses 10 primeiros bits, 0000 1100 00 ou 48 em decimal, refere a Entrada do Diretório de Tabela de Páginas (EDTP) onde está descrito o endereço (em memória ou em disco, conforme V) da Base da Tabela de Páginas (BTP) que nos interessa e que se deverá carregar em memória caso ainda não o esteja.
- O segundo conjunto de 10 bits refere-se a entradas de uma Tabela que contém endereços de Páginas Físicas (em memória ou em disco, conforme V) que por isso se chamam Tabelas de Páginas (TP). O valor do segundo conjunto de 10 bits, 11 1001 1110 ou 926 em decimal, refere a Entrada da Tabela de Páginas (ETP) selecionada de entre 1,024 pelo valor contido na EDTP indicada pelos 10 primeiros bits, onde se encontra o endereço base da Página Física (físico ou em disco, conforme V), que nos interessa encontrar.
Finalmente ao endereço de base da página física assim encontrado, 0011 0011 0111 0010 1111 junta-se o deslocamento indicado pelos 12 bits de menor ordem do endereço virtual, 0011 0011 0111 obtendo-se assim o endereço físico pretendido
0011 0011 0111 0010 1111 0011 0011 0111
ou 863.171.383 em decimal.
Com este método o Diretório de Tabela de Páginas de 1º nível será aquele que deverá estar sempre em memória. Das Tabelas de Páginas de 2º nível só serão chamadas à memória aquelas que forem referenciadas pelo Diretório de Tabela de Páginas após cada consulta.
A dimensão do Diretório de Tabelas de Páginas, admitindo 32 bits por linha, será de 210 x 32 /8 = 4.096 Bytes ou 4 KB. Se juntarmos a Tabela de Páginas referida, também com 4 KB teremos um total de 8 KB de memória por processo, o que é significativamente inferior quando comparado com os anteriores 4,2 MB. Se estiverem em curso 50 processos, o espaço ocupado pelas Tabelas de Páginas será cerca de 400 KB por oposição com os anteriores 210 MB.
Desta forma reduz-se substancialmente a memória gasta com as Tabelas de Páginas. Mas este procedimento afeta a performance do sistema, obrigando a consultas constantes ao disco. O ideal seria termos uma cache de páginas, tal como temos uma cache de dados ou instruções. E temos mesmo. Chama-se TLB (Translation Lookaside Buffer) e a sua função é guardar as entradas da Tabela de Páginas com referência a páginas físicas que foram consultadas mais recentemente.
TLB (Translation Lookaside Buffer)
A TLB é uma cache que dispõe de poucas entradas, na ordem das dezenas e que, desde a era dos Pentium, se encontra dividida em duas, uma para entradas de páginas de dados e outra para entradas de páginas de instruções. Esta divisão certamente pretendeu preservar o acesso simultâneo a dados e instruções, devido à também separação das caches de nível 1. O número reduzido de entradas tem em conta que cada entrada da TLB, porque representa uma Página física, representa 4KB de endereços.
Sempre que é feita uma tradução de endereço virtual, é em primeiro lugar consultada a TLB. Em caso de TLB miss é executado o processo já descrito de tradução do endereço, sendo no final registada uma entrada em TLB. Como o que se pretende com a TLB é ter em cache um registo das últimas páginas acedidas, a política de escrita em cache bem como a de substituição (quando se encontra cheia) é a de FIFO (First In First Out).
Uma entrada de TLB pode ou não incluir o número do processo (PID – Process ID) associado à tradução registada. A inclusão ou não do PID conduz a políticas diferentes de tratamento dos registos na TLB:
- Caso a entrada de TLB não inclua o PID, de cada vez que é mudado o contexto de execução na UCP (muda o processo em execução) as entradas presentes na TLB são anuladas. Para esta situação a política de substituição de entradas mais lógica é a FIFO. Esta situação já não é praticamente adotada atualmente, onde a dimensão das TLB aumentou significativamente e a sua importância na performance é reconhecida e cada vez mais estudada.
- Quando a entrada da TLB inclui o PID a substituição das entradas é feita pelo método de substituição escolhido e as entradas não são anuladas na mudança de contexto de processo, mantendo-se em convivência entradas de diversos processos. Para esta situação a política de substituição mais lógica já não será a FIFO, pois podem existir páginas mais antigas que são as mais usadas, referentes por exemplo a processos que acedem sempre as mesmas páginas de cada vez que estão em execução. A política de substituição mais lógica neste caso será a LRU (Least Recently Used – Menos Usado Recentemente), de que já falámos quando abordámos a política de substituição de blocos da Memória Cache.
Põe-se agora uma questão. Tínhamos falado, já uns Capítulos atrás, da memória cache, intercalada entre a UCP e a memória principal. Então e agora, com esta história de traduções e endereços virtuais, onde se vai encaixar esta TLB? Antes ou depois da cache?
Podem-se encarar as duas possibilidades:
- O acesso à cache é feito em primeiro e só em caso de cache miss se passa à tradução do endereço para se poder consultar a memória. Neste caso os endereços em cache têm que ser endereços virtuais.
- A tradução é feita em primeiro lugar e só depois é feito o acesso à cache. Neste caso os endereços em cache serão endereços físicos.
A primeira hipótese é evidentemente a melhor em termos de performance, mas admite a possibilidade de poderem existir vários endereços virtuais iguais com correspondência em endereços físicos diferentes (processos diferentes), o que só por si invalida (ou complica) a solução. Embora sujeita a piores performances, a segunda solução é a que se torna menos complexa e menos geradora de erros, pelo que também é a adotada por processadores de última geração.
A TLB tem merecido uma atenção muito especial por parte dos fabricantes de UCP e de muitos investigadores, devido à sua grande influência na performance da UCP. Já são utilizadas em processadores multinucleares, TLB dedicadas de vários níveis. Estão a surgir presentemente, vários estudos que apontam para TLB de vários níveis, em que o nível superior seja partilhado por todos os núcleos em UCP multinucleares e inclusivo, como serão exemplo as SLL TLB (Shared Last Level TLB in Chip Multiprocessors) ou as Synergistic TLB for High Performance Address Translation in Chip Multiprocessors.
Estas propostas fundamentam-se no facto de em UCP multinucleares e multitarefa, as várias tarefas de um mesmo processo em execução simultânea estarem a correr em vários núcleos separados e todas irem encontrar TLB miss devido à inconsistência de caches. De acordo com a solução proposta, TLB de nível superior partilhadas, garantiriam essa consistência, sendo que então a TLB miss só se registaria para a primeira tarefa a consultar essa página.
Políticas de Substituição de Páginas
Como já vimos, o código e os dados são paginados e colocados num ficheiro de trocas, o Pagefile. Daí, são transportados para a memória conforme as necessidades do processo, ou por antecipação, se o algoritmo de execução assim o previr. Mas o espaço em memória é muito limitado e o número de processos em execução pode ser muito grande. Como tal, o número de páginas a colocar em memória por processo, é muito limitado.
Assim sendo, por vezes, para que uma página nova entre na memória é necessário retirar uma outra que já lá está. Quando e como, é o que vamos ver.
O SO guarda uma tabela das páginas livres e outra das páginas modificadas livres. Quando é necessário substituir qualquer página é a estas que o SO recorre para fazer a troca, pois estas já estão dispensadas do serviço.
E quando? Vamos ver um exemplo.
As casas de uma aldeia são abastecidas por um depósitos de água. Todas têm um depósito porque, como a água é um recurso escasso e importante, têm que ir trocando o abastecimento entre si. Para isso definiram no depósito um limite mínimo de segurança para a quantidade de água a partir da qual começavam a encher, e chamaram-lhe a marca de água baixa.
Definiram também um limite máximo de enchimento do depósito que, uma vez atingido o abastecimento era fechado, para que os outros pudessem usufruir da água para os seus depósitos. Chamaram-lhe marca de água alta.
E assim, o tal recurso escasso que era a água, ia dando para todos os depósitos.
Pois é. O nosso amigo SO também tem um recurso escasso para gerir, que é o tempo que passa em conversas com o disco e o tempo que passa a verificar quais as páginas que podem ser libertadas de serviço na memória.
Por isso, criou o tal depósito de páginas livres e criou para o mesmo os tais dois níveis, a que chamou Low Water Mark e High Water Mark, os termos em Inglês, a língua materna do SO, para os mesmos termos que os Portugas arranjaram para os níveis dos depósitos das casas deles.
E nós vamos continuar com o SO, a falar a nossa língua.
Temos assim definido quando é que se faz a substituição. Quando o depósito atingir a marca de água baixa, o SO vai fazer uma visitinha aos habitantes da tabela de páginas e escolher dentre eles quais devem abandonar a casa para dar lugar aos novos. E vai escolher tantos quantos os necessários para que o depósito atinja a marca de água alta.
Fica assim reposto o abastecimento de páginas livres à aldeia das trocas. Vamos agora entender como é que o SO faz a escolha de quem devia abandonar a casa. Dispõe de vários processos para decidir.
O mais fácil é o FIFO (First In First Out) ou PEPS (Primeiro a Entrar Primeiro a Sair). É correto, pois quem já usufruiu mais tempo da casa é que deve dar lugar aos novos, mas pode ser mau para a gestão da casa, pois por vezes quem lá está há mais tempo é quem lá faz mais falta porque é chamado a serviço mais vezes. Frequentemente têm que os ir buscar logo depois de os mandarem embora e assim têm dois trabalhos para tudo ficar na mesma.
O mais eficiente, porque se preocupa primeiro com a boa gestão da casa é o LRU (Least Recently Used) ou MUR (Menos Usado Recentemente). Por este método o SO escolhe sempre os que foram menos chamados a serviço recentemente, portanto os menos úteis aos serviço da casa. E como é que ele sabe quem são esses? Pela idade. Cada habitante, tem um bit que, de cada vez que é utilizado é colocado a zero, fica jovem de novo. É o bit de Acesso ou Access Bit (A).
Periodicamente, o SO passa pela casa e coloca todos os bits que estão a 0 em 1, incrementando um conjunto de bits que definem a idade da entrada nesses e naqueles que já estavam a 1.
Logo que esse habitante é chamado a serviço, o tal bit volta a 0 e a idade também. Fica jovem de novo.
Quando se trata de escolher quem sai, o SO vai aos bits da idade e começa pelos mais idosos, que correspondem aos menos usados.
O NRU (Not Recently Used) ou NUR (Não Usado Recentemente) é uma variação simplificada do anterior em que só o bit de acesso é utilizado. Quando o SO vai escolher , olha para os que têm o tal bit a 1 e escolhe a eito.
Há mais variações para o SO escolher, mas dispensamo-nos de continuar com a descrição, que correrá o risco de se tornar cansativa por tão exaustiva. Estas já chegam para poder escolher entre a facilidade e a eficiência, sabendo que a facilidade tem menos custos de SO e mais custos de substituições e que a eficiência tem mais custos de SO e menos custos de substituições.