
Intel Nehalem (i7)
Temos estado a analisar a memória virtual para processadores não específicos de 32 bits, mas para que se possa entender corretamente a memória virtual, nada como fazer uma análise com suporte gráfico da tradução de endereços do processador Intel Nehalem i7, um quad Core de última geração a 64 bits, principal aplicação da Arquitetura Nehalem.
O processador i7 dispõe de dois níveis de TLB. O nível 1 de cache TLB é composto por duas TLB separadas para dados e instruções, com 128 entradas para páginas de instruções e 64 entradas para páginas de dados de 4 KB, ambas caches associativas de 4 vias. Estas caches têm latências de 4 ciclos de clock. A cache TLB de nível 2 dispõe de 512 entradas para dados e instruções e é uma cache associativa de 4 vias com latências de 7 ciclos de clock.
O nível 1 da cache TLB dispõe também de mais duas caches separadas para páginas grandes (2 ou 4 MB) respetivamente com 7 entradas para páginas de instruções, totalmente associativa e com 32 entradas para dados, associativa de 4 vias. Na nossa análise vamos considerar exclusivamente as páginas de 4 KB.
Comecemos por analisar a composição das entradas das tabelas de páginas. O processadores i7 da arquitetura Nehalem são processadores de 64 bits, sendo que portanto, o seu espaço de endereço é de 64 bits.
A arquitetura Intel 64, corresponde ao conjunto de instruções Assembly definidas para este processador, só usa os 48 bits de menor ordem.
Tendo 48 bits disponíveis para endereços, os 12 bits de menor ordem correspondem ao deslocamento, uma vez que as páginas são de 4 KB (212). Sobram 36 bits para o número da página.
Teríamos assim uma tabela de páginas com 236≈68 mil milhões de entradas. Fácil é de entender a opção por uma tabela multinível, concretamente de 4 níveis, como se pode ver na Figura 1 nota 18, correspondendo cada nível a 9 bits do endereço virtual.
Assim, cada diretório de tabelas terá 512 entradas (29), o que a 64 bits por entrada, representa uma dimensão de 4 KB, o que é muito razoável, permitindo assim manter em memória não só o diretório de tabelas de páginas de nível 1 (permanente em memória), como os diretórios de tabelas de páginas de nível 2 e 3 e a tabela de páginas que vão sendo consultadas.
Entrada de Tabela de Páginas
Se o bit de validade for 1, isto é, se a entrada se referir a uma página em memória, uma entrada de tabela de páginas tem o seguinte significado:
Os 12 bits de menor ordem referem-se a alguns sinais de controlo necessários à segurança, estado e outras propriedades da página referenciada no endereço:
- R se for só de leitura ou escrita e leitura, U conforme for acessível no modo utilizador ou no modo núcleo, E conforme o modo de escrita for write through ou write back, CE conforme o conteúdo for ou não colocável em cache (cacheable), P conforme se tratar de uma página pequena ou grande (só usado no diretório de nível 1), C se esta página for ou não removível de TLB nas situações em que a comutação de processos der lugar à anulação de todos os registos da TLB, são alguns desses bits de controlo que não iremos agora abordar. Estes bits têm significados diferentes conforme o nível da tabela onde se encontram: se estiverem nas entradas dos diretórios de tabelas, referem-se às propriedades das páginas filhas; se estiverem nas entradas da tabela de páginas, referem-se às propriedades da página física.
- M é o bit de modificação ou dirty bit, utilizado para assinalar uma página que sofreu modificações nalgum dos seus elementos. Só é utilizado na Tabela de Páginas, não o sendo nos diretórios de tabelas.
- A é o bit de acesso, ativado em escritas e leituras e desativado periodicamente pelo SO, indica se uma página foi ou não recentemente acedida, permitindo uma forma menos elaborada de aplicação do método de substituição de páginas LRU.
- V é o bit de validade, que indica se a página se encontra em memória física ou em disco (em swap ou pagefile).
M, A e V são bits de que já falámos ou iremos falar, pois intervêm muito no processo de gestão da memória.
Os 40 bits desde o 12 ao 51 referem-se ao endereço base da página física (acrescentado com 12 zeros), nas entradas da Tabela de Páginas ou ao endereço da tabela de páginas de nível superior, se for uma entrada de um diretório de tabelas de página.
Os restantes bits até ao 63 estão livres, assim como os 3 bits antes do início do endereço.
Os bits livres serão utilizados em implementações mais rigorosas do algoritmo de substituição LRU, por exemplo.
Se o bit de validade for 0, isto é, se a entrada se referir a uma página em swapfile ou pagefile, então os bits de 1 a 63 incluirão um valor utilizado pelo SO para poder encontrar a página em disco.
Entrada de TLB
Uma entrada de TLB deve conter o endereço base da página virtual e o endereço base da página física. Os endereços base aqui referidos são constituídos pelos 36 (pág. virtual) ou 40 (pág. física) bits de maior ordem do endereço, devendo os últimos 12 ser acrescentados a zeros para termos o endereço efetivo da base. O endereço base da página virtual é aquele que é comparado e o endereço base da página física é o que é fornecido em caso de acerto.
A entrada de TLB deve ter o PID (número de identificação do processo) por forma a que possam conviver simultaneamente traduções de páginas de vários processos na TLB.
A existência de hiper-threading , criando a partir de um processo dois novos processos virtuais sugere como necessário a existência deste identificador, o PID Virtual, uma vez que ambos estes processos vão partilhar os recursos do processo físico que lhes deu origem e é necessário identificar a qual deles a tradução diz respeito.
Todos os bits de controlo que atrás referimos devem estar incluídos na entrada da TLB, uma vez que em caso de acerto a entrada respetiva da Tabela de Páginas não é lida e a informação na mesma contida é necessária. Tal como se de uma leitura da tabela de páginas se tratasse.
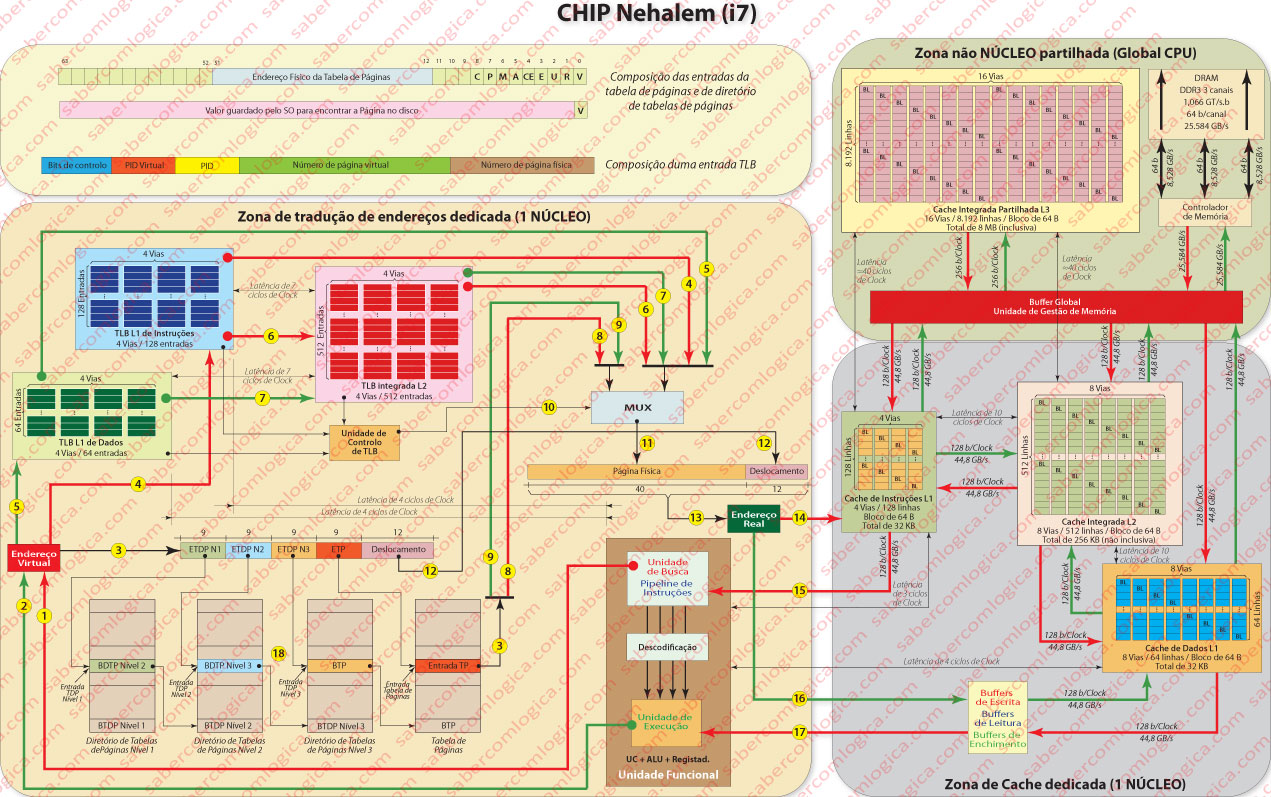
Processo de procura
Vamos então tentar seguir o percurso de uma instrução no i7, analisando o caso de um núcleo só.
A Unidade de Controlo do núcleo da UCP envia um endereço para leitura de uma instrução, através da linha indicada na Figura 1 com a nota 1. Esse pedido é bifurcado para tratamento em paralelo pela TLB e pela tradução de páginas em tabelas, conforme as linhas representadas pela Figura 1 nota 3, percurso que atravessa as tabelas de páginas e Figura 1 nota 4, percurso que segue para as TLB.
Atendendo a que qualquer dos níveis de TLB tem latências (4 clocks para o L1 mais 7 clocks para o L2, o tratamento é feito em paralelo para que em caso de TLB miss o processo não tenha que ser reiniciado.
Seguindo o percurso do TLB, em caso de TLB L1 miss, a instrução prossegue para a TLB L2 (Figura 1 nota 6), sendo que, tanto os resultados da TLB L1 (Figura 1 nota 4) como da TLB 2 (Figura 1 nota 6), ligam diretamente a um MUX cuja função é selecionar um sinal entre dois, um proveniente dos TLB e outro proveniente das Tabelas de páginas.
Para esse efeito a Unidade de Controlo do TLB emite um sinal (Figura 1 nota 10), conforme essa indicação lhe seja transmitida pelo TLB que teve um acerto, que permite a seleção da entrada proveniente dos TLB. Em caso de TLB miss esse sinal (um bit) não é ativado e será feita a seleção da entrada proveniente das tabelas de páginas (Figura 1 nota 8).
A seleção do MUX (Figura 1 nota 11) corresponde ao número da página física que então é junto com o deslocamento (Figura 1-4 nota 12) para formar o endereço real (Figura 1 nota 13).
É este endereço que é enviado à cache de instruções desse núcleo (Figura 1 nota 14), seguindo agora o processo já descrito no capítulo da Memória Cache, devolvendo à Unidade de Controlo o conteúdo da Instrução solicitada (Figura 1 nota 15).
Depois de descodificada esta instrução e caso contenha um endereço de memória, porque é um endereço virtual vai seguir um processo idêntico ao descrito, mas agora para os dados.
Esse processo é indicado pelas linhas a verde com as indicações Figura 1 notas 1, 5 e 7, conforme o resultado provém do TLB L1 ou do TLB L2 e a indicação Figura 1 nota 9 quando provêm das tabelas de páginas.
Segue o mesmo método já descrito e indicado para a formação do endereço real que é enviado aos buffers de entrada da cache L1 de dados (Figura 1 nota 16), sendo o conteúdo desse endereço devolvido à Unidade de Execução da UCP (Figura 1 nota 17).
A descrição destes percursos, com a indicação das latências em cada um, permite verificar os tempos de busca de uma instrução e de escrita ou leitura de um dado num endereço.
Podemos verificar ambas as mais otimista ou pessimista situações:
- Um Cache hit nas TLB L1 e Cache L1 de instruções e de dados.
- Um Cache miss nas TLB L1 e Cache L1 de instruções e de dados e nas TLB L2 e Caches L2 e L3 sendo necessário ler novas páginas do disco e valores da memória principal tanto para as instruções como para os dados.
Mesmo atendendo a que em elevada percentagem se vai verificar um cache hit para as instruções e os dados tanto na TLB 1 como na Cache L1, teremos latências médias da ordem dos 15 a 20 clocks. E estamos a ser verdadeiramente otimistas pois estamos a considerar vários cache hits acumulados.
Torna-se assim evidente a necessidade de explorar ao máximo a execução das instruções em pipeline, fora de ordem e outras formas que possibilitem ter o maior número possível de instruções em execução em simultâneo, de forma a nos conseguirmos aproximar do objetivo de execução de uma instrução por ciclo de clock.
É aí que reside um dos grandes investimentos atuais em performance. Não na frequência da UCP mas no paralelismo de execução, tanto ao nível interno de cada núcleo através do pipelining (como vimos no Capítulo sobre a UCP) mas também na execução de várias instruções de um mesmo programa (tarefas) em diferentes núcleos de uma mesma UCP multinucleada.
É aqui que os programadores têm um papel muito importante, pelo que, quanto melhor conhecerem a forma de funcionamento da UCP e das ferramentas que são disponibilizadas para programação concorrente, mais eficientes podem ser.